1、DataContractSerializer支持的類型....................................2
1.1.用[DataContract]屬性標記的類型....................................2
1.2..net 原生類型.....................................................2
1.3.用[Serializable]屬性標記的類型...................................2
1.4.枚舉類型.........................................................3
1.5.呈現為xml的類型...................................................3
1.6.集合類型.........................................................3
2、定義需要使用DataContractSerializer序列化的類........................3
2.1.DataContract屬性的參數...........................................3
2.2.DataMember屬性的參數.............................................4
2.3.[DataContract]屬性標識的類型跟XmlSerializer序列化器的類型的不同....4
2.4.准備待序列化的用 DataContract標識類................................5
2.5.准備待序列化的用DataContract標識類型的對象.........................7
3、使用DataContractSerializer類不同的方法序列化用DataContract標識類型的對象....7
3.1.使用WriteObject(Stream stream, object graph)方法序列化..................8
3.2.使用WriteObject(XmlDictionaryWriter writer, object graph)方法序列化....10
3.2.1.CreateTextWriter方法..............10
3.2.2.CreateMtomWriter方法..............13
3.2.3.CreateBinaryWriter方法............18
3.3.DataContractSerializer序列化總結.....19
在WCF中,DataContractSerializer是默認的序列化器,不過WCF中還有一個叫NetDataContractSerializer的序列化器,它跟DataContractSerializer一樣也是從XmlObjectSerializer類繼承。NetDataContractSerializer跟DataContractSerializer一個主要的不同是:NetDataContractSerializer序列化後的xml中包含了.net的類型信息,反序列化時必須要被反序列化為同樣類型的對象,這點跟BinaryFormatter和SoapFormatter這兩個序列化器類似。DataContractSerializer序列化後的xml中則不包含.net的類型信息,通用性和交互性更好。在實際應用中DataContractSerializer是WCF的默認序列化器,絕大多數情況下都是使用DataContractSerializer,下面我們只對DataContractSerializer做詳細介紹。
一般情況下WCF的基礎結構(infrastructure)會調用DataContractSerializer對要傳輸的數據對象就行序列化,不過也有特殊情況,WCF會調用別的序列化器序列化數據對象。
當遇到數據類成員中標記有類似[XmlAttribute]屬性這樣的細致設置生成xml格式的屬性時,這時WCF infrastructure需要調用XmlSerializer序列化器來序列化這樣的數據對象,通過在一個方法前加上[XmlSerializerFormat]屬性值是WCF infrastructure調用XmlSerializer序列化器。
[XmlSerializerFormat]屬性可以標記一個方法,表示這個方法使用XmlSerializer序列化器。
[XmlSerializerFormat]屬性也可以用來標記一個ServiceContract,表示整個ServiceContract都用XmlSerializer序列化器。
比如:
[ServiceContract]
public interface IAirfareQuoteService
{
[OperationContract]
[XmlSerializerFormat]
float GetAirfare(Itinerary itinerary, DateTime date);
}
public class Itinerary
{
public string fromCity;
public string toCity;
