發現和糾正托管應用程序中的內存問題可能十分困難。 內存問題的表現形式多種多樣。例如,您會觀 察到,您的應用程序的內存使用量在不斷增加,最終導致“內存不足”(OOM) 異常(您的應用 程序甚至可能在有大量可用物理內存的情況下引發內存不足異常)。但以下任何一種情況均表明內存可能 出現了問題:
引發 OutOfMemoryException(內存不足異常)。
進程占用了太多內存,您無法確定任何明顯 的原因。
似乎垃圾收集功能並沒有快速清理對象。
托管堆碎片過多。
應用程序過 度占用 CPU。
此專欄討論研究過程,並向您展示如何收集您所需的數據,以確定您所面臨的應用 程序中的內存問題的類型。此專欄並不包括如何實際修復您所發現的問題,但可以為您提供對問題根源的 深入分析。
我們首先簡要介紹一下可用於研究托管內存問題的最實用的性能計數器。然後我們會 介紹研究過程中常用的工具,接著介紹一系列常見的托管內存問題以及如何研究這些問題。
但在 開始之前,您首先應熟悉一些基本概念:
Microsoft® .NET Framework 中的垃圾收集。有關 詳細信息,請參閱以下兩個博客記錄:blogs.msdn.com/156626.aspx 和 blogs.msdn.com/234273.aspx.
Windows® 中的虛擬內存的工作原理。這包括保留內存和分配 內存的概念。
使用 Windows 調試程序(WinDbg 和 CDB)。
使用的工具
在開始之 前,我們應該花點時間討論一下在診斷與內存相關的問題時通常使用的一些工具。
性能計數器 通 常,您會希望首先了解性能計數器。通過這些計數器,您可以收集必要的數據以確定出現問題的准確位置 。雖然有些其他工具也值得關注,但是最有用的性能計數器是 .NET Framework 上介紹的性能計數器。
調試程序 在這裡我們將使用 WinDbg,該工具隨 Windows 調試工具提供。SOS.dll 中提供的 Son of Strike 擴展 (SOS),用於調試 WinDbg 中的托管代碼。在啟動了調試程序並將其附加到托管進程(或 加載故障轉儲)後,您可以通過鍵入以下代碼加載 SOS.dll:
.loadby sos mscorwks
如 果您正在調試的應用程序使用的是不同版本的 mscorwks.dll,則該命令無法執行,那麼應找到該應用程 序使用的 mscorwks.dll 版本的 SOS.dll,然後運行以下命令:
.load <path_to_sos>\sos.dll
SOS.dll 隨 .NET Framework 安裝在 %windir%\microsoft.net\framework\<.NET 版本>目錄下。 SOS.dll 擴展提供了大量用於檢查托管堆的有用命令。有關所有這些命令的文檔,請參閱 SOS 調試擴展 (SOS.dll)。
Windows 任務管理器 Taskmgr.exe 可方便地發現超出預期的內存使用情況,並可檢查在一段時間內一 些簡單的進程指標的趨勢。注意,taskmgr 中有兩個經常被誤解的指標:Mem Usage (內存使用)和 VM Size(虛擬內存大小)。Mem Usage 表示的是進程工作集(就像進程\工作集性能計數器)。它並不表示 所使用的字節數。VM Size 反映的是供進程使用的字節數(就像進程\專用字節數性能計數器)。VM Size 可提供關於您是否面臨內存洩漏問題(如果您的應用程序存在洩漏,則 VM Size 會隨時間增加)第一線 索。
內存轉儲 在此專欄中介紹的大多數研究技巧都依賴於內存轉儲。使用調試程序的方法有兩種 — 您可以將其附加到正在運行的進程,或利用它來分析故障轉儲。第一種方法提供了直接的視圖,使您可以 了解應用程序在運行時的狀況,但該技巧並不總是可行的。
內存轉儲具有可從實際問題研究階段 中分析出數據收集階段的優點。假設您希望診斷一台實際工作的服務器上的問題,則使用不同的機器脫機 分析內存轉儲可能更容易。
調試程序中的 .dump /ma dmpfile.dmp 命令可用於創建全內存轉儲。 在研究內存問題時確保您始終捕獲全轉儲,因為小型轉儲並不包含您所需的全部信息。
ADPlus 工具(包含在 Windows 調試工具中)對於收集故障轉儲有很大幫助。有關詳細信息,請參閱 從 2005 年 3 月起 John Robbins 的 Bugslayer 專欄。
在本專欄中,我們將假定轉儲文件始終 加載在調試程序中(故障轉儲可使用 File | Open crash dump 命令加載),或者調試程序始終附加到進 程,並且在斷點處停止執行。
GC 性能計數器
每項研究的第一步是收集相關數據並對可能 存在問題的位置做出假設。通常首先從性能計數器開始。通過 .NET Framework 性能控制台可使用計數器 ,這些計數器提供了關於垃圾收集器 (GC) 和垃圾收集流程的有用信息。請注意,.NET 內存性能計數器 只有在收集時才更新,而不是根據性能監視器應用程序中使用的采樣率進行更新。
