目錄
托管異常處理
線程基礎和未處理托管異常
CLR 創 建的線程的未處理托管異常
非 CLR 創建的線程的未處理異常
未 處理異常處置
AppDomain.UnhandledException 事件通知
未來關注點
不應該將未處理異常的處置神秘化。實際上,了解在此過程中所發 生的一切是非常有用的,因為它可以使崩潰的應用程序能夠根據最後一刻的日志 內容進行診斷,以確定究竟是哪裡出現了問題。此診斷信息非常有價值,可使您 節省確定故障所需的時間。
那麼,什麼是未處理異常處置呢?它是常規 異常處理機制的一個階段,只有在對線程的所有堆棧幀都執行了異常處理程序搜 索但仍未發現任何異常後,才會針對異常觸發這一機制。
在這裡,我將 介紹對於托管異常的未處理異常處置,CLR 是如何實現的。但是,在進行詳細介 紹之前,我們要先看一看托管異常處置通常是如何工作的。請注意,這裡假設您 對 Windows® 結構化異常處理 (SEH) 機制以及相關的概念都已經非常熟悉 。要了解更多相關信息,您可以參考 Matt Pietrek 撰寫的一篇非常不錯的文章 "A Crash Course on the Depths of Win32 Structured Exception Handling",網址為 microsoft.com/msj/0197/Exception/Exception.aspx 。
托管異常處理
托管編程模型使用異常概念來通知堆棧上層的調 用方有關運行時的錯誤情況。通常,某個方法的調用方會很清楚此方法可能拋出 (或引發)的異常類型,因此會相應地從帶有關聯 catch 塊的 try 塊范圍內或 帶有處理程序塊的托管篩選器內進行調用。
如果托管代碼拋出異常(或 引發異步異常,如同不安全托管代碼中的訪問沖突一樣),CLR 將開始從它找到 的與異常點最接近的第一個托管幀來遍歷托管堆棧,並開始查找托管異常處理程 序。
除非另有說明,否則堆棧將減少,每行代表一個托管幀,它會調用 其下面的幀。如果托管幀調用本機幀,則本機幀將被顯式調出。最頂端的幀是入 口點幀,最底端的幀是最近執行代碼的幀。
圖 1 是一個此類調用堆棧示 例。在這裡,Bar 拋出了一個異常,這使得 CLR 開始從 Bar 遍歷托管堆棧並一 直到 Main,同時查找異常處理程序。在本例中,Main 充當有問題的線程的入口 點托管幀。

圖 1 Bar 拋出異常
圖 2 中的圖表顯示了另一個調用堆棧,其中 Bar 中 的托管代碼將使用 P/Invoke 來調用本機函數 Nfunc,此函數將拋出一個異常( 例如,拋出 C++ 異常)。由於異常發生在本機代碼內,因此 CLR 不會意識到它 的存在,除非該異常沒有被本機函數捕獲,並進而進入托管 Bar 方法。在這種 情況下,CLR 將創建與本機異常相對應的托管異常對象,並會從包含 Bar 的幀 開始查找異常處理程序,一直到 Main 方法。
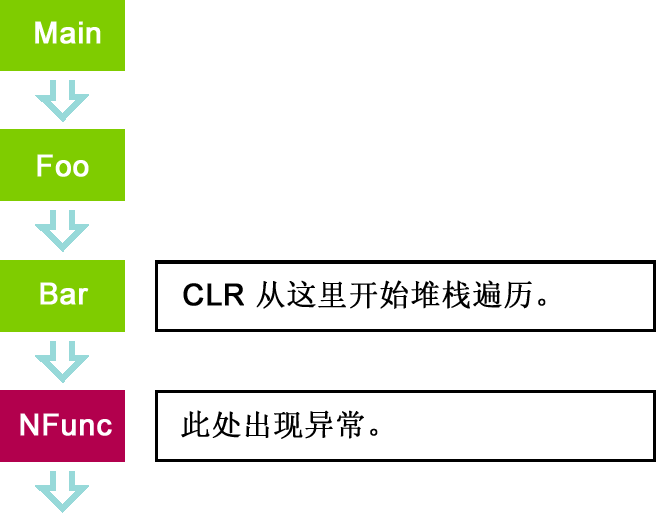
圖 2 Nfunc 拋出異常
在這兩個示例中,異常處理程序可以是根據類型匹 配規則與拋出異常的托管類型相匹配的 catch 塊,也可以是同意在對 CLR 傳遞 過來的異常對象進行檢查之後對異常進行處理的托管篩選器。