[XmlAttribute]
public bool isFirstClass;
}
1、DataContractSerializer支持的類型
DataContractSerializer支持絕大多數的可序列化的類型的序列化,具體包括:
1.1.用[DataContract]屬性標記的類型
這種類型是為DataContractSerializer定制的可序列化類型,DataContractSerializer對這種了類型提供最全面的支持。
1.2..net 原生類型
.net內建的一些簡單的數據類型,比如:Byte, SByte, Int16,string等,還有一些不是原生類型但是可以視作原聲類型的類型,比如:DateTime, TimeSpan, Guid, Uri。
1.3.用[Serializable]屬性標記的類型
這是為rometing准備的序列化類型,被DataContractSerializer完全支持。
使用DataContractSerializer序列化前面SoapFormatter序列化的那個例子得到的結果:
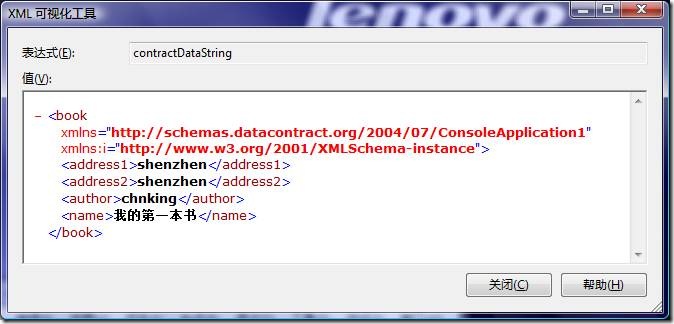
把這個序列化後的結果跟直接使用SoapFormatter序列化的結果比較一下有以下幾點不同:
l DataContractSerializer序列化是面向數據的,不保留對象之間的引用關系,所以雖然address1和address2指向的是同一個對象,但DataContractSerializer還是分別給他們賦了同樣的值。
l 不再包含.net的類型相關的信息,類的全限定名、版本、區域、KeyToken等等。
1.4.枚舉類型
1.5.呈現為xml的類型
類型本身就可以呈現為xml的類型,比如XmlElement ,XmlNode,或者ADO.NET相關的類型,比如DataTable , DataSet。這些類型序列化時會被直接以xml的形式呈現。
1.6.集合類型
可被序列化的類型組成的集合類型也被支持。
2、定義需要使用DataContractSerializer序列化的類
自定義一個類或結構,這個類或結構:
首先,在類前面加上[DataContract],表示這個類包含有數據契約
其次,在需要對外暴露的成員用[DataMember]屬性標記。在這個類中,只有被標記為[DataMember]的成員才會被序列化,不管成員是公有的還是私有的。
2.1.DataContract屬性的參數
[DataContract]可以用來描述一個class或者struct,可以帶有兩個參數:
l Name
指定這個數據契約對外的類型名,如果沒有指定此參數,缺省的就是類名。
l Namespace
指定這個類被序列化為xml後的Root元素的名稱空間,為URI形式。
如果沒有指定此參數,缺省名稱空間為:“http://schemas.datacontract.org/2004/07/這個類的.net類名稱空間”
比如有這樣一個標記為DataContract的類型:
namespace DataContractSerializerTest.Myspace
{
[DataContract]
class Person
{
//代碼
}
}
這個類型的默認名稱空間就是http://schemas.datacontract.org/2004/07/ DataContractSerializerTest.Myspace
2.2.DataMember屬性的參數
[DataMember]可以用來描述Property和field,不管這個成員是public或者private,只要標記了[DataMember],這個成員就會被序列化。
[DataMember]屬性可以帶有以下幾個參數:
l Name
指定這個成員對外暴露的名稱,如果沒有指定此參數,缺省的就是此Property或field名。
l Isrequired
這個參數告訴DataContractSerializer序列化器把xml數據反序列化為這個類型時,這個成員是不是必須有的。此屬性在反序列化時起作用。
l Order
指示這個成員被序列化後的順序。此屬性在序列化時起作用。如果在一個類中既存在用Order參數約束的成員,又有沒用Order參數約束的成員,那麼序列化後沒有Order參數約束的成員排在Order參數約束的成員之前。
l EmitDefaultValue
此參數告訴DataContractSerializer序列化器,在序列化時如果這個數據成員的值是這個成員類型的缺省值(比如成員是int類型,缺省值為0,如果成員是個引用類型,缺省值為null),是否將此成員序列化。=true時表示要序列化,=false時表示不序列化,此參數的默認值為true。
當引用類型的成員為null時,此參數設置為true時,這個成員被序列化後的xml表現為xsi:nil="true",比如:
<Name xsi:nil="true" />
2.3.[DataContract]屬性標識的類型跟XmlSerializer序列化器的類型的不同
這兩種類型都是面向數據的,都不關心數據的.net類型信息。但是他們還是有所不同:
l DataContract的類型只能把用DataMember標識的成員序列化成element形式,不能序列化為attribute,如果一定要把數據成員序列化為attribute形式就需要用使用XmlSerializer序列化器。
