關於內存模型, 這實在是個被說爛了的話題. 五六年前剛剛接觸到.NET的時候 , 各路大牛就開始討論了. 還記得那時候每每帶著無比崇敬的心去閱讀那些文字 和思想. 之後每每回頭去重讀那些文字,更感覺收獲頗多. 可是大牛們往往言語頗 為簡概, 所以盡管讀的次數多, 但是多數成為時間和差記憶力的受害者屢屢忘記. 所以最近下定決心, 寫這樣一篇博文, 匯總各路豪傑之思想, 聚集近幾年之結論, 加上筆者一點微不足道的收獲, 務求准確翔實, 希望圖文並茂. 程序員幫程序員, 大家互助.是為題記.
不知道作為程序員的您想過沒有, 如果CPU不是按照您的程序寫那樣的順序 (Programming Order)執行, 結果會是怎樣的? 如果您以前沒有意識到這一點, 您 可能會比較震驚. 但在進入多核心多處理器時代之後,事實上就是這樣的, CPU會 調整指令執行的順序, 並以調整後的順序(Processer Order)來執行指令. 這是提 高CPU執行效率的重要措施.
除了極少數人比如.NET框架的設計者們在很早的時間就遇到了這個問題, 撇開 C++/JAVA程序員們不談, 我猜測很多.NET程序員首次意識到這個問題, 應該是當 Double-Check遇到了單例模型的實現:
Imperfect Singleton Implement
1. public class Singleton
2. {
3. private static object syncRoot = new object();
4. private Singleton instance;
5.
6. private Singleton() { }
7.
8. public Singleton Instance
9. {
10. get
11. {
12. if (instance == null)
13. {
14. lock (syncRoot)
15. {
16. if (instance == null)
17. {
18. instance = new Singleton ();
19. }
20. }
21. }
22.
23. return instance;
24. }
25. }
26. }
這個實現有一點點瑕疵. 在多核心CPU上, 存在這樣一種可能. 兩個CPU核心同 時執行Instance這段代碼. 當Processer0執行到釋放鎖的時候, 由於CPU高速緩存 (Cache)和寫緩存(Store Buffer)的存在, 主內存中可能Singleton對象還沒有被 創建. 當Processer1執行到instance==null的判斷時依然為真, 然後另外一個 Singleton對象也被表明需要創建. 這樣當所有寫操作完成後, 這個單例模型實際 上給出了兩個完全不相干的Singleton對象!
A Better Singleton
1. public class Singleton
2. {
3. private static object syncRoot = new object();
4. private volatile Singleton instance;
5.
6. private Singleton() { }
7.
8. public Singleton Instance
9. {
10. get
11. {
12. if (instance == null)
13. {
14. lock (syncRoot)
15. {
16. if (instance == null)
17. {
18. instance = new Singleton ();
19. }
20. }
21. }
22.
23. return instance;
24. }
25. }
26. }
一個改進後的實現, 只是在單例內部維護的Singleton私有實例前面加 了"volatile"關鍵字. Volatile關鍵字有什麼奇妙的作用呢? MSDN給出這樣的解 釋:
"The volatile keyword indicates that a field might be modified by multiple threads that are executing at the same time. Fields that are declared volatile are not subject to compiler optimizations that assume access by a single thread. This ensures that the most up-to-date value is present in the field at all times."
Volatile的這段解釋最主要的意思是: 標有Volatile的字段將編譯器認為是多 線程代碼, 從而不會執行優化; 這保證內存中字段的值總是最新的.
那麼, 真的是這樣麼? 是不是使用了Volatile關鍵字之後, 單例模型就完全沒 有問題了? 有比Volatile更好的實現麼? 探究問題的根本, 要從現代CPU的結構上 談起.
名詞解釋
舊/前 - 對編程順序而言, 較前的語句/操作
新/後 - 對編程順序而言, 較後的語句/操作
Load/Read - CPU讀操作, 是指將內存數據加載到寄存器的操作過程.
