這一篇我們來關注一下搜索。我們同樣把目光放在Array這個最基礎的數據類 型上面。我們從幾個實例來講解怎麼利用.NET的內部機制實現檢索
1. Array.Exists
這個方法是判斷是否在指定數組中存在某個成員。讓我們 來看看這個方法的定義
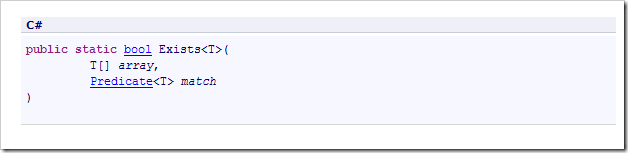
該方法返回一個bool值,這很好理解。它的第一個參數是一個Array, 這也很好理解。(就是我們要搜索的數據源),而第二個參數是一個所謂的 Predicate類型。我們展開來看一下這個東西吧
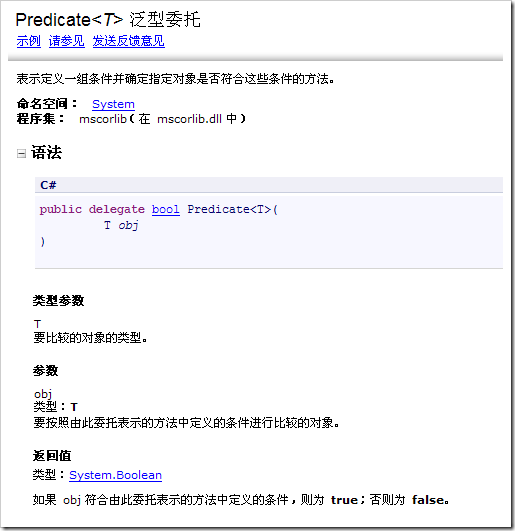
這是一個委托。也就是說它是一個指針,需要我們告訴它如何判斷數 據存在的依據。那麼怎麼給出這個參數呢?
傳統的做法,我們准備一個 方法,這個方法是滿足該委托的簽名的(有一個參數,而且返回一個bool),然 後通過該委托去調用該方法。(假設我們這裡判斷存在的依據是該數字等於2)
static bool MatchInt(int input)
{
return input == 2;
}
然後,在Exists方法中使用委托來調用這個 MatchInt方法去進行判斷。(有兩種寫法)
static void Main (string[] args)
{
int[] numbers = new int[] { 3, 7, 2, 4, 10, 1 };
Console.WriteLine(Array.Exists<int> (numbers, new Predicate<int>(MatchInt)));//這是原始寫法
Console.WriteLine(Array.Exists<int>(numbers, MatchInt));// 這是上面一句代碼的簡寫
Console.Read();
}
從上面的代碼可以看出,為了做這個判斷,我們專門寫了一個方 法,這在很多時候會增加代碼閱讀的麻煩,因為閱讀者需要從一個方法跳到另外 一個方法,不斷反復。
所以,在C# 2.0中,提出了匿名方法的概念,也 就是對於此類不太需要單獨封裝的地方,可以直接將方法體合並在委托聲明中。 也就是說,沒有必要單獨寫MatchInt這個方法。
Console.WriteLine (Array.Exists<int>(numbers, delegate(int i) { return i == 2; }));
這一句代碼就可以完成所有事情了。其實也很直觀。
而在最 新的C# 3.0中,針對這這種問題,又有了改進,就是所謂的Lambda表達式,大家 來看一下代碼是如何寫的
Console.WriteLine (Array.Exists<int>(numbers, i => i == 2));
你可能一下子 還不理解Lambda,但只要大致看一下C# 3.0的新語法例子,其實還是比較通俗的 。
如果有興趣的朋友,可以通過IL代碼看到,第二種方式和第三種方式其實是 一模一樣的。匿名方法和Lambda是語言之上的改進,編譯的結果還是需要通過 delegate來實現的。你也可以說,它們與第一種沒有根本區別。
但在事 實上,他們確實更加直觀和簡潔。
2. Array.Find, Array.FindLast
如果我們需要搜索一個數組中的某個元素,而不光是判 斷它是否存在。我們大致的寫法如下
Console.WriteLine (Array.Find<int>(numbers, i => i == 2));