l DataMember屬性可以通過order參數指定此成員序列化後的出現順序,用於XmlSerializer序列化器的XmlElement屬性無此功能。
l DataContract的類型只要在成員前加上DataMember標記,不管成員是public或private的,都會被序列化,XmlSerializer序列化器只序列化public的成員。
l DataContract的類型的成員的名稱空間跟整個類的一致,成員不能獨立設置自己的名稱空間(DataMember屬性沒有名稱空間參數),XmlSerializer序列化器允許成員擁有自己的名稱空間(XmlAttribut和XmlElement都有namespage參數設置成員獨立的名稱空間)。
2.4.准備待序列化的用 DataContract標識類
設計一個的Person類型,其中包含五個成員,binaryBuffer1、binaryBuffer2、name、address、age,其中name和address又分別是DataContract標識的簡單類型。
binaryBuffer1和 binaryBuffer2是byte[]類型的數據,表示二進制的數據,可能包含任何非二進制的對象,比如圖片、聲音等等。這裡放兩個二進制的數據為了測試不同長度的二進制數據在DataContractSerializer不同的方法中會被如何處理。
[DataContract(Namespace = "htttp://chnking")]
class Person
{
private Name name;
private Address address;
private int age;
[DataMember]
public byte[] binaryBuffer1;
[DataMember]
public byte[] binaryBuffer2;
public Person(Name name, Address address, int age)
{
this.name = name;
this.address = address;
this.age = age;
}
[DataMember(Order = 2)]
public int Age
{
get { return age; }
set { age = value; }
}
[DataMember(EmitDefaultValue = true, Order = 0)]
public Name Name
{
get { return name; }
set { name = value; }
}
[DataMember(Order = 1)]
public Address Address
{
get { return address; }
set { address = value; }
}
}
[DataContract(Namespace = "htttp://chnking")]
class Name
{
private string firstname;
private string lastname;
public Name(string firstname, string lastname)
{
this.firstname = firstname;
this.lastname = lastname;
}
[DataMember]
public string Lastname
{
get { return lastname; }
set { lastname = value; }
}
[DataMember]
public string Firstname
{
get { return firstname; }
set { firstname = value; }
}
}
[DataContract(Namespace = "htttp://chnking")]
class Address
{
private string city;
private string postcode;
private string street;
public Address(string city, string postcode, string street)
{
this.city = city;
this.postcode = postcode;
this.street = street;
}
[DataMember]
public string Street
{
get { return street; }
set { street = value; }
}
[DataMember]
public string Postcode
{
get { return postcode; }
set { postcode = value; }
}
[DataMember]
public string City
{
get { return city; }
set { city = value; }
}
}
2.5.准備待序列化的用DataContract標識類型的對象
實例化一個Person的對象,後續步驟將要序列化這個對象。
注意,這裡給第一個二進制數據賦了一個20字節長數據,第二個二進制數據賦了一個768字節長度的數據,為什麼這麼賦值,後面會有說明。
//構造一個需要序列化的DataContract的對象
