關於英文對程序員的重要性,就不多說了!
英語的學習,有很多,今天也不聊多,只聊英語單詞!
關於單詞的記憶,找過很多方法,下載過很多軟件。
如圖(其它不好用的都卸載了):

上圖算是我以前用過軟件,注意,是以前哦~~~
意思就是沒有堅持下來~~~~
隨時間的推移,最後它們還是被我遺忘了~~~
為什麼???不能:堅持!堅持!堅持!
一直在找方法:
1:下載過聯想記憶法、背文章記單詞,詞根,各種視頻~~~
2:連單詞的數據庫都網上下載了一份了,期望從數據庫的直接記憶單詞快些~~~
通過各種查詢語句,整理相似度的來記,才1天,就沒後文了~~~
每天都在占用時間的事情:
可能寫框架,可能寫博文,可能其它事,一天一天過的很快~~~
於是,就在反反復復中~~~忘了背背了忘~~~~~
經過重新的思考之後,我覺方向錯了!
我思考著,怎麼利用下載的單詞數據庫來做點什麼讓自己能更好的堅持。
一開始思考,每天抓取CodeProject上的英文文章1篇;
然後分析單詞頻率,把頻率最高的10個單詞做為學習的方向。
後來又被自己否了:
1:出現的頻道高的一定是那些the that this is a apple之類的,沒有意義,要做過濾的話,工作量又大。
2:讀一篇文章,學幾個單詞,估計很難堅持(畢竟從小到大都是這種學習模式,已經無數次驗證了沒用)。
3:純記憶的短期記憶學習,和浪費時間沒差別,又不是應付短期的考試。
於是,光單詞的展示不行,必須要有思考和交互在裡面!

1:One Day Two Words,一天2個單詞(一開始是10個,後來覺的多了,畢竟有互動,要打字,怕10個容易堅持不來)
2:單詞印象:每個人都會對單詞進行評論(人玩多了,就會產生很多有意思有評論,前提是看大伙會不會玩)
3:造句:小時候學中文字的時候,老師都叫我們造句的,為什麼長大後學英文就沒強制這個要求了?
4:我的記錄:可以查學過的詞~~~~
5:單詞庫有3萬多個,我挑了雅思共4034個詞,隨機出!
總體而已,主要是降低學習難度,這樣容易堅持~~~
整體完成後,感覺還不夠,內心隱隱都覺的還缺少什麼,後續看看網友有什麼建議~~~
一開始還想著弄個前端的框架,或者弄個JQ Mobile之類的,搞個html+api請求。
後來光找框架和看Demo就花了不少時間,感覺做個簡單的東西這麼費時間,然後直接給我畢了。
於是,用Table,最好的兼容,最容易的布局!
用WebForm的ASPX,最省時的處理手段。
網站要部署在原有的VPS上,1共就1G內存,已經跑了六七個網站了。
因此站用資源要少,性能要好,要經得起人民的考驗。
一開始是計劃用文本數據庫的;
但原有的單詞數據已經在sql2005上了,順手用sql2000了。
頁面要簡單,能省多少是多少,於是一個JS都木有了;
對單詞做了緩存,對單詞的評論提交做了隊列寫;
考慮到訪問量並不大,展示是直接讀的數據庫,有自動緩存。
考慮到並不是人人都很友善,會不會有人故意提交大量的一堆垃圾數據過來呢?
於是在後端做了簡單的安全的驗證。
前端的驗證也很簡單驗證了一下長度。
自帶的詞庫,有些單詞的音標可能缺少,因此需要有一個采集的過程。
於是要找一個可以采集的點,一開始定位去百度裡找:
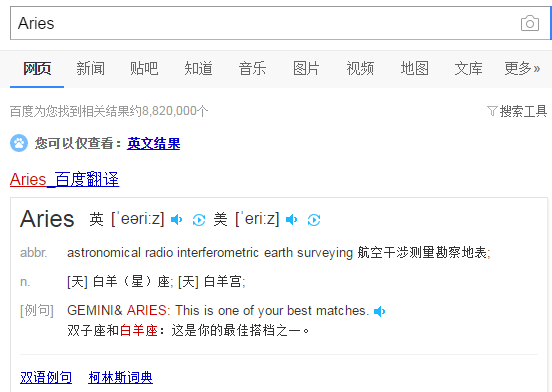
寫了代碼采了一下,發現單詞都在js裡混淆輸出。
想用百度API,發現要Money~~~~
時間很緊張,因為只給自己一個下午的時間~~~~
後來又找了幾個,最後發現還是微軟家的親切:
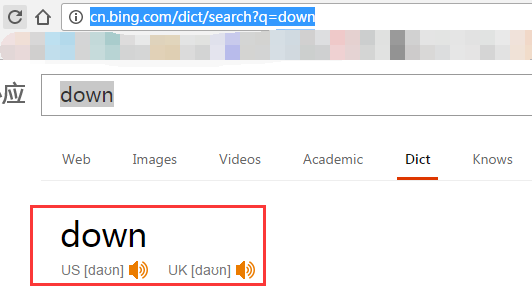
圖片框起來的,但是,是采不到的,因為也是JS裡混淆的,然而:

標題描述裡竟然有音標~~~這都被我發現了,寫一段這樣的代碼就可以拿到了:
private string GetWordPronunciation(string word)
{
string pronunciation = string.Empty;
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
string result = wc.DownloadString("http://cn.bing.com/dict/search?q=" + word);
string key = "英[";
int index = result.IndexOf(key, StringComparison.Ordinal);
if (index == -1)
{
key = "美[";
index = result.IndexOf(key, StringComparison.Ordinal);
}
if (index > -1)
{
int end = result.IndexOf(']', index);
pronunciation = result.Substring(index + key.Length, end - index - 2);
}
return pronunciation;
}
當我簡單用WebClient的DownString拿到html存在result變量時(UTF8編碼)。
result=".....英[......";
我用:result.IndexOf("英["),竟然返回-1,我納悶了一下。
通過SubString截掉前面變成:result="英[...";
於是:result.StartWith("英["),竟然返回false,我糾結了一個。
可是:result[0]==‘英' && result[1]=='[' 即是true的。
後來搜了一下,才發現:
html.IndexOf(key, StringComparison.Ordinal)
這樣就正常了,解決在於:StringComparison這個參數了。
雖然理解參數的意義,但是不解的是:
這裡並木有特殊的第三方字符?
而且采集的幾千個詞,有1000多個出現這種情況,目前無解,只能注意!!!
http://word.cyqdata.com/
如果你需要單詞的數據庫,就在這裡:
http://download.csdn.net/detail/cyq1162/9445894
就這樣,昨天花了一個下午,半個晚上,今天又半個下午,把這個小程序給完成了。
希望能堅持~~~大伙也一起來,一群人堅持,比一個人更容易堅持!