Store/Write - CPU寫操作, 是指根據CPU指令, 將修改過的數據回寫主存儲器 的操作過程.
Load.Acquire - 含有Acquire語義的讀操作. 相當於一個單向向後的柵障. 普 通的讀和寫操作可以向後越過該讀操作, 但是之後的讀和寫操作不能向前越過該 讀操作.
Store.Release - 含有Release語義的寫操作. 相當於一個單向向前的柵障. 普通的讀和寫可以向前越過該寫操作, 但是之前的讀和寫操作不能向後越過該寫 操作.
Full Fence - 全向柵障. 任何讀寫操作都不能跨越該柵障.
Cache - CPU封裝的高速緩存. 在現代CPU當中, 一般會設置多級緩存(比如從 L1到L3等), 多級緩存有不同的訪問速度. Cache按照封裝分有兩種, 一種是與每 個CPU核心封裝在一起並被其單獨占有的, 另一種是幾個CPU核心共享的. 在不 影響本文分析的基礎上, 筆者使用Cache一詞統稱CPU當中每個邏輯CPU核心獨享的 緩存. 另因Store Combine Buffer亦不影響本文分析, 保留了Store Buffer之後, 同樣省去Store Combine Buffer.
Cache Line - 對應於內存中不同的數據邊界大小,Cache根據不同的固定尺 寸分成一些大小(Boundary)不等的存儲空間, 這些存儲空間叫做Cache Line.
現代CPU內存操作基本邏輯結構
CPU發展到今天存在3中基本的架構: x86, AMD64(x64), IA-64. 我們知道CPU 中都會有計算單元, 寄存器, 指令控制器, 多級緩存, 寫緩沖等復雜各種功能部 件, 但是這跟本文的內存模型無關, 本文也不打算介紹這些實現的細節. 為了簡 化討論, 我們省去多級緩存的結構來用緩存統稱緩存結構(多級緩存機制不會影響 內存模型的討論), 省去計算單元/寄存器/指令控制器來用一個單獨的PU單元來代 替, 省去CPU中的其他部分但是保存了Store Buffer. 這樣這3類架構的CPU的基本 內存操作工作邏輯結構, 都可以標示為如圖. 圖中左側是CPU的兩個核心. 每個核 心單獨持有獨立的緩存和寫緩沖區.額外提一句, MSDN Magazine上Vance Morrison老師的Store Buffer的畫法值得商榷.
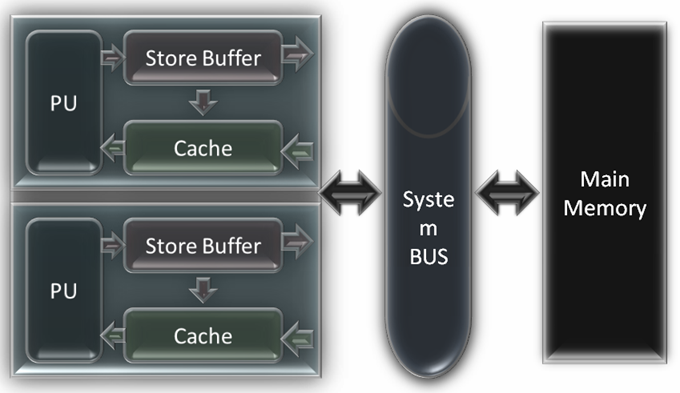
那麼在這個模型下, CPU是如何完成讀和寫的呢? 在不考慮Memory Reordering 的情況下, 一般的過程是:
讀取: 首先在當前的Cache中查找, 如果Cache命中(Cache中含有對應地址的緩 存項), 那麼直接從緩存中返回該內容; 如果cache未命中(cache中沒有對應地址 的緩存項), 那麼向總線發出讀請求, 獲得總線令牌後, 讀取主存儲中對應地址及 其周圍的內容, 添加到緩存中, 並從緩存返回對應地址的內容.