對於此示 例,我們假定 Main 有一個 catch 塊來處理異常。在發現異常之後但在其內部 恢復執行之前,CLR 將發起異常解除操作(在 SEH 術語中也稱為第二階段), 從引發異常的點一直到同意處理異常的異常處理程序之前的一點來調用 finally 子句。對於托管幀,這還會導致對 fault 子句的調用(如果它們存在)。有關 fault 子句和托管異常通常處理的具體信息,可參閱 ECMA 335 規范(請參見 go.microsoft.com/fwlink/?LinkId=121873)。
在一些典型情況下, finally/fault 塊會執行並完成所需的清理工作。所有此類塊被執行完畢後, CLR 會繼續在同意處理異常的 catch 塊(或托管篩選器的處理程序塊)中執行 。
線程基礎和未處理托管異常
在前面的示例中,我將 Main 定義 為線程的入口點托管幀,換言之,它是線程將要執行的第一個托管幀。如果在其 中未找到托管異常處理程序,CLR 會繼續觸發其未處理異常處置。此未處理異常 處置的觸發方式與線程的創建方式有關。讓我們對此主題進行深入探討。
可以運行托管代碼的線程分為兩類。一類是 CLR 創建的線程,對於此類 線程,CLR 將控制線程的基礎(起始幀)。圖 1 和 2 中所示的堆棧就是這種情 況的一個示例。圖 3 顯示的是此類線程的實際堆棧(當它在 CLR 中開始時)。
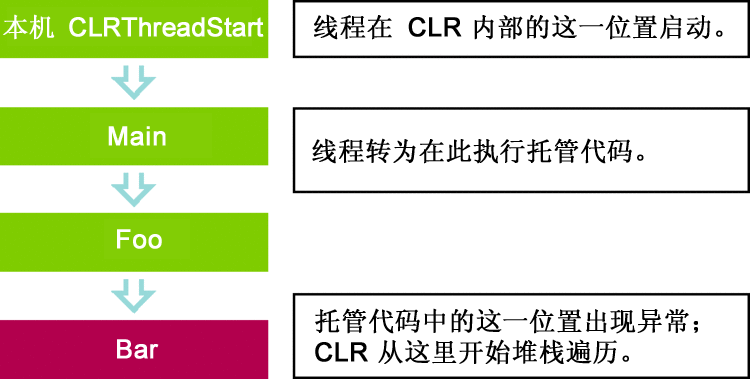
圖 3 CLR 創建的線程
還有一類是在 CLR 外部創建但可以在以後進入以 執行托管代碼的線程;對於此類線程,CLR 不控制線程基礎。圖 4 中的圖表展 示的就是這種情況。
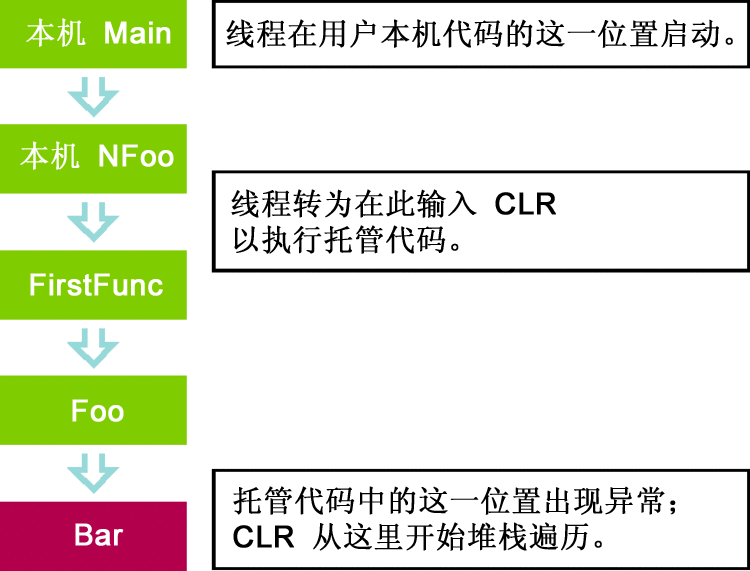
圖 4 在 CLR 外部創建的線程
CLR 創建的線程的未處理托管異常
對於圖 3 的情況,如果 CLR 無法在 Main 中找到托管異常處理程序,則異常將 到達 CLR 內線程開始處的本機幀。在此幀中,CLR 建立了一個異常篩選器,它 將應用策略以抑制(從語義上講相當於盲目捕獲)異常(如果適用)。如果策略 指示不抑制異常(Microsoft® .NET Framework 2.0 及更新版本中的默認設 置),則篩選器將觸發 CLR 的未處理異常處置流程。
此時,您可能希望 知道哪種類型的線程屬於圖 3 中所示的情況以及異常抑制策略是什麼。第一個 問題的答案很簡單:使用 System.Threading.Thread 類創建的任何托管線程都 屬於此類別。此外,Finalizer 線程和 CLR 線程池線程也屬於這一類別。唯一 的例外情況是在默認域中創建的托管線程。盡管此類線程會檢查異常抑制策略, 但從觸發未處理異常處置流程的角度看,它仍遵循與圖 4 中的線程相同的模式 (假設異常未被抑制)。
要給出第二個問題的答案需要對異常處理的歷 史有一些了解。對於 .NET Framework 1.0 和 1.1,在 CLR 中所創建的線程的 未處理異常是在線程基礎(換言之,也就是線程在 CLR 中啟動時所在位置的本 機函數)處被抑制的。以前,此行為可能會剛好相反,因為 CLR 沒有任何有關 最初引發異常的原因的線索。因此,抑制堆棧中的任何托管幀都不想處理的異常 是一個錯誤,因為應用程序或進程狀態的損壞程度都無法確定。