Person person = new Person(new Name("比爾", "蓋茨"),
new Address("shenzhen", "518000", "fuqiang road"),
40);
//用一個重復的值填充第一個二進制數據bufferbytes1
int size1 = 20;
byte[] bufferbytes1 = new byte[size1];
for (int i = 0; i < size1; i++)
{
//65表示ASCII碼的A
bufferbytes1[i] = 65;
}
person.binaryBuffer1 = bufferbytes1;
//用一個重復的值填充第二個二進制數據bufferbytes2
int size2 = 768;
byte[] bufferbytes2 = new byte[size2];
for (int i = 0; i < size2; i++)
{
//66表示ASCII碼的B
bufferbytes2[i] = 66;
}
person.binaryBuffer2 = bufferbytes2;
3、使用DataContractSerializer類不同的方法序列化用DataContract標識類型的對象
實例化一個DataContractSerializer序列化器,DataContractSerializer序列化器跟XmlSerializer序列化器一樣,沒有缺省構造方法,至少需要提供要序列化對象的類型參數。
//准備DataContractSerializer序列化器
DataContractSerializer dcs = new DataContractSerializer(typeof(Person));
DataContractSerializer序列化對象的方法是WriteObject,這個WriteObject主要有兩個重載,WriteObject(Stream stream, object graph)和WriteObject(XmlDictionaryWriter writer, object graph)。
下面對這兩種序列化方法分別討論。
3.1.使用WriteObject(Stream stream, object graph)方法序列化
這個方法跟XmlSerializer序列化器的Serialize方法類似,是把序列化的對象的xml字符串直接編碼序列化為字節流,而且跟XmlSerializer一樣,從字符串到字節流的使用UTF8進行編碼。
Stream(dcs, person);
private static void Stream(DataContractSerializer dcs, Person person)
{
//構造用於保存序列化後的DataContract對象的流
MemoryStream contractDataStream = new MemoryStream();
//將DataContract對象序列化到流
dcs.WriteObject(contractDataStream, person);
//為了查看序列化到流中的內容,將流內容讀取出來並用UTF8解碼為字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Position = 0;
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//將流反序列化為DataContract對象
contractDataStream.Position = 0;
person = (Person)dcs.ReadObject(contractDataStream);
}
這部分代碼跟XmlSerializer部分的類似,不加更多的說明了。
序列化後的xml這樣的:
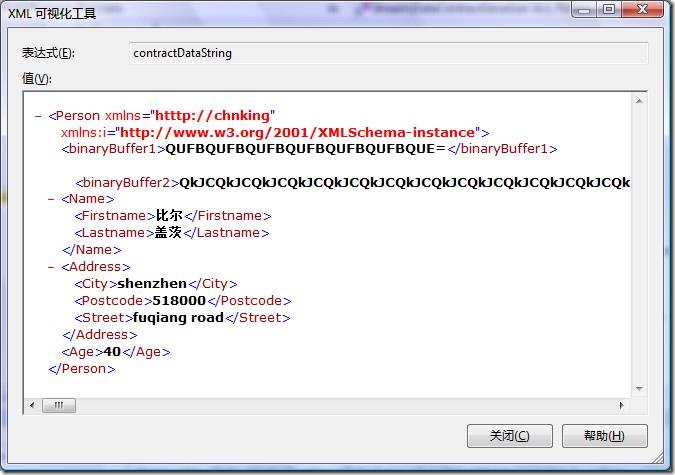
WriteObject(Stream stream, object graph)方法序列化有以下特點:
l DataContractSerializer首先把對象序列化為一個xml 形式的字符串。
l 對於其中的二進制數據,不管多大長度,一律轉成base64編碼的字符串。本例中bufferbytes2被設置為768字節長度,序列化結果是一串base64的編碼,又測試了把bufferbytes2長度增加為7680個字節,序列化的結果仍然是一串更長的base64的編碼。
l DataContractSerializer然後把序列化後的xml形式的字符串以UTF8編碼(這是默認的編碼,並且沒有提供可以使用別的編碼的接口,所以對其解碼也必須使用UTF8,這點跟XmlSerializer和SoapFormatter序列化器一樣)對其進行編碼,轉換到字節流,最終保存到一個流對象中,本例中就是MemoryStream。可以通過對字節流進行UTF8解碼得到xml的字符串,就是上圖看到的結果。
反序列化後的Person對象是這樣的:
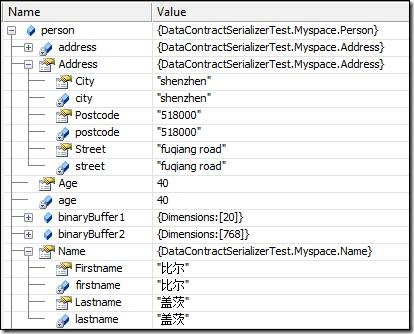
3.2.使用WriteObject(XmlDictionaryWriter writer, object graph)方法序列化
