對於Lucene 3.0.0的線程模型我非常的感興趣, 因為對於多線程我也是最近才接觸, 別看我接觸程序都快十年了, 有幾個地方我一直非常的遺憾 :
沒有寫過網絡相關的代碼, 沒有寫過多線程程序, 沒有寫過數據庫相關的內容, 沒有寫過Linux相關的程序
. 可能各位會覺得非常奇怪了:
那你這十年干嘛去了? 這不是基本上等同於不懂程序啊! (–_-)
我花了6年的時間鞏固了算法和數據結構基礎, 另外4年糊裡糊塗的搞了很多比如3D游戲, 游戲的人工智能程序等內容, 總體上來說, 沒有太多虛度時間 代碼寫得不算多, 算法基礎不壞, 不過效率也不算蠻高, 我希望能夠在接下來的幾年內好好補一補, 慢慢變成一個"萬金油" 把亂七八糟的東西都搞搞.
對於研究別人的程序我有一個愛好, 相對於停留在"使用"的層面上, 還不如停留在"研究"的層面上, 我的感覺是, 在工作之前應該盡量的把基礎作牢固, 能夠多把別人代碼中先進的思想學會, 不然工作了以後, 項目的壓力和生活的壓力會讓人浮躁, 會讓人沒有一個定力來研究需要花費很多時間去搞懂的內容. 其實目前的開源框架(比如說apache下面的)和可以免費使用的框架(比如WPF之類的)已經非常的多了, 想要僅僅是"做"完一個項目其實不算難事, 當然是一般的項目, 不是龐大的項目. 重要的是, 怎麼把自己的思想提升到更高的層面, 我希望我能按照自己的想法來發展. 可能這也是我大學來沒有接過一個外包項目的原因吧.
通過寫日志我想和大家分享我的心得, 對於一個開源框架的研究, 可能也是需要一個小小的團隊一起來做, 一個人閱讀著海量的代碼是一件非常苦的事情, 如果有人討論一下, 可能很多問題都會迎刃而解了. 另外對於Lucene, 我希望能夠在對源代碼有著相當的把握後, 使用操作系統無關的庫和c++進行一些重寫, 對於關鍵的代碼實現一下, 一方面的原因是, 以後工作的語言是c++而不是java, 另一方面也是為自己留下一些"可用"的代碼. 這個依然是停留在"研究"的層面上, 未來這個項目能否發展為"可用" 需要再看看.
另外轉帖請注明出處: leftnoteasy.cnblogs.com, leftnoteasy原創
Lucene 3.0.0的Consumer調用部分(續):
Lucene的線程結構和Lucene的Consumer模型是密切相關的, 之前我有一篇日志記載了一些關於Lucene的Consumer的部分, 關於這些內容請見: Lucene 3.0.0 之樣例解析(3)-IndexFiles.java, 之前寫的比較粗糙, 有好些內容是沒有記載完全的, 這裡就補充一下:
為了解開復雜的consumer調用模型, 我試著繪制一下uml圖來理清思路:
跟consumer和processor類直接相關的類就有下面的這些, 看起來挺恐怖的吧, 下面我來試圖將他們之間的關系理清楚:
值得注意的是, 在閱讀代碼的時候發現, 有些時候, 就算是兩個抽象類的方法一模一樣, 也沒有使用繼承的關系來做, 可能是Lucene的開發者為了不出現RTTI的錯誤吧, 這個在初次閱讀代碼的時候很容易把人弄混淆.
