最近在為Tokyo Tyrant寫一個.NET客戶端類庫。Tokyo Tyrant公開了一個基於 TCP協議的二進制協議,於是我們的工作其實也只是按照協議發送和讀取一些二進 制數據流而已,並不麻煩。不過在其中涉及到了 “字節序”的概念,這本是計算 機體系結構/操作系統等課程的基礎,不過我還是打算在這裡進行簡單說明,並且 對.NET中部分類庫在此類數據流處理時的注意事項進行些許記錄與總結。
字節序(Byte Order)
說到程序間的通信,說到底便是發送數據流。我們一般把字節(byte)看作是 數據的最小單位。當然,其實一個字節中還包含8個比特(bit)──有時候我奇 怪為什麼很多朋友會不知道bit或是它和byte的關系。當我們拿到一系列byte的時 候,它本身其實是沒有意義的,有意義的只是“識別字節的方式”。例如,同樣4 個字節的數據,我們可以把它看作是1個 32位整數、2個Unicode、或者字符4個 ASCII字符。
同樣我們知道,在一個32位的 CPU中“字長”為32個bit,也就是4個byte。在 這樣的CPU中,總是以4字節對齊的方式來讀取或寫入內存,那麼同樣這4個字節的 數據是以什麼順序保存在內存中的呢?例如,現在我們要向內存地址為a的地方寫 入數據0x0A0B0C0D,那麼這4個字節分別落在哪個地址的內存上呢?這就涉及到字 節序的問題了。
每個數據都有所謂的“有效位(significant byte)”,它的意思是“表示這 個數據所用的字節”。例如一個32位整數,它的有效位就是4個字節。而對於 0x0A0B0C0D來說,它的有效位從高到低便是0A、0B、0C及0D——這裡您可以把它 作為一個256進制的數來看(相對於我們平時所用的10進制數)。
而所謂大字節序(big endian),便是指其“最高有效位(most significant byte)”落在低地址上的存儲方式。例如像地址a寫入0x0A0B0C0D之後,在內存中 的數據便是:
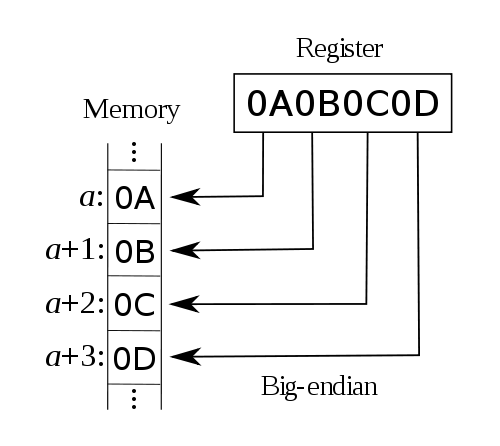
而對於小字節序(little endian)來說就正好相反了,它把“最低有效位 (least significant byte)”放在低地址上。例如:
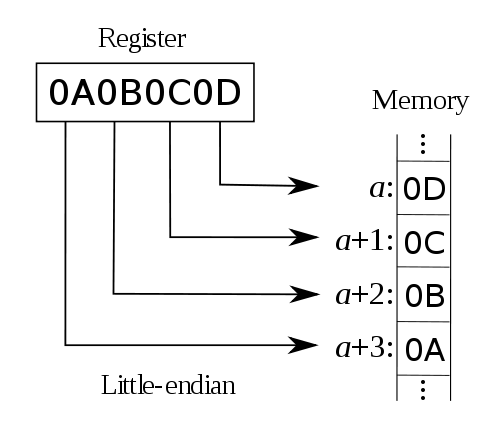
對於我們常用的CPU架構,如Intel,AMD的CPU使用的都是小字節序,而例如 Mac OS以前所使用的Power PC使用的便是大字節序(不過現在Mac OS也使用Intel 的CPU了)。此外,除了大字節序和小字節序之外,還有一種很少見的中字節序( middle endian),它會以2143的方式來保存數據(相對於大字節序的1234及小字 節序的4321)。
關於字節序的詳細說明,您可以參考Wikipedia裡的Endianness條目。
相關.NET類庫BinaryWriter和BinaryReader
在.NET框架操作數據流的時候,我們往往會使用BinaryWriter和BinaryReader 進行讀寫。這兩個類中都有對應的WriteInt32或是ReadInt32方法,那麼它們是如 何處理字節序的呢?從MSDN上我們了解到BinaryReader使用小字節序讀取數據。 這意味著:
var stream = new MemoryStream(new byte[] { 4, 1, 0, 0 });
var reader = new BinaryReader(stream);
int i = reader.ReadInt32(); // i == 260
與之類似,自然BinaryWriter也是使用小字節序來寫入數據。
BitConverter
有時候我們還會使用BitConverter來轉化byte數組及一個32位整數(自然也包 括其他類型),這也是涉及到字節序的操作,那麼它們又是如何處理的呢?與 BinaryWriter和BinaryReader的“固定策略”不同,BitConverter的行為是平台 相關的。
首先,BitConverter有一個只讀靜態字段IsLittleEndian,它表示當前平台的 字節序。由於我們為不同的CPU會安裝不同的.NET類庫,因此您現在如果通過.NET Reflector來查看這個字段會發現它被設置為一個常量true。那麼接下來, BitConverter上的各個方便便會根據 IsLittleEndian的值產生不同行為了,例如 它的ToInt32方法:
public static unsafe int ToInt32(byte[] value, int startIndex)
{
// ...