您應該首先檢 查 % Time in GC(花在 GC 上的時間的百分比)。它表示自從上次收集結束後 % Time in GC。如果您發 現此數值非常高(假設為 50% 或更高),那麼您應該檢查一下托管堆內部發生了哪些情況。如果 % Time in GC 沒有超過 10%,那麼通常就不必花時間來嘗試減少 GC 用在收集上的時間了,因為這樣做帶來的益 處微乎其微。
如果您認為您的應用程序在執行垃圾收集上花費的時間過多,那麼下一個要檢查的 性能計數器就是 Allocated Bytes/sec(每秒分配字節數)。該計數器顯示了分配速率。不過,該計數器 在分配速率非常低的情況下,並不十分准確。如果采樣頻率高於收集頻率,該計數器可能顯示為 0 字節/ 秒,因為該計數器只有在每次收集開始的時候進行更新。這並不意味著沒有進行分配操作,只是由於在該 時間間隔內沒有收集發生,因此計數器沒有得到更新而已。既然了解到垃圾收集所花費的時間是一個重要 的考慮因素,我們將在稍後更詳細地了解 % Time in GC。
如果您認為您要收集大量大型對象 (85,000 字節或更大),則需要檢查大型對象堆 (LOH) 的大小。它與 Allocated Bytes/sec 同時更新 。
高分配速率會導致大量收集工作,因此可能 % Time in GC 會比較高。能否減輕這一現象的一 個因素為對象通常是否很早就死去,只因為它們通常會在第 0 級收集過程中被收集。要確定對象生命周 期對收集有何影響,可檢查各級收集的性能計數器:# Gen 0 Collections(第 0 級收集次數)、# Gen 1 Collections(第 1 級收集次數)、# Gen 2 Collections(第 2 級收集次數)。這些性能計數器顯示 自進程啟動後對各級對象進行收集的次數。第 0 級和第 1 級收集通常開銷很低,因此它們不會對應用程 序的性能有很大影響。而第 2 級收集器開銷非常大。
首要原則是,各級收集之間合理的比值是每 進行 10 次第 1 級收集,進行一次第 2 級收集。如果您發現在垃圾收集上花費了大量時間,那可能是由 於第 2 級收集的頻率過高造成的。您應該檢查上面提到的比值,確保第 2 級收集與第 1 級收集的次數 比值不是太高。
您可能會發現 % Time in GC 很高,但分配速率並不高。如果您分配的許多對象 能夠在垃圾收集後保留下來並被提升到下一級,則會出現這種情況。提升計數器 — 從第 0 級提升 的內存 (Promoted Memory from Gen 0) 和從第 1 級提升的內存 (Promoted Memory from Gen 1) — 可以告訴您提升速率是否存在問題。我們希望避免從第 1 級提升的速率太高。這是因為您可能 有大量對象存在時間較長,足以提升到第 2 級,但存在的時間不足以使其保留在第 2 級中。一旦提升到 第 2 級,這些對象的收集開銷就要比它們在第 1 級中死去要大。(這種現象被稱為中年危機。有關詳細 信息,請參閱 blogs.msdn.com/41281.aspx。)CLR 分析器 (CLR Profiler) 可幫您了解哪些對象存在時 間過長。
第 1 級和第 2 級堆大小的數值較高往往與提升速率計數器中的數值較高相關。您可以 使用第 1 級堆大小和第 2 級堆大小來檢查 GC 堆的大小。有一個第 0 級堆大小計數器,但它並不用於 衡量第 0 級的大小。它用於表示第 0 級的空間預算 — 意味著在觸發下一次第 0 級收集之前,在 第 0 級中您可以分配的字節數。
如果您使用了的大量需要終結的對象 — 例如,依賴於 COM 組件進行一些處理的對象 — 在這種情形下,您可以看一下 Promoted Finalization-Memory from Gen 0(從第 0 級提升的終結內存)計數器。該計數器會告訴您由於使用內存的對象需要被添加到 終結隊列中而無法立即對其進行收集、由此導致無法被重復使用的內存數量。IDisposable 和 C# 及 Visual Basic® 中的 using 語句可幫助減少在終結隊列中結束的對象數量,從而降低相關的開銷。
使用 # Total committed Bytes(提供的字節總數)和 # Total reserved Bytes(保留的字節總數) 可找到關於堆大小的詳細數據。這些計數器分別表示當前在 GC 堆上提供內存和保留內存的總數。(提供 的字節總數值略微大於實際的第 0 級堆大小 + 第 1 級堆大小 + 第 2 級堆大小 + 大型對象堆大小。) 當 GC 分配一個新堆段時,內存將保留給該段,只有在需要時才提供內存。因此保留字節的總數可以比提 供的字節總數大。
同樣應該檢查一下應用程序是否引發了太多次收集。# Induced GC(引發的 GC 的數目)計數器可以告訴您自進程啟動以來引發了多少次收集。一般而言,不建議您引發多次 GC 收集。 在大多數情況下,如果 # Induced GC 的數值較高,您應該將其視為 Bug。在大多數情況下人們引發 GC 是希望削減堆的大小,但這並非理想的選擇。您應該了解您的堆大小為何增加。
Windows 性能計 數器
到目前為止,我們已經了解了一些最實用的 .NET 內存計數器。但您不應忽略其他計數器的 價值。有很多種 Windows 性能計數器(也可通過 perfmon.exe 查看)為研究內存問題提供了有用的信息 。
