XMLTextWriter類
用在本節中的方法創建XML文檔顯然並不困難。多年以來,開發者都是通過在緩存在連接一些字符串,連接好以後再把緩存中字符串輸出到文件的方式來創建XML文檔。但是以這種方式創建XML文檔的方法只有在你保證字符串中不存在任何細小的錯誤的時候才有效。.netFramework通過用XMLwriter提供了更好的創建XML文檔的方法。
XMLWriter類以只前(forward-only)的方式輸出XML數據到流或者文件中。更重要的是,XMLWriter在設計時就保證所有的XML數據都符合W3CXML1.0推薦規范,你甚至不用擔心忘記寫閉標簽,因為XMLWriter會幫你寫。XmlWriter是所有XMLwriter的抽象基類。.NETFramework只提供唯一的一個writer類----XmlTextWriter類。
我們先來看看XMLwriters和舊的writers的不同點,下面的代碼保存了一個string型的數組:
StringBuilder sb = new StringBuilder("");
sb.Append("");
foreach(string s in theArray) {
sb.Append("
sb.Append(s);
sb.Append("\"/>");
}
sb.Append("");
代碼通過循環取出數據中的元素,寫好標簽文本並把它們累加到一個string中。代碼保證輸出的內容是格式良好的並且注意了新行的縮進,及支持命名空間。當創建的文檔結構比較簡單時,這種方法可能不會有錯誤。然而,當你要支持處理指令,命名空間,縮進,格式化以及實體的時候,代碼的數量就成指數級增長,出錯的可能性也隨之增長。
XMLwriter寫方法功能對應每個可能的XML節點類型,它使創建xml文檔的過程更符合邏輯、更少的信賴於繁瑣的標記語言。圖六演示了怎麼樣用XmlTextWriter類的方法來連接一個string數據。代碼很簡潔,用XMLwriter的代碼更容易讀、結構更好。
Figure 6 Serializing a String Array
void CreateXmlFileUsingWriters(String[] theArray, string filename)
{
// Open the XML writer (用默認的字符集)
XmlTextWriter xmlw = new XmlTextWriter(filename, null);
xmlw.Formatting = Formatting.Indented;
xmlw.WriteStartDocument();
xmlw.WriteStartElement("array");
foreach(string s in theArray)
{
xmlw.WriteStartElement("element");
xmlw.WriteAttributeString("value", s);
xmlw.WriteEndElement();
}
xmlw.WriteEndDocument();
// Close the writer
xmlw.Close();
}
然而XMLwriter並不是魔術師----它不能修復輸入的錯誤。XMLwriter不會檢查元素名和屬性名是否有效,也不保證被用的任何的Unicode字符集適合當前架構的編碼集。如上所述,為了避免輸出錯誤,必須要杜絕非XML字符。但是writer沒有提供這種方法。
另外,當創建一個屬性節點時,Writer不會檢驗屬性節點的名稱是否與已存在的元素節點的名稱相同。最後,XmlWriter類不是一個帶驗證的Writer類,也不保證輸出是否符合schema或者DTD。在.NETFramework中帶驗證的writer類目前來說還沒有提供。但是在我寫的《AppliedXMLProgrammingforMicrosoft.NET(MicrosoftPress?,2002)》書中,我自己寫了一個帶驗證的Writer組件。你可以到下面的網址去下載源碼:http://www.microsoft.com/MSPress/books/6235.ASP.
圖七列出了XMLwriter的一些狀態值(state)。這些值都源於WriteState枚舉類。當你創建一個Writer,它的初始狀態為Start,表示你將要配置該對象,實際上writer沒有開始。下一個狀態是Prolog,該狀態是當你調用WriteStartDocument方法開始工作的時候設置的。然後,狀態的轉換就取決於你的寫的文檔及文檔的內容了。Prolog狀態一直保留到當你增加一個非元素節點時,例如注釋元素,處理指令及文檔類型。當第一個節點也就是根節點寫完後,狀態就變為Element。當你調用WriterStartAtribute方法時狀態轉換為Attribute,而不是當你調用WriteAtributeString方法寫屬性時轉換為該狀態。如果那樣的話,狀態應該是Element。當你寫一個閉標簽(>)時,狀態會轉換成Content。當你寫完文檔後,調用WriteEndDocument方法,狀態就會返回為Start,直到你開始寫另一個文檔或者把Writer關掉。
Figure 7 States for XML Writer
State
Description
Attribute
The writer enters this state when an attribute is being written
Closed
The Close method has been called and the writer is no longer available for writing operations
Content
The writer enters this state when the content of a node is being written
Element
The writer enters this state when an element start tag is being written
Prolog
The writer is writing the prolog of a well-formed XML 1.0 document
Start
The writer is in an initial state, awaiting for a write call to be issued
Writer把輸出文本存在內部的一個緩沖區內。一般情況下,緩沖區會被刷新或者被清除,當Writer被關閉前XML文本應該要寫出。在任何時你都可以通過調用Flush方法清空緩沖區,把當前的內容寫到流中(通過BaseStream屬性暴露流),然後釋放部分占用的內存,Writer仍保持為打開狀態(openstate),可以繼續操作。注意,雖然寫了部分的文檔內容,但是在Writer沒有關閉前其它的程序是不能處理該文檔的。