這個方法是DataContractSerializer序列化器把對象序列化為xml字符串後,不直接對xml進行編碼轉換成字節流,而是把xml寫入到XmlDictionaryWriter,XmlDictionaryWriter提供了多種對xml進行編碼的選擇,最終再由XmlDictionaryWriter把編碼後的xml寫入到目標流中。
XmlDictionaryWriter提供了三類靜態方法,構造三種不同類型的XmlDictionaryWriter,分別對xml進行不同的編碼操作。
它們分別是:
3.2.1.CreateTextWriter方法
CreateTextWriter方法構建的XmlDictionaryWriter寫入器,這樣的寫入器跟WriteObject(Stream stream, object graph)方法的作用類似,也是直接把xml的內容直接編碼為字節流,但是允許選擇編碼時使用哪種編碼。
XmlDictionaryWriter的CreateTextWriter方法主要下面兩種重載形式。
public static XmlDictionaryWriter CreateTextWriter (Stream stream)
public static XmlDictionaryWriter CreateTextWriter (Stream stream, Encoding encoding)
第一個重載方法沒有Encoding參數,默認采用UTF8進行編碼,這樣第一個方法的作用其實跟WriteObject(Stream stream, object graph)方法一樣。
第二個重載方法有Encoding參數,可以指定在編碼時采用何種編碼,是Unicode還是UTF8等。下面的示例代碼使用第二個重載方法,指定UTF8編碼。
XmlDictionaryCreateTextWriter(dcs, person);
private static void XmlDictionaryCreateTextWriter(DataContractSerializer dcs, Person person)
{
//構造用於保存序列化並編碼後的DataContract對象的流
MemoryStream contractDataStream = new MemoryStream();
//新建一個CreateTextWriter方法構建的指定Unicode的XmlDictionaryWriter對象
XmlDictionaryWriter xdw = XmlDictionaryWriter.CreateTextWriter(contractDataStream, Encoding.UTF8);
//調用WriteObject方法將對象通過XmlDictionaryWriter序列化並編碼
dcs.WriteObject(xdw, person);
//將序列化並編碼後的字節流寫入到原始流對象
xdw.Flush();
contractDataStream.Position = 0;
//為了查看序列化到流中的內容,將流內容讀取出來並用Unicode解碼為字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//將流反序列化為DataContract對象
contractDataStream.Position = 0;
XmlDictionaryReader reader = XmlDictionaryReader.CreateTextReader(contractDataStream, Encoding.UTF8, new XmlDictionaryReaderQuotas(), new OnXmlDictionaryReaderClose(OnReaderClose));
person = (Person)dcs.ReadObject(reader);
reader.Close();
}
public static void OnReaderClose(XmlDictionaryReader reader)
{
return;
}
序列化後,contractDataStream中獲得的序列化後的數據長度為1385字節。
將contractDataStream中的字節流用UTF8解碼,得到的內容跟前面的WriteObject(Stream stream, object graph)方法序列化後的結果一模一樣:
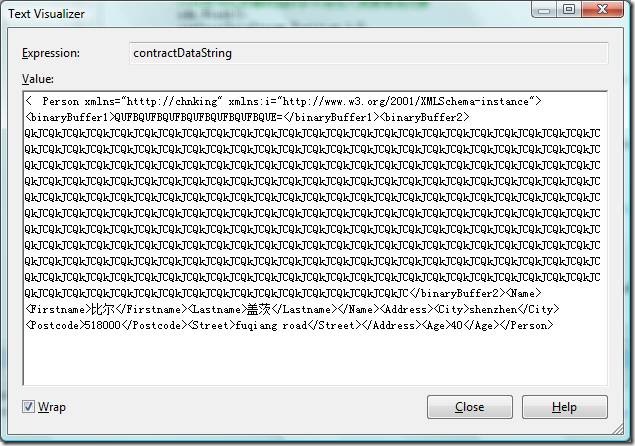
再用Encoding.Unicode 編碼測試,序列化後,contractDataStream中獲得的序列化後的數據長度為2756字節,明顯比前面使用UTF8編碼得到的結果長的多。這是很正常的結果,因為一般ASCII可表示的字符,使用UTF8編碼也是用一個字節表示,並跟ASCII編碼兼容,而UTF-16編碼會把所有字符都編碼為2個字節,所以使用Encoding.Unicode編碼後的結果會大很多,幾乎是UTF的2倍(因為測試的內容字符絕大多數是ASCII可表示的字符)
將contractDataStream中的字節流用Encoding.Unicode解碼,查看內容為,解碼後的內容跟UTF8解碼後的內容也是一致的:
實際測試CreateTextWriter方法中的Encoding參數只能為:Encoding.Unicode、Encoding.UTF8和Encoding.BigEndianUnicode 三種。