Memory(內存)類別下面所列的 Available Bytes(可用字節)計數器報告了可用的物理內存 。它可明確地顯示您的物理內存是否過低。如果機器的物理內存過低,會發生分頁或者很快會發生分頁。 該數據對於診斷 OOM 問題非常有用。
% Committed Bytes in Use(正在使用的字節百分比)計數 器(同樣位於 Memory 類別下)提供了內存使用量與內存總量的比值。如果此值非常高(假設超過 90%) ,您應該開始檢查提供內存故障。這明顯表明系統內存緊張。
Process(進程)類別下的 Private Bytes(專用字節數)計數器表示被使用且無法與其他進程共享的內存數量。如果您希望了解您的進程使 用了多少內存,您應該監視此計數器。如果您遇到了內存洩漏問題,專用字節數會隨時間增加。該計數器 還可明顯地表明了您的應用程序對整個系統的影響 — 使用大量專用字節會對機器有很大影響,因 為內存無法與其他進程共享。這在某些情形下至關重要,如終端服務,在這種情形下您需要使用戶會話之 間共享的內存量達到最大。
確認托管進程中的 OOM 異常
性能計數器可向您明確表示您是 否正在面臨內存問題。但在大多數情況下,只有在您的應用程序中出現內存不足異常的情況下才能檢測到 內存問題。因此您需要了解您實際上是否正在發生由托管代碼引起的 OOM 異常。
在您加載了 SOS.dll 後,可在調試程序中鍵入以下命令:
!pe
這是 !PrintException 的縮寫形式。 它將輸出線程(如果有)上最後的托管異常,無需參數。圖 1 中顯示了 OOM 托管異常的一個示例。
Figure1OutOfMemoryException for WinDbg
0:010>!pe Exception object: 39594518 Exception type: System.OutOfMemoryException Message: <none> InnerException: <none> StackTrace (generated): SP IP Function 1A7BF848 789336E9 System.MulticastDelegate.CombineImpl( System.Delegate) 1A7BF87C 78930AC4 System.Delegate.Combine(System.Delegate, System.Delegate) ... [omitted] 1A7BFA9C 789B92A3 System.Threading._IOCompletionCallback. PerformIOCompletionCallback(UInt32, UInt32, System.Threading.NativeOverlapped*) StackTraceString: <none> HResult: 8007000e
如果當前線程上沒有托管異常,您就不必了解 OOM 來自哪個線程了。要了 解這一點,請在調試程序中鍵入以下代碼:
~*kb
在這裡,kb 是 Display Stack Backtrace(顯示堆棧回溯)的縮寫。它列出了所有線程及其堆棧的調用(參見圖 2)。在輸出中,查找 存在異常調用的線程和堆棧。最簡便的方法就是查找 mscorwks::RaiseTheException。
Figure2Output of Display Stack Backtrace
28adf5e4 7c822124 77e6baa8 000000c0 00000000 ntdll!KiFastSystemCallRet 28adf5e8 77e6baa8 000000c0 00000000 00000000 ntdll!NtWaitForSingleObjec t+0xc 28adf658 77e6ba12 000000c0 ffffffff 00000000 kernel32!WaitForSingleObjec tEx+0xac 28adf66c 791f2dde 000000c0 ffffffff 791f2d8e kernel32!WaitForSingleObjec t+0x12 ... 28adf704 7c82ee84 28adfa9c 28adfbb8 28adf7bc ntdll!ExecuteHandler2+0x26 28adf7ac 7c82eda4 28add000 28adf7bc 00010007 ntdll!ExecuteHandler+0x24 28adfa8c 77e55dea 28adfa9c 25796140 e0434f4d ntdll!RtlRaiseException+0x3d 28adfaec 7924511d e0434f4d 00000001 00000000 kernel32!RaiseException+0x53 28adfb44 7923918f 5b61f2b4 00000000 5b61f2b4 mscorwks!RaiseTheException+0xa0 ...