可以用兩種方法來寫屬性節點。第一種方法是用WriteStartAtribute方法去創建一個新的屬性節點,更新Writer的狀態。接著用WriteString方法設置屬性值。寫完後,用WriteEndElement方法結束該節點。另外,你也可以用WriteAttributeString方法去創建新的屬性節點,當writerr的狀態為Element時,WriterAttributeString開始工作,它單獨創建一個屬性。同樣的,WriteStartElement方法寫節點的開始標簽(<),然後你可以隨意的設置節點的屬性和文本內容。元素節點的閉標簽都帶”/>”。如果想寫閉標簽可以用WriteFullEndElement方法來寫。
應該避免傳送給寫方法的文本中包含敏感的標記字符,例如小於號(<)。用WriteRaw方法寫入流的字符串不會被解析,我們可以用它來對xml文檔寫入特殊的字符串。下面的兩行代碼,第一行輸出的是”<”,第二行輸出”<”:
writer.WriteString("<");
writer.WriteRaw("<");
讀寫流
有趣的是,reader(閱讀器)和writer類提供了基於Base64和BinHex編碼的讀寫數據流的方法。WriteBase64和WriteBinHex方法的功能與其它的寫方法的功能存在著細微的差別。它們都是基於流的,這兩個方法的功能像一個byte數組而不是一個string。下面的代碼首先把一個string轉換成一個byte數組,然後把它們寫成一個Base64編碼流。Encoding類的GetBytes靜態方法完成轉換的任務:
writer.WriteBase64(
Encoding.Unicode.GetBytes(buf),0,buf.Length*2);
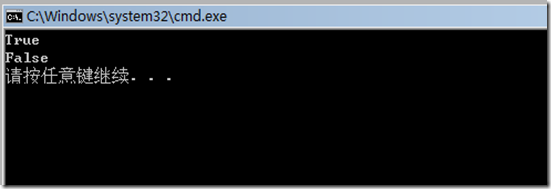
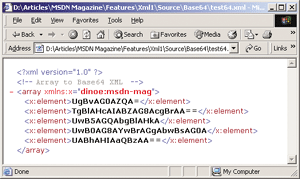
圖八中代碼演示了把一個string數據轉換為Base64編碼的XML流。圖九是輸出的結果。
Figure 8 Persisting a String Array as Base64
using System;
using System.Text;
using System.IO;
using System.Xml;
class MyBase64Array
{
public static void Main(String[] args)
{
string outputFileName = "test64.xml";
if (args.Length > 0)
outputFileName = args[0]; // file name
// 把數組轉換成XML
String[] theArray = {"Rome", "New York", "Sydney", "Stockholm",
"Paris"};
CreateOutput(theArray, outputFileName);
return;
}
private static void CreateOutput(string[] theArray, string filename)
{
// 打開XML writer
XmlTextWriter xmlw = new XmlTextWriter(filename, null);
//使子元素根據 Indentation 和 IndentChar 設置縮進。此選項只對元素內容進行縮進
xmlw.Formatting = Formatting.Indented;
//書寫版本為“1.0”的 XML 聲明
xmlw.WriteStartDocument();
//寫出包含指定文本的注釋 。
xmlw.WriteComment("Array to Base64 XML");
//開始寫出array節點
xmlw.WriteStartElement("array");
//寫出具有指定的前綴、本地名稱、命名空間 URI 和值的屬性
xmlw.WriteAttributeString("xmlns", "x", null, "dinoe:msdn-mag");
// 循環的寫入array的子節點
foreach(string s in theArray)
{
//寫出指定的開始標記並將其與給定的命名空間和前綴關聯起來
xmlw.WriteStartElement("x", "element", null);
//把S轉換成byte[]數組, 並把byte[]數組編碼為 Base64 並寫出結果文本,要寫入的字節數為s總長度的2倍,一個string占的字節數是2字節。
xmlw.WriteBase64(Encoding.Unicode.GetBytes(s), 0, s.Length*2);
//關閉子節點
xmlw.WriteEndElement();
}
//關閉根節點,只有兩級
xmlw.WriteEndDocument();
// 關閉writer
xmlw.Close();
// 讀出寫入的內容
XmlTextReader reader = new XmlTextReader(filname);
while(reader.Read())
{
//獲取節點名為element的節點
if (reader.LocalName == "element")
{
byte[] bytes = new byte[1000];
int n = reader.ReadBase64(bytes, 0, 1000);
string buf = Encoding.Unicode.GetString(bytes);
Console.WriteLine(buf.Substring(0,n));
}
}
reader.Close();
}
}
Figure 9 String Array in Internet Explorer
Reader類有專門的解釋Base64和BinHex編碼流的方法。下面的代碼片斷演示了怎麼樣用XmlTextReader類的ReadBase64方法解析用Base64和BinHex編碼集創建的文檔。
XmlTextReader reader = new XmlTextReader(filename);
while(reader.Read()) {
if (reader.LocalName == "element") {
byte[] bytes = new byte[1000];
int n = reader.ReadBase64(bytes, 0, 1000);
string buf = Encoding.Unicode.GetString(bytes);
Console.WriteLine(buf.Substring(0,n));
}
}
reader.Close();
從byte型轉換成string型是通過Encoding類的GetString方法實現的。盡管我只介紹了基於Base64編碼集的代碼,但是可以簡單的用BinHex替換方法名就可以實現讀基於BinHex編碼的節點內容(用ReadBinHex方法)。這個技巧也可以用於讀任何用byte數據形式表示的二進制數據,尤其是image類型的數據。