注意,如果找到 了,則返回2這個數值。Find方法是找到一個即停止。而如果要找最後一個匹配 的值,就需要用FindLast
3. Array.FindAll
這個方法是搜索所有 匹配的數據,返回一個數組。
int[] foundnumbers = Array.FindAll<int>(numbers, i => i % 2 == 0);//搜索所有的偶數
foreach (var item in foundnumbers)
{
Console.WriteLine(item);
}
有意思的是,上面的代碼可 以簡寫為下面一句代碼
Array.ForEach<int> (Array.FindAll<int>(numbers, i => i % 2 == 0), i => Console.WriteLine(i));
4. Array.FindIndex, Array.FindLastIndex
這個方法是檢索相應的值在數組中的索引號
Console.WriteLine(Array.FindIndex<int>(numbers, i => i == 1));
Console.WriteLine (Array.FindLastIndex<int>(numbers, i => i == 1));
5. Array.BinarySearch
上面的Find方法,基本上都 是基於順序的。也就是,如果某個數字很不湊巧在最後面,那麼搜索程序就不得 不將每個數字都檢查一次,比較他們。這樣,在很多時候效率是不夠高的。當然 ,如果數據本身沒有規律,是隨機分布的,這也是無法避免的。
如果說 數據本身有順序,那麼就可以利用二進制搜索來提高速度。二進制搜索其實是一 個折半搜索算法。也就是說,既然數據本身有順序,就可以不要一個一個比較, 而是可以在某個范圍內比較
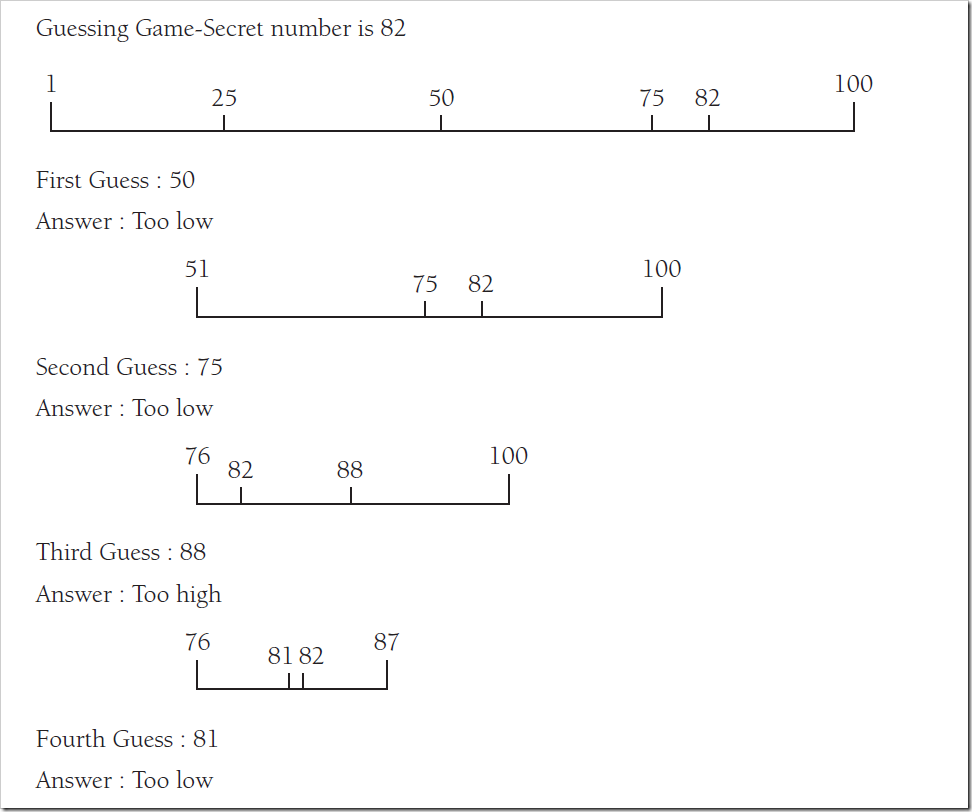
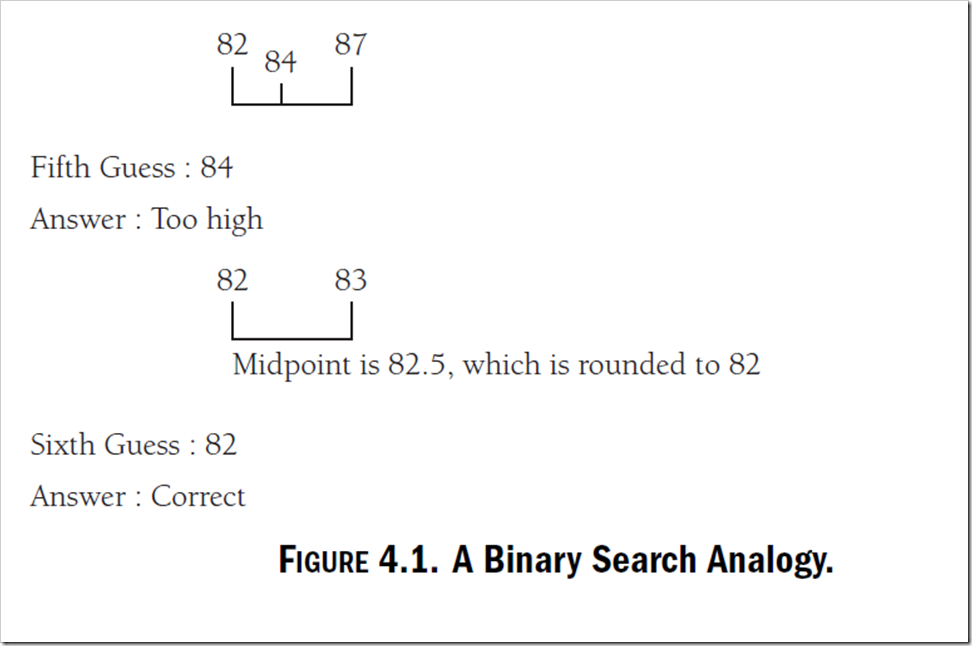
從這個原理可以知道,二進制搜索是依賴數據本身排序的。事實上,如果數 據沒有排序,則該方法也不會出錯,但是會返回一個負數或者一些奇怪的結果。
我們用例子來比較一下二進制搜索和順序搜索的差別
static void Main(string[] args)
{
//准備一個數組,隨機填充10000000個數字
int[] numbers = new int[10000000];
Random rnd = new Random ();
for (int i = 0; i < numbers.Length; i++)
{
numbers[i] = rnd.Next (10000000);
}
//采用順序搜索的方 式,查找裡面100這個數值(如果運氣比較好,正好有100的話)
Stopwatch watch = Stopwatch.StartNew();
Console.WriteLine(Array.Find<int>(numbers, i => i == 100));
watch.Stop();
Console.WriteLine("順序搜索使用的時間為:{0}毫秒", watch.ElapsedMilliseconds);
//采用二進制搜索的方 式,查找裡面100這個數值
watch.Reset();
watch.Start();
Array.Sort<int>(numbers);//先排序
watch.Stop();
Console.WriteLine("排序 的