mscorwks 中的 RaiseTheException 函數的參數是托管的異常對象。您可以使用 !pe 對其 進行轉儲。此外 !pe 還有一個 –nested 選項,將對除頂級異常之外的所有嵌套異常進行轉儲。
找出導致 OOM 的線程的另一種方法是使用 SOS 的 !threads 命令。所顯示的表的最後一欄將包含各 個線程最近引發的托管異常。
如果您使用這些技巧沒有找到 OOM 異常,則沒有托管 OOM,您所面 臨的異常由本機代碼引發。在這種情況下,您需要關注您的應用程序使用的本機代碼(關於此問題的討論 超出了本專欄的范圍)。
確定導致 OOM 異常的原因
在您確認了這是 OOM 異常之後,您應 該檢查導致 OOM 的原因。在兩種情形下會出現托管 OOM — 進程耗盡了虛擬內存,或者沒有足夠的 物理內存可提供。
GC 需要為其段分配內存。當 GC 決定它需要分配一個新段時,它會調用 VirtualAlloc 以保留空間。如果段沒有連續的足夠大的可用塊,則調用失敗,GC 無法滿足新的內存請求 。
在調試程序中,!address 命令可為您顯示虛擬內存的最大可用區域。輸出將類似於:
0:119>!address -summary ... [omitted] Largest free region: Base 54000000 - Size 03b60000 0:119>? 03b60000 Evaluate expression: 62259200 = 03b60000
如果在 32 位操作系統上進程可使用的最大可用虛擬 內存塊小於 64MB(64 位操作系統上小於 1GB),則耗盡虛擬內存可能會導致 OOM(Out of Memory,內 存不足)。(在 64 位操作系統上,應用程序不大可能耗盡虛擬內存空間。)
如果虛擬內存的碎片過 多,則進程可能會耗盡虛擬空間。通常托管堆不會產生虛擬內存碎片,但也有可能會出現這種情況。例如 ,如果應用程序創建了大量的臨時大型對象,導致 LOH 不斷獲得和釋放虛擬內存段,那麼就有可能出現 這種情況。
!eeheap –gc SOS 命令將為您顯示每個垃圾收集段的起始位置。您可以將其與 !address 的輸出關聯考慮,以確定虛擬內存的碎片是否由托管堆造成。
以下是其他一些可能導致 產生虛擬內存碎片的常見情況。
總是加載和卸載許多小的程序集。
由於 COM 互操作而加 載大量的 COM DLL。
在托管堆中沒有同時加載程序集和 COM DLL。可能導致這一問題的一種常見 情形是,在啟用了“debug”配置標志的情況下對 ASP.NET 站點進行編譯。這會導致每個頁在 其各自的程序集中進行編譯,可能會產生足以引發 OOM 問題的虛擬內存空間碎片。
保留內存不需 要操作系統提供物理內存。只有在 GC(垃圾收集器)提供物理內存時才會分配物理內存。如果使用非常 低的物理內存來運行系統,則應該會出現 OOM 異常。檢查您的物理內存是否過低的一種簡單方法就是打 開 Windows 任務管理器,查看“性能”選項卡上的“內存使用”區域。
圖 3 顯示系統總共提供了 1981304 KB 內存,總內存數為 2518760 KB。當提供的內存總數接近總內存數時 ,系統就會耗盡可用內存。
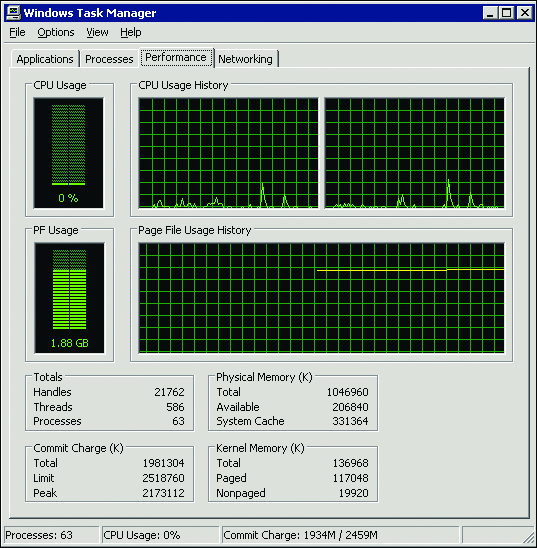
圖 3任務管理器裡 查看可用內存
GC 並非一次提供整個段。而是根據需要以多個塊的形式提供段。(注意,托管堆提 供的字節數由 # Total committed Bytes 表示,而不是 # Bytes in all Heaps(所有堆中的字節數)。 這是因為 # Bytes in all Heaps 中包含的第 0 代大小並非第 0 代中使用的實際內存,而是其預算。)
您可以使用用戶模式分析器(如 CLR 分析器)了解哪些對象導致了如此高的內存使用量。但在某 些情況下,運行分析器的開銷讓人無法接受 — 例如,當需要在生產服務器上調試問題時就會這樣 。在這種情況下,一種替代方法就是采取內存轉儲,然後使用調試器對其進行分析。那麼接下來介紹一下 如何使用調試器來分析托管堆。
衡量托管堆的大小
在衡量托管堆大小時,您首先需要了解 的是何時進行衡量。應該在垃圾收集之前、之後還是收集過程中進行衡量?衡量堆大小的最佳時間始終是 在第 2 代收集結束的時候,因為進行第 2 代收集時會收集整個堆。
要在第 2 代垃圾收集結束時 查看對象,可在調試器中設置以下斷點(對於服務器上的垃圾收集,只需將 WKS 替換為 SVR):
bp mscorwks!WKS::GCHeap::RestartEE "j (dwo(mscorwks!WKS::GCHeap::GcCondemnedGeneration)==2) 'kb';'g'"
現在您會在第 2 代垃圾收集結束時停止,下一步就是查看托 管堆上的對象。這些對象是在垃圾收集後保留下來的對象,您希望了解它們為什麼被保留下來的原因。
!dumpheap –stat 命令可對托管堆上的對象進行完整的轉儲。(因此,如果堆較大,!dumpheap 命令可能需要一段時間才能完成。)!dumpheap 命令生成的列表按類型和使用的內存量進行分類。這意味 著您可以從最後的幾行開始分析,因為這幾行代表占用了大部分空間的對象。
在圖 4 中的示例中 ,字符串占用了大部分空間。如果字符串是問題的根源,那麼這種問題往往容易解決。字符串的內容可反 映出其來源。
Figure4!dumpheap Output