寫入: 首先寫操作壓入Store Buffer隊列, 然後根據指令控制器中指令的 Process Order檢查後續的讀操作.如果後續操作中有對同一地址的讀操作, 那麼 更新對應cache中的項. 最後在某個合適的時候, 向總線發出寫請求, 獲得總線令 牌後, 將Store Buffer中緩存的寫操作的結果寫入主存儲器.
Memory Reordering
嚴謹的講, 這個標題更應該是Memory Access Reordering, 即指對CPU而言, 內存訪問指令重新排序. 這對CPU效能來說是個關鍵的軟件因素. 在核心頻率外頻 位寬等這些硬件條件一定時, 內存的訪問方式直接決定了CPU的整體效能. 因為 CPU訪問高速緩存的速度大概是訪問主存的100倍, 所以更好的內存訪問方式, 更 高的高速緩存命中率, 會大大的提高CPU的性能. 統計數據證明, 訪問高速緩存失 敗(從而不得不訪問主存)的代價, 大概是訪問主存失敗(從而不得不訪問外存例如 硬盤)的10倍.
Memory Reordering定位於為優化CPU及總線效能而進行的內存訪問指令再排序 . 它一定會有一個度 - 稱為Memory Model - 來平衡兩個極端:
A. 內存訪問指令嚴格按照編程順序執行, 即不排序. CPU不能從Memory Ordering獲得任何好處. 但是程序會比較容易編寫, 因為程序本身定義了內存訪 問的順序.
B. 內存訪問指令自由重新排序. CPU自由按照最大的效能原則重新排序內存訪 問順序, CPU和總線效能得到最大發揮. 但是你根本無法為這樣的CPU編寫程序, 因為CPU不保證任何事情. 比如, 你寫了這樣一個程序, i = 1; i ++; 得到的i可 能是0, 可能是1, 也可能是2.
辯證的說, 正確性是第一位的需求, 效能是 第二位的需求. Memory Model的具體實現在兩者之間搖擺, 偏近極端A的實現, 我 們稱為強模型(strong model); 向極端B的方向靠攏(相對於前一種實現)的實現, 我們稱其為弱模型(weak model). 從CPU架構的3大類來講, x86架構和AMD64架 構上的內存訪問模型, 都是強內存模型. IA-64架構上的內存訪問模型, 是弱內存 模型.
AMD64內存模型 - 規規矩矩的實現
因為X86架構的內存模型 原則和實現同AMD64內存模型的原則和實現極為相近, 剝離AMD64文檔上無礙我們 討論的新特性之後, 可以只討論AMD64的內存模型, 並以此來代表x86方面的討 論.
AMD64內存模型多核心實現的原則是:
讀操作不能被重排序到更 舊的讀操作之前 Loads do not pass previous loads (loads are not re- ordered).
寫操作不能被重新排序到更舊的寫操作之前 Stores do not pass previous stores(stores are not re-ordered)
寫操作不能被重新 排序到讀操作之前 Stores do not pass loads
寫操作可以看成是按照編 程順序提交主存更改的, 但是由於寫緩沖的存在, 這個提交過程可以滯後.Stores from a processor appear to be committed to the memory system in program order; however,stores can be delayed arbitrarily by store buffering while the processor continues operation.
讀操作可以重新排序到對不 同主存地址的寫操作之前 Non-overlapping Loads may pass stores.
寫操作可以被外部邏輯CPU以不同順序觀察到. Stores to different locations in memory observed from two (or more) processors may be interleaved in different ways for different observers.