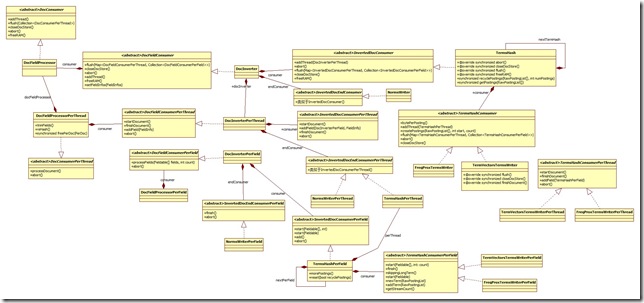
1) DocFieldProcessor, DocFieldProcessorPerThread與DocInverter:
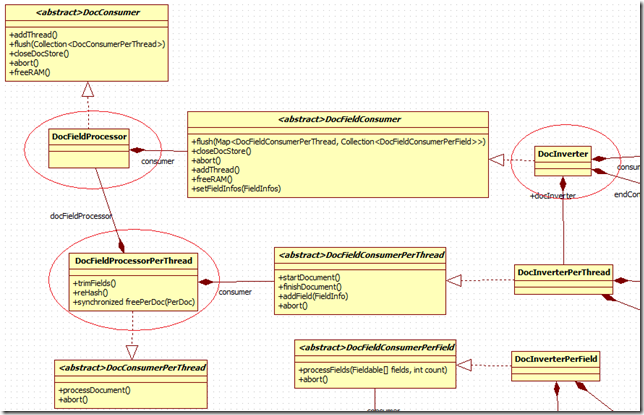
DocFieldProcessor
DocFieldProcessor繼承自DocConsumer, 這個DocConsumer可以說是最高層的Consumer了. 下面我們來看看DocFieldProcessor的內容, 查看代碼的時候會發現一句話:
1: /**
2: * This is a DocConsumer that gathers all fields under the
3: * same name, and calls per-field consumers to process field
4: * by field. This class doesn't doesn't do any "real" work
5: * of its own: it just forwards the fields to a
6: * DocFieldConsumer.
7: */
翻譯一下就是: DocConsumer把全部名稱相同的Field聚集起來, 然後調用PerField為後綴的consumer進行處理, 這個類不做"實際"的工作, 它僅僅把工作推向了DocFieldConsumer.
看看實際的代碼就可能更容易理解一點:
1: public void flush(Collection<DocConsumerPerThread> threads, SegmentWriteState state) throws IOException {
2:
3: Map<DocFieldConsumerPerThread, Collection<DocFieldConsumerPerField>> childThreadsAndFields = new HashMap<DocFieldConsumerPerThread, Collection<DocFieldConsumerPerField>>();
4: for ( DocConsumerPerThread thread : threads) {
5: ......
6: }
這個flush函數就可以看出, 實際上DocFieldProcessor是調用了多個DocFieldProcessorPerThread, 下面我們來看看DocFieldProcessorPerThread:
DocFieldProcessorPerThread:
這個函數繼承自DocConsumerPerField,也就是剛剛提到的做"實際"工作的類, 而繼承自基類的processDocument()函數更是重點中的重點了
還是老樣子, 看看注釋:
1: /**
2: * Gathers all Fieldables for a document under the same
3: * name, updates FieldInfos, and calls per-field consumers
4: * to process field by field.
5: *
6: * Currently, only a single thread visits the fields,
7: * sequentially, for processing.
8: */
翻譯過來: 把全部名字相同的Fieldable(同Field)聚集起來, 更新FieldInfo, 然後調用per-Field consumers來一個一個Field地進行處理. 當前, 就只有一個Thread來訪問這些Fields, 按照順序的來處理(注:我這裡不太理解"currently"的含義是在這個程序裡還是這個版本)
processDocument()的代碼很長, 有一百多行, 我之前的文章也有過一些分析. 歸納出來, 這個函數就做了幾件事情:
i. 把Field收集起來, 看看之前出現過沒有, 如果沒有出現過, 則擴充hash
ii. 對這些Field進行排序(請見裡面的quickSort()函數)
iii. 對每個Field調用其consumer(也就是基類為DocFieldConsumerPerField)進行處理.
DocInverter:
1: /** This is a DocFieldConsumer that inverts each field,
2: * separately, from a Document, and accepts a
3: * InvertedTermsConsumer to process those terms. */
對來自同一篇文檔的每一個Field進行互不相關的倒排操作, 然後調用InvertedTermsConsumer對這些Term進行處理.
2) DocInverterPerField, TermsHashPerField
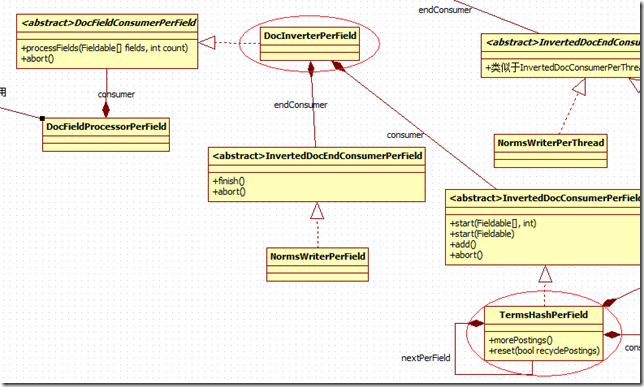
DocInverterPerField.