0:000>!dumpheap -stat ... [omitted] 2c6108d4 173712 14591808 MyClass.XtraGrid.Views.Grid. ViewInfo.GridCellInfo 00155f80 533 15216804 Free 7a747c78 791070 15821400 System.Collections.Specialized. ListDictionary+DictionaryNode 7a747bac 700930 19626040 System.Collections.Specialized. ListDictionary 2c64e36c 78644 20762016 MyClass.MyEditor.ViewInfo.TextEditViewInfo 79124228 121143 29064120 System.Object[] 035f0ee4 81626 35588936 Toolkit.TlkOrder 00fcae40 6193 44911636 MyStrategyObject.TimeOver[] 791242ec 40182 90664128 System.Collections.Hashtable+bucket[] 790fa3e0 3154024 137881448 System.String Total 8454945 objects
您還可以在存儲桶中查看字符串。例如,您可以檢查大小在 150 至 200 之間的所有字符串,如圖 5 中所示。本例中的大量字符串都非常相似。因此,與其保留這麼多字符 串,不如將其共同的部分(“PendingOrder-”)和那些數字分開來保存,這樣做會更有效。
Figure5Viewing Strings of Specific Lengths
0:000>!dumpheap -type System.String -min 150 -max 200 Using our cache to search the heap. Address MT Size Gen 1874c4f0 790fa3e0 160 2 System.String 15.59.03: **** Transaction Completed. Account: 3344 Quantity: 50 18758218 790fa3e0 180 2 System.String PendingOrder-93344 187582cc 790fa3e0 180 2 System.String PendingOrder-12421 1875af38 790fa3e0 160 2 System.String 15.59.03: **** Transaction Complete. Account: 7722 Quantity: 2 1875be20 790fa3e0 152 2 System.String PendingOrder-10889 1875bf74 790fa3e0 152 2 System.String PendingOrder-10778 ... [omitted]
我們曾經多次看到過托管堆包含重復了數千次的相同字符串的情況。結果是產生 了一個字符串占用大量內存的龐大工作集。在這種情況下,使用字符串駐留往往更好。
對於其他 並不像字符串這樣明顯的類型,您可以使用 !gcroot 來了解這些對象為何處於活動狀態(請參見圖 6) 。注意,如果對象圖非常大,!gcroot 命令的執行可能需要較長時間。
Figure6Using !gcroot to Determine Why Objects Live
0:000>!gcroot 1875bf74 Note: Roots found on stacks may be false positives. Run "!help gcroot" for more info. ebx:Root:19011c5c(System.Windows.Forms.Application+ThreadContext)-> 19010b78(DemoApp.FormDemoApp)-> 19011158(System.Windows.Forms.PropertyStore)-> ... [omitted] 1c3745ec(System.Data.DataTable)-> 1c3747a8(System.Data.DataColumnCollection)-> 1c3747f8(System.Collections.Hashtable)-> 1c376590(System.Collections.Hashtable+bucket[])-> 1c376c98(System.Data.DataColumn)-> 1c37b270(System.Data.Common.DoubleStorage)-> 1c37b2ac(System.Double[]) Scan Thread 0 OSTHread 99c Scan Thread 6 OSTHread 484 ... [omitted]
除了托管堆上保留下來的對象,為您的進程提供的內存中還包含在第 0 代中分 配的內存。如果允許第 0 代在下一次垃圾收集發生前增大,您還可能會觀察到由於此問題而導致的內存 使用量變大。這種情況在 64 位 Windows 系統上比 32 位系統更常見。!eeheap –gc SOS 命令將 為您顯示第 0 代的大小。
如果對象保留下來會怎樣?