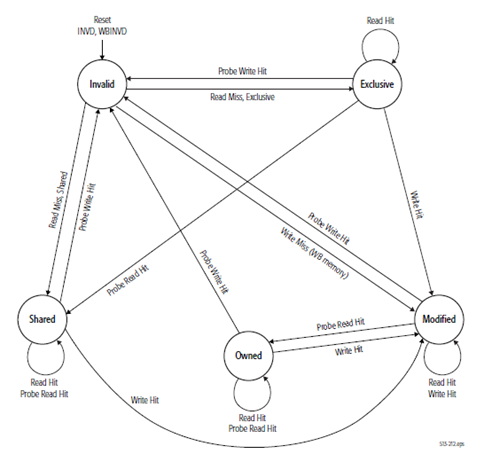
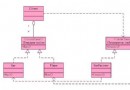
這個內存模型是比較嚴格的. 而且對於Store Buffer的問題, AMD文檔 給出了Memory Coherency and Protocol的保證, 即一個邏輯CPU核心內的Store Buffer中排隊的寫操作, 是可以被動地被其他CPU觀察到, 或者主動向其他CPU核 心廣播該緩存的寫操作對應的主存位置的緩存項無效. 有關這一章節, 可以具體 參看AMD64規范的7.3章節. 緩存一致性的幾個狀態轉換的示意圖如右:
所 以綜合這些原則以及AMD64對於Store Buffering的處理, AMD64的內存模型基本表 現為可以認為是按照編程順序執行的. 除了對於程序中多線程共享數據需要加上 必要的同步機制之外, .NET程序員們應該不需要細致的考慮到如此底層的實現細 節上.
IA-64內存模型 - 要命的Store Buffer
Intel的規格文檔 <Intel® 64 and IA-32 Architectures Software Developer’s Manual - Volume 3A:System Programming Guide, Part 1>的第八章第2節, 對於IA-64的內存模型, 以及內存訪問重新排序的原則和實現有比較詳細的介紹. 限於篇幅只摘抄並翻譯單處理器內存訪問排序的原則:
• 讀操作之間 不能重新排序 - Reads are not reordered with other reads.
• 寫操作不能跟舊的讀操作排序 - Writes are not reordered with older reads.
• 主存寫操作不能跟其他的寫操作排序 - Writes to memory are not reordered with other writes.
• 不同內存地址的讀可以與較早的 寫排序, 同一地址的情況除外. - Reads may be reordered with older writes to different locations but not with older writes to the same location.
• 對I/O指令, 鎖指令, 序列化指令讀寫不能重排序. - Reads or writes cannot be reordered with I/O instructions, locked instructions, or serializing instructions.
• 讀不能越過較早 的讀柵障或者全柵障 - Reads cannot pass earlier LFENCE and MFENCE instructions.
• 邪不能越過較早的讀柵障,寫柵障和全柵障 - Writes cannot pass earlier LFENCE, SFENCE, and MFENCE instructions.
• 讀柵障指令不能越過較早的讀 - LFENCE instructions cannot pass earlier reads.
• 寫柵障指令不能越過 較早的寫 - SFENCE instructions cannot pass earlier writes.
• 全柵障子陵不能越過較早的讀和寫 - MFENCE instructions cannot pass earlier reads or writes.
在多處理器的情況下, 單處理器內部的內存訪 問排序仍然依照以上的原則, 並且規定處理器與處理器之間遵循如下的原 則:
• 某個處理器的全部寫操作以同樣的順序被其它處理器觀察到. - Writes by a single processor are observed in the same order by all processors.
• 不同處理器之間的寫操作不重排序 - Writes from an individual processor are NOT ordered with respect to the writes from other processors.
• 排序遵循邏輯上的因果關系 - Memory ordering obeys causality (memory ordering respects transitive visibility).
• 第三方總是觀察到一致的寫操作順序. - Any two stores are seen in a consistent order by processors other than those performing the stores
• 鎖指令存在一個總的順序 - Locked instructions have a total order.