如果異 常是那種能夠指示損壞的進程狀態(如訪問沖突)的異常,情況將會怎樣呢?除 非您使用的是不安全托管代碼,否則抑制此類異常沒有任何意義。最重要的是, 抑制異常會向開發人員隱藏應用程序中所發生的錯誤。
有鑒於此,在 .NET Framework 2.0 中對此行為做了改動。由 CLR 創建的線程的未處理異常不 再被抑制。如果異常未通過堆棧中的任何托管幀進行處理,則 CLR 會在觸發未 處理異常進程後讓其以未處理狀態進入 OS。然後此未處理異常會導致應用程序 崩潰,而崩潰的詳情會幫助開發人員了解故障根源。
但是,由於針對 CLR 1.0 和 1.1 構建的某些應用程序依靠抑制未處理異常的原始行為,而隨後 的行為在 CLR 2.0 中不會像預期那樣工作,故此引入了一個標志,它可以在應 用程序配置文件的運行時部分進行設置,如下所示:
<legacyUnhandledExceptionPolicy enabled="1"/>
設置完成後,異常將會像在 CLR 1.0 和 1.1 中一樣被抑制。這將構成 CLR 的異常抑制策略。如果未應用此策略 ,CLR 將繼續觸發未處理異常處置。
然後,正像您可以推斷出來的那樣 ,未處理異常將能夠幫助您更好地了解崩潰的原因。實際上,這還向您指出了使 用類似 catch(Exception ex) 模式的不利之處,因為它們意味著您將會捕獲所 有托管異常,這在語義上類似於 CLR 在版本 1.0 和 1.1 中所實現的效果。應 將此類模式替換為那些更加具體的異常類型,並應盡可能靠近異常源。捕獲異常 時距離引發異常的點越遠,您能夠獲得的有關異常原因的上下文就越少。
非 CLR 創建的線程的未處理異常
圖 4 說明的是在 CLR 外部創 建了線程,然後進入其中執行托管代碼。在該例中,如果異常在 FirstFunc 方 法中也沒有得到處理,則異常將退出 CLR,但會繼續作為本機 SEH 異常傳播到 堆棧(托管異常都被表示為本機 SEH 異常)。此傳播由 OS 執行,並且 OS 會 查找異常處理程序。此類線程的示例包括入口點線程(使用指向某個委托的指針 來調用托管代碼的本機線程)、使用 COM interop 或 CLR 宿主 API 的本機線 程。
在本例中可能會發生兩件事情。第一,OS 可能會在用戶(或 CLR) 代碼中一個本機幀中找到 SEH 異常處理程序。這將導致 SEH 異常處理的第二階 段運行 finally 子句(從引發異常的幀一直到同意處理異常的異常處理程序之 前的一點)。該步驟完成後,將在捕獲該異常的異常處理程序(例如 catch 子 句)中恢復執行。使用宿主 API 或 COM interop 進入 CLR 以執行托管代碼的 本機線程屬於這一類。
第二個可能的結果是 OS 找不到 SEH 異常處理程 序(即使在用戶代碼的最頂端本機幀中)。如果發生這種情況,異常將被認為是 未處理異常,OS 將觸發其自己的未處理異常處置機制,該機制控制的 CLR 將隨 之觸發其未處理異常處置。如本機線程使用從 Marshal.GetFunctionPointerForDelegate 托管 API 獲取的指針來調用托 管委托,且該委托不受任何本機異常處理保護,則屬於這一類。