有時,開發人員認為他們的某些對 象應該處於死狀態,但 GC 似乎並沒有把這些對象清理掉。導致這種現象的最常見原因是:
對於這些對象強烈的引用仍然存在。
在最後一次收集對象的代時,對象還未處於死狀態。
對象 處於死狀態,但還沒有觸發對這些對象所在的代的收集。
對於第一種和第二種情形,您可以使用 ! gcroot 檢查是否有強烈的引用使對象保留了下來。人們往往忽略的一種可能性就是,對象在終結器線程 受阻的情況下由於尚處於終結隊列中而被保留下來,受阻的原因是無法調用單線程單元 (STA) 線程,因 此不會抽取消息來運行終結器(更多詳細信息請參閱 support.microsoft.com/kb/828988)。您可以通過 添加以下代碼確定是不是這一問題:
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
上述代碼可修復該問題,因為 WaitForPendingFinalizer 可抽取消息。 不過,一旦確認是這一問題後,您應改用 Thread.Join,因為 WaitForPendingFinalizer 是非常重型的 線程。
您還可以通過運行以下 SOS 命令確認是不是這一問題:
!finalizequeue
查看准備終結的對象數 — 而非“可終結對象數”。當終結器受阻時,終結器線程會顯示當前正在運 行哪個終結器(如果有)。(請參見圖 7 的終結隊列示例。)
Figure 7 Finalization Queue
0:003> !finalizequeue SyncBlocks to be cleaned up: 0 MTA Interfaces to be released: 0 STA Interfaces to be released: 0 ---------------------------------- generation 0 has 22 finalizable objects (002952f0->00295348) generation 1 has 0 finalizable objects (002952f0->002952f0) generation 2 has 0 finalizable objects (002952f0->002952f0) Ready for finalization 0 objects (00295348->00295348) Statistics: MT Count TotalSize Class Name 7911815c 1 20 Microsoft.Win32.SafeHandles.SafePEFileHandle 791003f4 1 20 Microsoft.Win32.SafeHandles.SafeFileMappingHandle 79100398 1 20 Microsoft.Win32.SafeHandles.SafeViewOfFileHandle 790fe034 2 40 Microsoft.Win32.SafeHandles.SafeFileHandle 790fb330 1 52 System.Threading.Thread 79111420 1 80 System.IO.FileStream 7910f304 15 300 Microsoft.Win32.SafeHandles.SafeRegistryHandle Total 22 objects 0:000>!gcroot 1875bf74 Note: Roots found on stacks may be false positives. Run "!help gcroot" for more info.
了解終結器線程的一個簡便方法就是查看 !threads-special 的輸出。圖 8 所示的堆棧顯示了終結器 線程通常的狀態 — 它正在等待一個事件指示有終結器要運行。當某個終結器受阻時,您將看到該終結器 正在運行。
Figure 8 Finalizer Thread Waiting for Finalizer
0:005>!threads -special
ThreadCount: 2
UnstartedThread: 0
BackgroundThread: 1
PendingThread: 0
DeadThread: 0
Hosted Runtime: no
PreEmptive GC Alloc Lock
ID OSID ThreadOBJ State GC Context Domain Count APT Exception
0 1 9b0 00181320 a020 Enabled 00000000:00000000 0014c260 0 MTA
3 2 c18 0018b078 b220 Enabled 00000000:00000000 0014c260 0 MTA (Finalizer)
OSID Special thread type
2 cd0 DbgHelper
3 c18 Finalizer
4 df0 GC SuspendEE
0:003>~3s;k
eax=00000000 ebx=00dffd20 ecx=00152ba0 edx=00000000 esi=00dffd24 edi=7ffdf000
eip=7ffe0304 esp=00dffcd4 ebp=00dffd7c iopl=0 nv up ei pl zr na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
SharedUserData!SystemCallStub+0x4:
7ffe0304 c3 ret
ChildEBP RetAddr
00dffcd0 77f4372d SharedUserData!SystemCallStub+0x4
00dffcd4 77e41bfa ntdll!NtWaitForMultipleObjects+0xc
00dffd7c 77e4b0e4 KERNEL32!WaitForMultipleObjectsEx+0x11a
00dffd94 7a01dd9a KERNEL32!WaitForMultipleObjects+0x17
00dffdb4 7a01e695 mscorwks!WKS::WaitForFinalizerEvent+0x7a
...