fixed (byte* numRef = &(value[startIndex]))
{
if ((startIndex % 4) == 0)
{
return *(((int*)numRef));
}
if (IsLittleEndian)
{
return numRef[0] | (numRef[1] << 8) | (numRef[2] << 16) | (numRef[3] << 24);
}
return (numRef[0] << 24) | (numRef[1] << 16) | (numRef[2] << 8) | numRef[3];
}
}
顯然,這裡會根據IsLittleEndian返回不同的值。
判斷當前平台的字節序
在.NET Framework中BitConverter.IsLittleEndian字段是一個常量,也就是 說它在編譯期便寫入了一個靜態的值。那麼我們如果想要通過代碼來判斷當前平 台的字節序,又該怎麼做呢?其實這很簡單:
static unsafe bool IsLittleEndian()
{
int i = 1;
byte* b = (byte*)&i;
return b[0] == 1;
}
這裡我們通過檢查32位整數1的第一個字節來確定當前平台的字節序。當然, 我們也可以使用其他類型,例如:
static unsafe bool AmILittleEndian()
{
// binary representations of 1.0:
// big endian: 3f f0 00 00 00 00 00 00
// little endian: 00 00 00 00 00 00 f0 3f
// arm fpa little endian: 00 00 f0 3f 00 00 00 00
double d = 1.0;
byte* b = (byte*)&d;
return (b[0] == 0);
}
這段代碼來自mono的BitConverter類庫,至於它為什麼使用double而不是int ,我也不是很清楚。
Buffer.BlockCopy方法
.NET類庫中自帶一個Buffer.BlockCopy方法,它的作用是將一個數組的字節— —不是元素——復制到另一個數組中去。換句話說,一個長度為100的int數組經 過完整的復制後,就變成了長度為50的 long數組,因為一個int為4字節,而long 為8字節。從文檔上看,Buffer.BlockCopy是與字節序相關的,也就是說,同樣的 .NET 代碼在字節序不同的平台上得到的結果可能不同。因此,我建議在使用這個 方法的時候多加小心。
面向特定字節序編程
我們知道,BitConverter的工作結果是和當前平台的字節序相關的,但是在很 多時候,尤其是根據某個公開的協議進行通信編程的時候,是需要固定一個字節 序的。例如Tokyo Tyrant便要求每個整數都以大字節序的方式來通信——無論是 發送還是讀取。為了保證.NET代碼的平台無關性,我們不能直接使用 BitConverter.GetBytes或ToInt32方法進行轉化。那麼我們該怎麼辦呢?最直觀 的方法自然是手動進行轉換:
static int ReadInt32(Stream stream)
{
var buffer = new byte[4];
stream.Read(buffer, 0, 4);
return buffer[0] | (buffer[1] << 8) | (buffer[2] << 16) | (buffer[3] << 24);
}
由於我們可以通過BitConverter.IsLittleEndian來得到當前平台的字節序, 我們也可以用它進行判斷:
static int ReadInt32(Stream stream)
{
var buffer = new byte[4];
stream.Read(buffer, 0, 4);
if (BitConverter.IsLittleEndian)
{
Array.Reverse(buffer);
}
return BitConverter.ToInt32(buffer, 0);
}
static void WriteInt32(Stream stream, int value)
{
var buffer = BitConverter.GetBytes(value);
if (BitConverter.IsLittleEndian)
{
Array.Reverse(buffer);
}
stream.Write(buffer, 0, buffer.Length);
}
此外,我們知道BinaryWriter和BinaryReader都是依據小字節序進行讀寫的, 因此我們也可以利用這點來讀寫數據流。要不,接下來就由您試試看如何?
文章來源: http://www.cnblogs.com/JeffreyZhao/archive/2010/02/10/byte-order-and- related-library.html