這個類是DocProcessorPerThread中調用的, 請見DocProcessorPerThread中的processDocument()函數中的一段話
1: for(int i=0;i<fieldCount;i++)
2: fields[i].consumer.processFields(fields[i].fields, fields[i].fieldCount);
這裡的consumer就是DocInverterPerField所繼承的DocFieldConsumerPerField
1: /**
2: * Holds state for inverting all occurrences of a single
3: * field in the document. This class doesn't do anything
4: * itself; instead, it forwards the tokens produced by
5: * analysis to its own consumer
6: * (InvertedDocConsumerPerField). It also interacts with an
7: * endConsumer (InvertedDocEndConsumerPerField).
8: */
保留一篇文檔中的一個field的倒排狀態, 這個類什麼都不干(其實也不完全是, 後面再說說), 它將token的處理丟給自己的consumer(InvertedDocConsumerPerField), 另外它還和endConsumer(InvertedDocEndConsumerPerField)發生關系.
這裡的processField主要干了下面幾件事情:
1: @Override
2: public void processFields(final Fieldable[] fields,
3: final int count) throws IOException {
4: 1) 首先判斷是否是需要tokenized, 如果不需要, 就直接把字符串放進來
5: 如果需要就調用analyzer
6: 2) 調用自己的consumer進行處理
7: }
TermsHashPerField
在之前, 我分析過TermHashPerField, 這次主要從調用的方面來說說
TermsHashPerField主要由DocInverterPerField調用, 在DocInverterPerField中對TermsHashPerField的初始化:
1: @Override
2: public void processFields(final Fieldable[] fields,
3: final int count) throws IOException {
4: ....
5: try {
6: int offsetEnd = fieldState.offset-1;
7:
8: boolean hasMoreTokens = stream.incrementToken();
9:
10: fieldState.attributeSource = stream;
11:
12: OffsetAttribute offsetAttribute = fieldState.attributeSource.addAttribute(OffsetAttribute.class);
13: PositionIncrementAttribute posIncrAttribute = fieldState.attributeSource.addAttribute(PositionIncrementAttribute.class);
14:
15: consumer.start(field);
16: ....
17: }
在看看TermsHashPerField裡面的start():
1: @Override
2: void start(Fieldable f) {
3: termAtt = fieldState.attributeSource.addAttribute(TermAttribute.class);
4: consumer.start(f);
5: if (nextPerField != null) {
6: nextPerField.start(f);
7: }
8: }
其實就是對termAtt進行初始化, termAtt是跟TokenStream相關聯的類, 表示一個詞的屬性, 內容等等, 這裡不多說, 相關的資料不少.TermHashPerField重要的是add()函數, add()是一個巨無霸函數, 大概接近150行左右, 要逐行理解很麻煩, 我說說大概的意思:
1: @Override
2: void add() throws IOException {
3: 1) 獲取token文字信息
4: 2) 進行hash處理, 並移除無效字符
5: 3) 如果單詞出現過, 就調用consumer.addTerm(), 否則調用consumer.newTerm()
6: }
3) TermVectorsTermsWriterPerField, FreqProxTermsWriterPerField
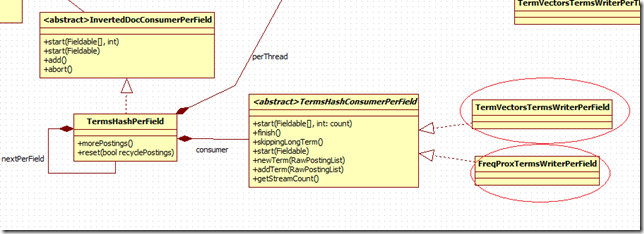
這兩個類都是繼承自TermsHashConsumerPerField, 但是情況不一樣, TermsVectorsTermsWriterPerField是僅僅當Field指定了TermVector存儲的時候才調用的.
他們都具有addTerm與newTerm的方法, 意思也比較好理解, 但是程序也比較復雜, 我目前還沒有怎麼去看, 如果有可能我希望寫一篇專門關於Lucene裡面的buffer相關的內容的文章來說明一下.