00dfff14 7a0983ef mscorwks!WKS::GCHeap::FinalizerThreadStart+0xbb
00dfffb8 77e4a990 mscorwks!Thread::intermediateThreadProc+0x49
00dfffec 00000000 KERNEL32!BaseThreadStart+0x34
第三個原因不應該是問題所在。通常,除非您手動引發了垃圾收集,否則只有在 GC 認為這樣做有效 時才會觸發收集。這意味著某個對象可能已經處於死狀態,但不會立即回收其占用的內存。但當系統物理 內存非常緊張時,GC 操作會變得更加積極主動。
托管堆上的碎片是否會造成問題?
在查明內存問題時,碎片是要關注的主要因素。它之所以重要是因為您需要了解托管堆上浪費了多少 空間。托管堆的碎片數量由可用對象所占用的空間量來表示。您可以使用 !dumpheap 命令了解托管堆上 有多少可用內存,如下所示:
0:000>!dumpheap -type Free -stat
total 230 objects
Statistics:
MT Count TotalSize Class Name
00152b18 230 40958584 Free
Total 230 objects
在此例中,輸出結果表明,有 230 個可用對象,總共大約 39MB。因此,此堆的碎片有 39MB。
當 您嘗試確定碎片是否會造成問題時,您需要了解碎片對於不同代意味著什麼。對於第 0 代,碎片不構成 問題,因為 GC 可以在碎片空間中進行分配。對於第 1 代和第 2 代,碎片可能會造成問題。要在第 1 代和第 2 代中使用碎片空間,GC 必須收集和提升對象以填補這些間隙。但由於第 1 代的大小不會超過 一個段,因此您通常需要關注的是第 2 代。
過多的釘住通常是造成碎片太多的原因。.NET Framework 2.0 在減少由於釘住而導致碎片的問題方面做了大量改進(有關 NET Framework 2.0 中 GC 改進方面的 詳細信息,請參閱以下網址的博客內容:blogs.msdn.com/476750.aspx),但如果應用程序仍是過多的使 用釘住,則還是會看到大量的碎片。您可以使用一個 SOS 命令 !gchandles 來查看釘住句柄的數量(請 參見圖 9)。還可以使用 !objsize 了解哪些對象被釘住,如圖 10 中所示。
Figure 10 Determining Which Objects Are Pinned
0:003> !objsize
Scan Thread 0 OSTHread 1a9cDOMAIN(0024F0F0):HANDLE(WeakSh):2212fc: sizeof(01231d30) = 52
(0x34) bytes (System.Threading.Thread)
DOMAIN(0024F0F0):HANDLE(Pinned):2213e8: sizeof(02234260) =
4096 (0x1000) bytes (System.Object[])
DOMAIN(0024F0F0):HANDLE(Pinned):2213ec: sizeof(02233250) =
4108 (0x100c) bytes (System.Object[])
DOMAIN(0024F0F0):HANDLE(Pinned):2213f0: sizeof(02233030) =
620 (0x26c) bytes (System.Object[])
DOMAIN(0024F0F0):HANDLE(Pinned):2213f4: sizeof(02232020) =
5276 (0x149c) bytes (System.Object[])
DOMAIN(0024F0F0):HANDLE(Pinned):2213f8: sizeof(0123118c) =
12 (0xc) bytes (System.Object)
DOMAIN(0024F0F0):HANDLE(Pinned):2213fc: sizeof(02231010) =
102632 (0x190e8) bytes (System.Object[])
Figure 9 Checking the Number of Pinned Handles
0:002> !gchandles
GC Handle Statistics:
Strong Handles: 16
Pinned Handles: 4
Async Pinned Handles: 0
Ref Count Handles: 0
Weak Long Handles: 0
Weak Short Handles: 1
Other Handles: 0
Statistics:
MT Count TotalSize Class Name
790f9d10 1 12 System.Object
790fb760 1 28 System.SharedStatics
791077ec 1 48 System.Reflection.Module
790fc894 2 48 System.Reflection.Assembly