CreateTextWriter方法構建的XmlDictionaryWriter寫入器有以下特點:
l DataContractSerializer首先把對象序列化為一個xml 形式的字符串。對於其中的二進制數據,不管多大長度,一律轉成base64編碼的字符串。
l DataContractSerializer把序列化後的xml字符串傳給XmlDictionaryWriter。
l XmlDictionaryWriter把序列化後的xml形式的字符串以指定的編碼對其進行編碼,轉換到字節流,最終保存到一個流對象中,本例中就是MemoryStream。
序列化時,使用XmlDictionaryWriter的CreateTextWriter方法建立的XmlDictionaryWriter對象作為寫入器,反序列化時,相應的就要用XmlDictionaryReader的CreateTextReader建立的XmlDictionaryReader對象來作為讀取器。
CreateTextReader方法簽名如下:
CreateTextReader(Stream stream, Encoding encoding, XmlDictionaryReaderQuotas quotas, OnXmlDictionaryReaderClose onClose);
參數說明:
stream – 保存序列化後數據的流對象。
encoding – 反序列化時使用的編碼,應該跟序列化時使用的編碼一致。
quotas – 指定XmlDictionaryReader對象的一些極限值,比如可以讀取的stream的最長長度等等。XmlDictionaryReaderQuotas的默認構造方法對這些極限值構造了一個比較安全的缺省值,比如MaxArrayLength = 16384,可以反序列化數據的最長長度。當序列化後的stream中的字節長度長於MaxArrayLength設定的值,反序列化時將會拋出異常。
onClose – delegate類型,指定一個方法,在XmlDictionaryReader關閉時觸發
3.2.2.CreateMtomWriter方法
前面CreateTextWriter方法構造的XmlDictionaryWriter寫入器,處理二進制數據的方式是把二進制數據轉成base64編碼的字符串,這個處理方法在一般情況下是個不錯的方案,但是base64編碼會增加編碼後的長度,在二進制數據比較長的情況下,base64編碼帶來的長度增加將不能忽視。
Base64編碼將每3個字節的數據拆散重組為4字節可表示簡單字符的數據,編碼後的數據長度比為3:4,如果數據長度不長,增加的長度影響不大,但是如果原來的二進制數據就比較大,比如300K,編碼後的數據將會是400K,再如果原來是30M,編碼後為40M,多出來的數據量難以忽視。
鑒於這種情況,W3C制定了XOP(XML-binary Optimized Packages,XOP)協議來解決二進制問題,XOP 提供一個機制,可選擇性地提取要優化的信息,將其添加到多部分 MIME 消息中(其中也包括您的 SOAP 消息)並顯式地對其進行引用。使用 XOP 的過程稱為 MTOM(SOAP 消息傳輸優化機制——Message Transmission Optimization Mechanism)。
經過MTOM處理的數據,形式上為MIME(郵件的內容形式),XML 數據組成第一部分,而二進制數據視其長度的不同或者被編碼成base64放在xml中,或者作為附加部分添加到xml部分的後面。
CreateMtomWriter用來構造XmlDictionaryWriter最常用的方法重載是:
CreateMtomWriter(Stream stream, Encoding encoding, int maxSizeInBytes, string startInfo);
參數說明:
stream – 保存序列化後數據的流對象。
encoding – 序列化時使用的編碼。
maxSizeInBytes – 將被緩沖到XmlDictionaryWriter寫入器的數據最大字節數
startInfo – 在生成的MIME消息的ContentType增加一個名稱為start-info的header,header的值就是這個參數提供的。
看一下用CreateMtomWriter構造的XmlDictionaryWriter序列化前面例子的代碼:
XmlDictionaryCreateMtomWriter(dcs, person);
private static void XmlDictionaryCreateMtomWriter(DataContractSerializer dcs, Person person)
{
//構造用於保存序列化並編碼後的DataContract對象的流
MemoryStream contractDataStream = new MemoryStream();
//新建一個CreateMtomWriter方法構建的指定Unicode的XmlDictionaryWriter對象
XmlDictionaryWriter xdw = XmlDictionaryWriter.CreateMtomWriter(contractDataStream, Encoding.UTF8, 2048000, "text/xml");