OS 未處 理異常篩選器 (UEF) 機制並非總會觸發 CLR 的未處理異常處置。在對此進行說 明之前,讓我們先來看一看 OS 的 UEF 機制的工作原理。
未處理異常處置
Windows 中有一種機制,可以注冊整個進程范圍內的回調(稱為 UEF ),進程中的任何線程只要有未經處理的任何類型的異常,OS 便會調用此機制 。
此回調可使用 SetUnhandledExceptionFilter Windows API 進 行注冊。當進程中的某個組件注冊其回調時,OS 會返回向其注冊的上一個回調 的地址(如果沒有回調,則返回 NULL)。請注意,這意味著 OS 僅跟蹤最新注 冊的 UEF 回調。
如果回調確定其無法處理異常,則獲得該回調的組件應 調用之前注冊的回調(使用 OS 在應用 SetUnhandledExceptionFilter 時 返回的指針)。同樣,該回調應調用其前身,依此類推。
這一調用之前 注冊的回調的過程被稱作未處理異常篩選器的後向鏈接。從本質上講,此鏈接非 常脆弱,因為如果鏈接中的某個組件沒有後向鏈接(或者,此過程終止),則此 鏈接很容易地就會被斷開。對於 CLR 的未處理異常處置,這存在著重大的隱患 。在 CLR 初始化時,它同時也會向 OS 注冊其 UEF 回調,目的是希望當某個托 管異常在 CLR 外部創建的線程中未得到處理時,能夠調用此回調。
正常 情況下,這會按照所預期的那樣發生,CLR 的未處理異常處置將會被觸發。但在 某些情況下,這可能不會發生。其中一種情況是當托管代碼對向 OS 注冊其 UEF 回調的本機組件進行 P/Invoke 調用時。假設 CLR 是在本機組件之前最後一個 注冊 UEF 回調的項目,則此組件將取得 CLR 回調的地址。現在,當某個異常在 線程中未得到處理時,OS 將調用本機組件的 UEF 回調(因為它是最新的注冊) 。如果此組件沒有回調 CLR 的 UEF 回調(使用 OS 為其提供的指針),則 CLR 的未處理異常處置將不會啟動。
還有另外一種不會觸發 CLR 未處理異常 處置的情況,即本機組件注冊其 UEF 回調,然後加載 CLR(通過 COM interop 或顯式通過 CLR 宿主)。在這種情況下,CLR 將觸發其 UEF 回調並保存原始回 調。
如果某個異常得不到處理而 OS 又調用了最頂端 UEF,它將結束調 用 CLR 的 UEF 回調。發生這種情況時,CLR 的行為就像一個好市民一樣,會首 先後向鏈接到在其之前注冊的 UEF 回調。此外,如果原始 UEF 回調的返回結果 指出它已對異常進行了處理,則 CLR 將不會觸發其未處理異常處置。因此,如 果您看到 CLR 的未處理異常處置未被觸發,則很可能是遇到了這兩種情況中的 一種。
至此,您已經了解了執行托管代碼的線程的基礎是如何影響 CLR 未處理異常處置的觸發方式的。但是,在 CLR 未處理異常處置過程中都會發生 哪些情況呢?從本質上看,該過程分為三個部分,我將在隨後加以解釋。但從較 高層次來看,此過程會向崩潰的應用程序發出通知,說明未得到處理的異常,而 且 CLR 會觸發一些機制來記錄相關故障信息。