790fad68 1 72 System.ExecutionEngineException
790facc4 1 72 System.StackOverflowException
790fac20 1 72 System.OutOfMemoryException
790fb9c0 1 100 System.AppDomain
790fb330 2 104 System.Threading.Thread
790fd91c 4 144 System.Security.PermissionSet
790fae0c 2 144 System.Threading.ThreadAbortException
79124314 4 8744 System.Object[]
Total 21 objects
LOH 中的碎片是有意而為之的,因為我們沒有對 LOH 進行壓縮。這並不意味著 LOH 上的分配與使用 NT 堆管理器的 malloc 相同!由於 GC 的工作特點,彼此相鄰的可用對象會自然地折疊成一個大的可用 空間,可用於滿足大型對象的分配請求。
衡量在垃圾收集上花費的時間
開發人員往往需要了解 GC 每次進行收集時所花費的時間。在軟件實 時情形下,該數據往往很重要,因為在這種情形下對於應用程序必須遵守的響應時間等條件有一定限制。 這當然是一個重要的考慮因素,因為在垃圾收集上花費過多時間就意味著占用了 CPU 用於實際處理的時 間。
了解在垃圾收集上花費的時間的最簡便的方法就是查看 % Time in GC 性能計數器。該計數器在 收集結束時更新,顯示剛剛完成的 GC 所花費的時間與自上次 GC 結束後所經歷時間的比值。如果在采樣 間隔內沒有發生收集,則該計數器不更新,您看到的值與上次相同。由於您知道性能監視器應用程序中的 采樣間隔(PerfMon 中默認的采樣間隔是 1 秒),您可以粗略計算出時間。
圖 11 給出了一些垃圾收 集數據示例。其中您將看到在第二個和第三個間隔中發生了第 0 代收集。由於我們並不准確了解在這些 間隔期間收集何時發生,因此這個方法並非 100% 准確。但它對於預測 GC 所花費的時間非常有用。
Figure 11 Sample GC Data
考慮以下示例,這對於第十一次 GC 而言是最極端的情形。假設第十次第 0 代收集在第二個間隔開始 時完成,第十一次第 0 代收集在第三個間隔結束時完成。這意味著兩次收集結束之間的時間大約是兩個 采樣間隔,或者說是兩秒。% Time in GC 計數器顯示為 3%,因此第十一次第 0 代收集只花費了 2 秒的 3%(或 60 毫秒)。
研究高 CPU 使用
當收集發生時,CPU 使用應該較高,從而使 GC 可以盡快完成。圖 12 顯示了收集始終會造成非常高 的 CPU 使用的一個示例。% Process Time(進程時間百分比)計數器中的所有峰值直接與 % Time in GC 的變化相對應。顯然,在實際中永遠不會發生這種情況,因為除了 GC 使用 CPU 之外,其他進程也將使 用 CPU。要確定還有哪些進程在占用 CPU 周期,您可以使用 CPU 分析器查看哪些功能占用了大多數 CPU 時間。
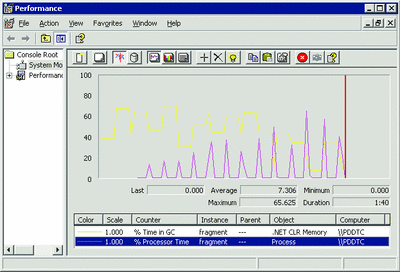
圖 12 當收集引起 CPU 使用之時
如果實際上您發現 GC 占用了太多 CPU 時間,則說明收集的發生頻率過高或者收集過程所花費的時間 太長。考慮當收集由分配觸發時的情況。分配速率是決定收集觸發頻率的主要因素。
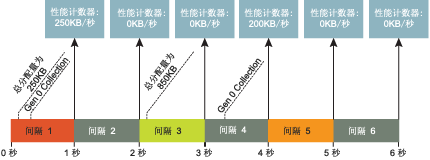
圖 13 當收集被分散開後產生較不准確的數據
當收集開始時,通過加上第 0 代和 LOH 中的已分配字節數對 Allocated Bytes/sec 計數器進行更新 。由於該計數器以速率表示,因此您看到的實際數值是最後兩個數值之間的差除以時間間隔的值。例如, 圖 13 說明了如果采樣速率為 1 秒並且收集只在經過一定間隔後才發生的情況。當收集發生時,性能計 數器的更新如下:
Allocation = 850-250=600KB
Alloc/Sec = 600/3=200KB/sec
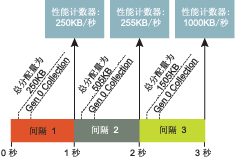
圖 14 數據會比較准確如果收集發生較頻繁時
盡管應用程序一直在分配,但性能計數器不會反映這一情況,因為它直到下一次收集時才會更新。如 果收集發生的頻率再高一些,您就會獲得更清楚的圖像(請參見圖 14)。
一個常見的錯誤就是將分配 速率用作衡量垃圾收集所花費時間的尺度 — 收集過程所花費的時間由 GC 檢查的內存量決定。由於 GC 只檢查保留下來的對象,因此收集時間長意味著有許多對象保留了下來。如果您遇到這種情況,可以使用 我們上面討論的技巧來確定為何有這麼多對象保留了下來。
將您想詢問的問題和提出的意見發送至 [email protected].
Claudio Caldato是 Microsoft 公共語言運行庫團隊的性能和垃圾收集器項目經理。
Maoni Stephens是 Microsoft 公共語言運行庫團隊中從事垃圾收集器工作的主要開發人員。在加入 CLR 之前,Maoni 已在 Microsoft 操作系統組工作多年。