//調用WriteObject方法將對象通過XmlDictionaryWriter序列化並編碼
dcs.WriteObject(xdw, person);
//將序列化並編碼後的字節流寫入到原始流對象
xdw.Flush();
contractDataStream.Position = 0;
//為了查看序列化到流中的內容,將流內容讀取出來並用Unicode解碼為字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//將流反序列化為DataContract對象
contractDataStream.Position = 0;
XmlDictionaryReader reader = XmlDictionaryReader.CreateMtomReader(contractDataStream, Encoding.UTF8, XmlDictionaryReaderQuotas.Max);
person = (Person)dcs.ReadObject(reader);
reader.Close();
}
生成的序列化後的數據用UTF8解碼後看:
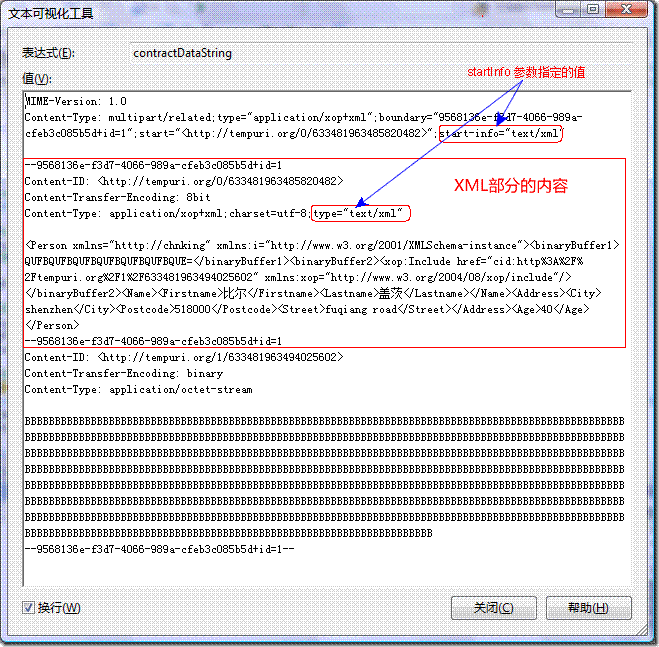
可以看出CreateMtomWriter構造的XmlDictionaryWriter將xml的內容轉成了MIME的形式,下面仔細的分析一下MIME消息的構成。
XmlMtomWriter生成的MIME的消息一般分為三個部分:
l MIME頭
MIME-Version: 1.0 - 表示MIME的版本號
頭部最重要的內容是Content-Type中的一些內容,它們是:
Content-Type: multipart/related – 表示是多部分的消息
type="application/xop+xml" – 表示是xop協議的MIME消息格式
Boundary – 部分之間的邊界,這個值插在不同的部分之間以分割不同的部分內容
Start – 開始的那個部分的Content-ID,每個部分都有一個唯一的Content-ID標識。這裡開始部分就是xml的部分。
l 第一部分(xml部分)
MIME頭部跟第一部分之間有個空行,表示頭部結束後面是部分的內容。
Boundary指定的字符串前面加上”—“字符是部分開始和結束的標識。
每個部分也分header和body部分,以空行分割。
Content-ID: <http://tempuri.org/0/633482733255804248> – 此部分的標識id
Content-Transfer-Encoding: 8bit – 表示body部分的內容可能是非ASCII編碼的編碼內容,這裡xml的內容一般以UTF8或UTF16編碼,使用了每個字節的所有8位。
Content-Type: application/xop+xml;charset=utf-8;type="text/xml" – 表示body的內容類型為xop的xml內容。
Body部分就是xml的內容,重點關注一下二進制數據binaryBuffer2的表現形式。
二進制binaryBuffer1數據部分被直接編碼成base64字符串放在xml中。
binaryBuffer2部分的數據實際上從xml中剝離出來,作為一個單獨的部分存在。看一下在xml中的binaryBuffer2:
<binaryBuffer2><xop:Include href="cid:http%3A%2F%2Ftempuri.org%2F1%2F633482781614236973" xmlns:xop="http://www.w3.org/2004/08/xop/include"/></binaryBuffer2>
其中href=cid:http%3A%2F%2Ftempuri.org%2F1%2F633482781614236973指向表示這部分二進制數據的部分的標識id,實際的二進制數據被放在指向的那個部分。
l 後續部分(二進制數據部分)
沒有被直接放在第一部分xml中的內容都會被放置在隨後的那些部分中,本例中就只有一個binaryBuffer2部分的數據被放置到後續部分。
同樣這個部分有header和body部分,以空行分割。
Content-ID: http://tempuri.org/1/633482781614236973 - 就是xml部分中binaryBuffer2引用的id。
Content-Transfer-Encoding: binary – 表示body部分是二進制的未經編碼的。
Content-Type: application/octet-stream – 內容類型為數據流。
在測試中我們把binaryBuffer2的數據長度設置為768,如果改成767,看看結果:
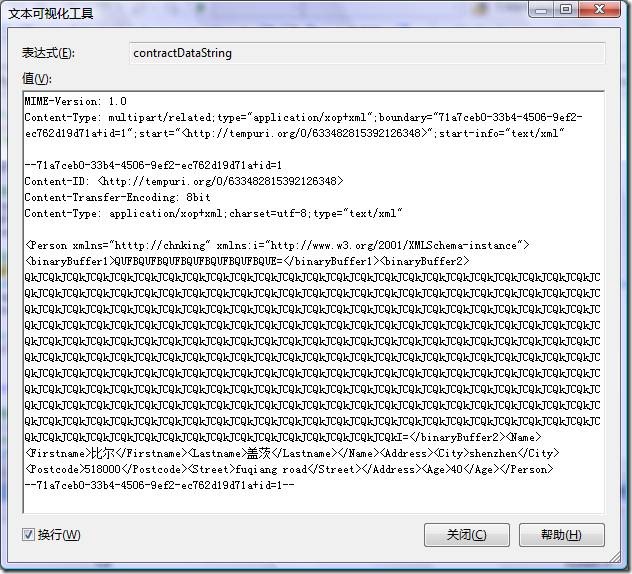
可以發現這時binaryBuffer2的數據也被編碼成base64直接放入到xml中了。
也就是說,CreateMtomWriter構造的XmlDictionaryWriter是根據二進制數據的長度來決定數據如何表現,如果小於768則把數據編碼為base64,如果大於等於768則把數據單獨放到一個部分,並保持二進制數據的原樣。
CreateMtomWriter方法構建的XmlDictionaryWriter寫入器有以下特點:
l DataContractSerializer首先把對象序列化為一個xml 形式的字符串。對於其中的二進制數據,不管多大長度,一律轉成base64編碼的字符串。
l DataContractSerializer把序列化後的xml字符串傳給XmlDictionaryWriter。
(這前兩步跟CreateTextWriter方法構建的XmlDictionaryWriter一樣,其實DataContractSerializer傳到XmlDictionaryWrite的內容是一樣的)
l CreateMtomWriter方法構建的XmlDictionaryWriter寫入器分析DataContractSerializer傳進來的xml的內容,如果包含二進制的內容,則判斷如果二進制的數據大於等於768字節的就把它放到一個單獨部分,如果小於依然保存在xml中。
l MTOM的header和Boundary部分邊界符都使用UTF8編碼,xml部分的編碼由CreateMtomWriter方法中的encoding參數決定,最終將MTOM的內容根據各自的編碼轉換到字節流,保存到一個流對象中,本例中就是MemoryStream。
3.2.3.CreateBinaryWriter方法
DataContractSerializer還提供了一種最高效的序列化方式,二進制序列化,把xml內容直接轉成二進制的數據,不過這樣的轉換是微軟自己的定義的,只能在.net環境下使用,跟別的技術不具有交互性。
看一下用CreateBinaryWriter構造的XmlDictionaryWriter序列化前面例子的代碼:
XmlDictionaryCreateBinaryWriter(dcs, person);
private static void XmlDictionaryCreateBinaryWriter(DataContractSerializer dcs, Person person)
{
//構造用於保存序列化並編碼後的DataContract對象的流
MemoryStream contractDataStream = new MemoryStream();
//新建一個CreateTextWriter方法構建的指定Unicode的XmlDictionaryWriter對象
XmlDictionaryWriter xdw = XmlDictionaryWriter.CreateBinaryWriter(contractDataStream);
//調用WriteObject方法將對象通過XmlDictionaryWriter序列化並編碼
dcs.WriteObject(xdw, person);
//將序列化並編碼後的字節流寫入到原始流對象
xdw.Flush();
contractDataStream.Position = 0;
//為了查看序列化到流中的內容,將流內容讀取出來並用UTF8解碼為字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//將流反序列化為DataContract對象
contractDataStream.Position = 0;
XmlDictionaryReader reader = XmlDictionaryReader.CreateBinaryReader(contractDataStream, new XmlDictionaryReaderQuotas());
person = (Person)dcs.ReadObject(reader);
reader.Close();
}
序列化後的結果是二進制的,不具可讀性,下面試著用UTF8編碼強行把二進制的數據轉成字符串看一下:
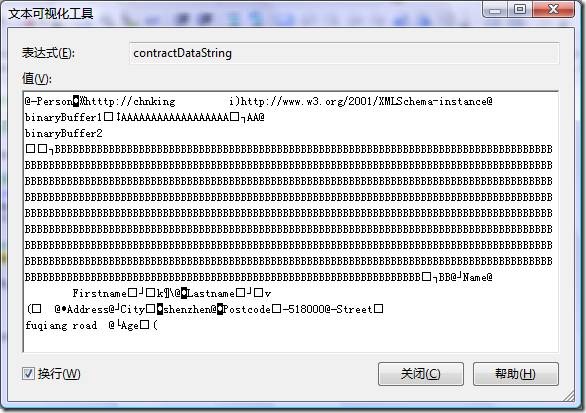
本例中,序列化後的二進制數據長度為1010字節,前面使用CreateTextWriter方法並使用UTF8編碼的序列化後的數據長度為1385。可見二進制序列化後的數據長度最短。
3.3.DataContractSerializer序列化總結
DataContractSerializer本身完成了把要序列化的對象序列化為xml的形式,之後再由不同的編碼方案對這個xml進行編碼,最後形成完全序列化的數據流。
DataContractSerializer實際上提供了四種編碼方案,其中WriteObject(Stream stream, object graph)直接序列化到流和CreateTextWriter方法構建的XmlDictionaryWriter這兩種,是直接把xml字符進行編碼,只是WriteObject(Stream stream, object graph)使用固定的UTF8編碼,CreateTextWriter方法構建的XmlDictionaryWriter可以選擇序列化使用的編碼。
CreateMtomWriter方法構建的XmlDictionaryWriter是把對象的xml編碼為MTOM的形式。
CreateBinaryWriter構造的XmlDictionaryWriter是把對象的xml編碼為二進制的形式。
Xml形式具有最佳的互操作性,適應面最廣。
MTOM的形式適合傳輸含有二進制大數據的對象。
二進制的形式傳輸效率最高,但是不具互操作性,只能用於.net環境的交換。
本文配套源碼