AppDomain.UnhandledException 事件通知
AppDomain 類提供了 一個被稱作 UnhandledException 的事件。當某個異常在執行托管代碼的 線程中未得到處理,並且 CLR 的未處理異常處置被觸發時(“並且 ”是這裡著重強調的關鍵字,因為我之前介紹過,在一些情況下可能根本 不會觸發它),將觸發此事件
此事件始終針對默認域引發。此外,如果 線程是在 CLR 中的非默認 AppDomain 中創建的,則此通知也會被遞送到該 AppDomain 中。
當 CLR 的未處理異常處置被觸發時,此進程將會很快終 止,因為異常在整個線程的堆棧中始終未得到處理。因此,這是對錯誤根源執行 某種記錄的最後機會。事件處理程序會獲取與未處理異常有關的異常對象,以便 使用它來進行故障診斷。圖 5 中的代碼將注冊並使用此通知。
圖 5 注冊通知
class Program
{
static void Main (string[] args)
{
AppDomain.CurrentDomain.UnhandledException += new
UnhandledExceptionEventHandler(CurrentDomain_UnhandledException);
throw new Exception("This will go unhandled");
}
static void CurrentDomain_UnhandledException(object sender, UnhandledExceptionEventArgs e)
{
Exception ex = (Exception)e.ExceptionObject;
Console.WriteLine ("Observed unhandled exception: {0}", ex.ToString());
}
}
接下來,CLR 將收集與未處理異常有關的托管存儲桶 的詳細信息,並將其寫入事件日志(在應用程序日志下),如圖 6 所示。
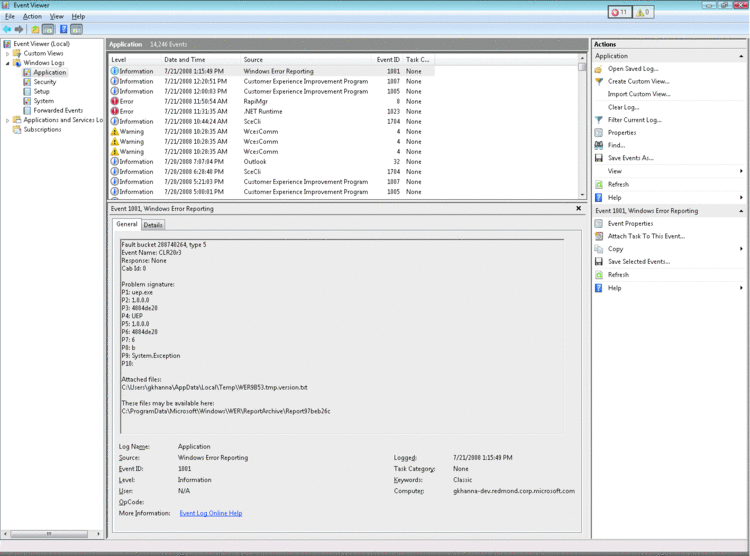
圖 6 事件日志中的異常
存儲桶存儲是根據故障點將應用程序的故障進行 分組的進程。對於未經處理的托管異常,它采用 CLR 收集的九條詳細信息,這 些信息與未經處理的托管異常相關。這些統稱為 Watson 存儲桶,在托管代碼的 上下文中,它們將包括一些詳細信息,例如導致故障發生的模塊的名稱、發生故 障位置處的中間語言 (IL) 偏移量,以及故障所在方法的 MethodDef 等(有關 詳細信息,請參閱 ECMA 335 規范)。例如,存儲桶 P4 描述出錯模塊、存儲桶 P9 顯示未經處理異常的類型、存儲桶 P8 代表最初拋出異常的位置處的 IL 偏 移量。
圖 7 顯示的是引發未處理異常的托管方法的反匯編,最終會形成 圖 6 所示的存儲桶詳細信息。您將會看到圖 6 中的 IL 偏移量 (P8) 將與圖 7 中引發異常的位置處的 IL 偏移量相一致。
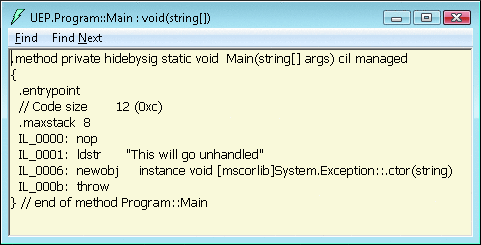