單單從這些原則看來, IA-64采用的是一個較弱的內存模型. 但這不是問題的關鍵, 問題的關鍵在於維護內存一致性的機制上. IA-64出於性能 的考慮, 內存一致性機制對內存訪問排序的干預比較少. 這是IA-64弱內存模型的 關鍵. 一個相當明顯的例子表現在對寫緩存的同步處理上. IA-64內存訪問模型有 這樣一個規定; “Intra-Processor Forwarding Is Allowed”,
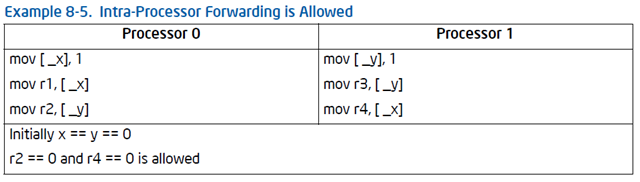
大致的意思是, 任何一個寫緩存內緩存的寫操作, 在最終提交之前, 僅僅能被 自己所屬的處理器觀察到. 這意味著, 在最終提交之前, 其它處理器根本無法預 測和判斷該處理器的寫操作. 如果一系列的寫操作是為了創建一個內存對象, 而 這些寫操作都被緩存了, 那麼在其他的處理器看來, 該內存對象根本沒有被創 建!
.NET單例模型實現的改進
考慮了寫緩存, 那麼本文開題引入的 使用Volatile關鍵字的.NET單例實現, 其實是有問題的. Volatile關鍵字只保證 對於被標記該關鍵字的字段, 將不被優化至緩存到高速緩存中.在IA-64架構下這 僅僅保證了高速緩存和主存的內存一致性, 而沒有考慮到寫緩存對於多處理器架 構下對象創建過程的影響. 這是其一.
其次, 被標記了Volatile關鍵字的字段, 自始至終不被緩存到高速緩存中. 相 對於我們的需求來說這個代價太高了.我們回頭想一下單例模型的需求, 它要求內 存對象的唯一性. 如果使用Volatile, 那麼其實只在創建對象(使用new操作符)的 時候, Volatile的特性才是我們想用的. 一旦這個對象創建以後, Volatile的特 性反而成了性能的累贅.
根據對AMD64和IA-64架構內存訪問規范的分析, 使用全柵障(MFENCE), 對以上 兩點來說, 可以起到有效地改進作用.
1. 使用全柵障, 將保證該柵障前後不能重新排序; 並使所有的寫操作寫回主 存.
2. 使用全柵障, 將避免字段一直不能被高速緩存帶來的代價, 僅僅在創建單 例對象的時候需要額外的CPU和總線時間.
Improvement
1. public class Singleton
2. {
3. private static object syncRoot = new object();
4. private Singleton instance;
5.
6. private Singleton() { }
7.
8. public Singleton Instance
9. {
10. get
11. {
12. if (instance == null)
13. {
14. lock (syncRoot)
15. {
16. if (instance == null)
17. {
18. Singleton singleObj = new Singleton();
19. System.Threading.Thread.MemoryBarrier();
20. instance = singleObj;
21. }
22. }
23. }
24.
25. return instance;
26. }
27. }
28. }
本文沒有談到什麼
為了不將本文變成又臭又長的裹腳布, 本文將關注點放在CPU內存訪問模型方 面, 而沒有涉及到:
1. ECMA CLI對於.NET弱內存模型的規定
2. .NET 2.0以來實現的強內存模型
3. InterLocked類一系列操作及其重要作用
尾記
寫這篇博文花了不少時間. 實在是因為想保證嚴謹性, 所以小心翼翼讀了 AMD64和IA-64技術規格文檔有關多處理器和內存系統的章節.期間偶爾看到 了"0BUG門"的事情, 筆者希望有問題能多一些討論, 少一些攻擊, 所謂理不辯不 明, 尊重事實. 本文限於作者拙劣的寫作水平, 心有惴惴焉, 希望各位看到廢話 能多包涵並不吝指正.