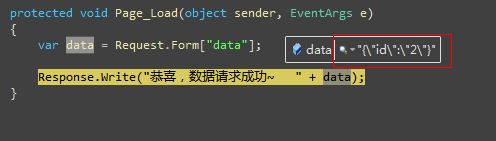
一個主要的影響就是內聯函數(Inlining Function)調用。之前,JIT對內聯方法的處理非常保守,Vance Morrison解釋了個中緣由,
它對內聯的處理並不是很好。內聯總是減少指令執行的數量(這是由於最低限度的調用和返回指令沒有被執行),但是它能(並經常)讓結果代碼變得很大。大部分人都能直覺地理解,內聯大的方法(比如1Kb的)不是很有意義,而內聯非常小的方法可以讓調用的占用空間更小(由於調用指令才5字節),這樣的選擇總是正確的,但是介於兩者之間的方法要如何處理呢?
有趣的是,當你讓代碼變大時,你也就讓它執行緩慢,因為內存天生地緩慢;你的代碼越大,它越不會放在最快的CPU緩存(稱之為L1)裡面執行,在那樣的情況下,處理器需要執行3-10個周期直到它能從另外的緩存(稱之為L2)中獲取到執行代碼,如果L2緩存中還不存在,那麼就需要到主內存中獲取(需要花費10+周期)。對於在緊密循環中執行的代碼,這樣的結果不會有什麼問題,因為所有的代碼都適合放入到最快緩存中(典型的是64K),不過對於“常規的”代碼,它通過大量的方法來執行大量的代碼,“越大就越慢”的效果就非常顯著。更大的代碼也就意味著在啟動時從磁盤獲取代碼需要更大的磁盤I/O,這就意味著你的應用程序啟動較慢。
在Service Pack 1中,微軟引入了一個新的基於代碼尺寸的啟發式算法,來判斷調用是否處於一個循環中。在常規情況下,函數只有當在調用空間中的結果機器碼比原始版本要小時,才能被內聯。這樣做就保證了盡可能多的代碼能適合CPU的緩存,當緩存不夠用時,就能對性能產生巨大的影響。
當處在循環中時,分部異常也可以很好地工作。這是因為據推測函數通常會被多次調用,所以CLR允許內聯函數可以增長至原始調用大小的5倍大。類似值類型優化這樣的條件有可能更進一步地增加容許尺寸的大小。
查看英文原文:http://www.infoq.com/news/2008/09/JIT-Inlining