圖 7 反匯編方法
在這裡要牢記,存儲桶中的信息對應的是被拋出且未經 處理的最後一個托管異常。此聲明非常重要,因為這些異常可能會被重新拋出, 或打包成被拋出且未經處理的新異常的一個內部異常。最初它們本來也可能會在 過渡線程的非默認 AppDomain 中被拋出。
在前兩種情況下(重新拋出或 打包為內部異常),它將成為重新拋出或新異常拋出的 IL 偏移量,以供存儲桶 存儲時使用。我提及的第三種情況有些特殊,因為它基於這樣一個事實,即在一 個 AppDomain 中創建的對象不能在另一個 AppDomain 中使用,除非它們已進行 封送處理(CLR 轉換對象的一種方式,可以跨越 AppDomains 等各種邊界 使用)。因此,如果 AppDomain 中拋出的異常一直未得到處理並已到達 AppDomain 轉換邊界,則 CLR 會將異常對象從引發異常的 AppDomain 封送到最初進行調用的 AppDomain,並使用經過封送處理 的異常對象來引發異常。
這樣一來,P8 存儲桶中的 IL 偏移量將屬於發 現異常的調用 AppDomain 中的第一個托管幀。簡單地說,這通常是對線程啟動 AppDomain 轉換的方法中的偏移。
CLR 宿主可以通過使用 ICLRErrorReportingManager::GetBucketPara metersForCurrentException 宿主 API 來檢索線程中當前異常的存儲桶參數。
最後,您在此時通常會看到一個對話框,提示您調試或關閉應用程序。 單擊“關閉程序”會終止此進程,而單擊“調試”會啟動 托管的實時 (JIT) 調試器,它在HKLM\Software\Microsoft\.NetFramework注冊表項下的 DbgManagedDebugger 項中指定。
在 CLR 的未處理異常進 程的最後步驟中,CLR 將嘗試在標准錯誤控制台上顯示與未經處理的異常有關的 詳細信息。通常,您將會看到托管堆棧跟蹤轉儲。
如果異常較為嚴重( 如 StackOverflowException 或 OutOfMemoryException),則會在堆棧轉 儲位置顯示一個簡單的字符串。之所以這樣做,是因為您可能沒有足夠的堆棧來 執行,或者沒有足夠的內存來構成大量的堆棧跟蹤來顯示在控制台上。如果 CLR 在此情況下不夠小心,可能會陷入遞歸異常的窘境。此進程完成後,CLR 的未處 理異常處置機制會將控制權返還給其調用方(可能是 OS 或 CLR 本身)。
未來關注點
本專欄基於 .NET Framework 2.0 附帶的 CLR 版本 ,因此可能涉及了幾項可能會在未來有所改變的實現細節。但是,我這裡想達到 的目的並不是讓您關注具體的實現,而是想幫您盡量了解未處理異常處置的概觀 。
現在您應已了解了未處理異常處置的構成、其依賴關系以及它與 OS UEF 機制的關系。這裡介紹的知識可幫助您在應用程序中為可能遇到的任何意外 故障設計出更出色的異常處理策略和診斷機制。
請將您想詢問的問題和 提出的意見發送至 clrinout@microsoft.com。
Gaurav Khanna 是 Microsoft CLR 團隊的軟件開發工程師,負責處理托管異常處置實現和 CLR 宿 主。