題目:http://www.cnblogs.com/dunitian/p/6028838.html
匯總:http://www.cnblogs.com/dunitian/p/5977425.html
說明:如有錯誤可以批評指正,有更好寫法也可以提點下~
1. 求結果:select "1"?
報錯,SQL裡面只有單引號,列如:'xx'
2. 查找包含"objs"的表?查找包含"o"的數據庫?
select * from sys.objects where name like '%objs%'
select * from sys.databases where name like '%o%'
3. 求今天距離2002年有多少年,多少天?
select datediff(yy,'2002',getdate())
select datediff(dd,'2002',getdate())
4. 請用一句SQL獲取最後更新的事務號(ID)
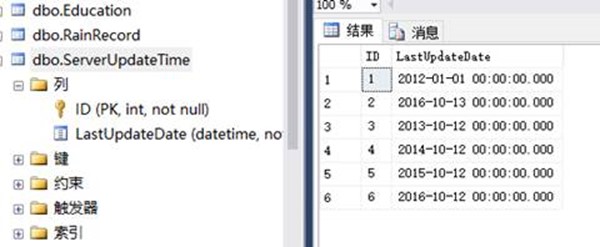
select top 1 * from ServerUpdateTime order by LastUpdateDate desc
5. 有如下兩個表:
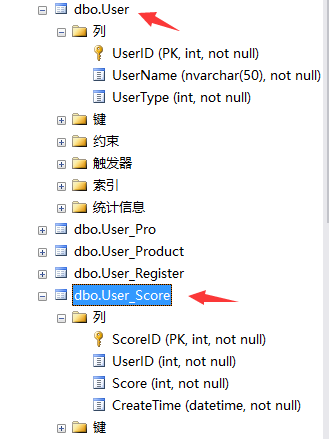
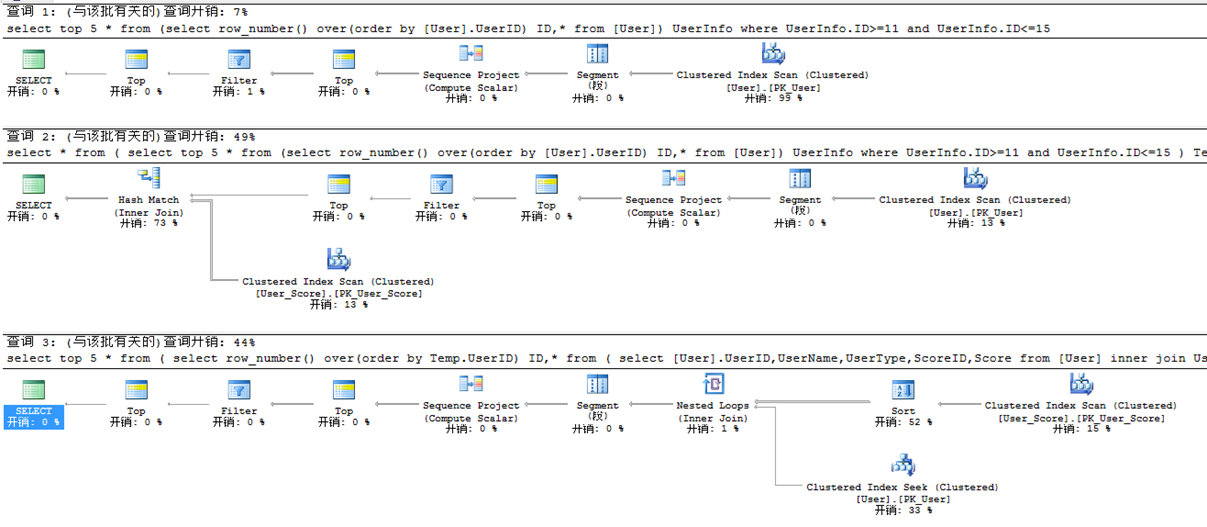
①請查詢11 ~ 15記錄的User
只是解題用:
select top 5 * from (select row_number() over(order by [User].UserID) ID,* from [User]) UserInfo
where UserInfo.ID>=11 and UserInfo.ID<=15
真正項目往往查詢User完整信息:
--其他寫法
select * from
(
select top 5 * from (select row_number() over(order by [User].UserID) ID,* from [User]) UserInfo
where UserInfo.ID>=11 and UserInfo.ID<=15
) Temp
inner join User_Score on Temp.UserID=User_Score.UserID
--推薦寫法
select top 5 * from
(
select row_number() over(order by Temp.UserID) ID,* from
(
select [User].UserID,UserName,UserType,ScoreID,Score from [User]
inner join User_Score on [User].UserID=User_Score.UserID
)Temp
) UserInfo
where UserInfo.ID>=11 and UserInfo.ID<=15
依據:推薦寫法,看起來效率應該低點,但事實證明比其他寫法效率高
②查詢用戶類型type=1總積分排名前十的user
select top 10 [User].* from [User]
inner join User_Score on [User].UserID=User_Score.UserID
where UserType=1
order by Score desc
③寫一條存儲過程,實現往User中插入一條記錄並返回當前UserId(自增長id)
--推薦寫法
if(Exists(select * from sys.objects where name=N'Usp_InsertedID'))
drop proc Usp_InsertedID
go
create proc Usp_InsertedID
as
insert into [User] output inserted.UserID values(N'張三蛋',3)
--另一種寫法(SCOPE_IDENTITY()可以得到當前范圍內最近插入行生成的標示值)
if(Exists(select * from sys.objects where name=N'Usp_InsertedID'))
drop proc Usp_InsertedID
go
create proc Usp_InsertedID
as
insert into [User] values(N'李狗蛋',1)
select scope_Identity()
go
--不推薦:(@@Identity就不一定是當前范圍內了)
if(Exists(select * from sys.objects where name=N'Usp_InsertedID'))
drop proc Usp_InsertedID
go
create proc Usp_InsertedID
as
insert into [User] values(N'張三章',2)
select @@Identity
go
exec Usp_InsertedID
6. 請求出每個班級的數學平均分,並按照高低進行排序
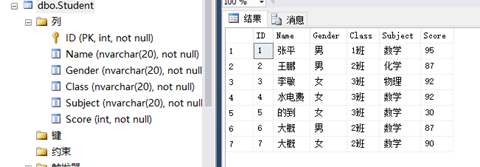
select avg(Score) AvgScore from Student
where Subject=N'數學'
group by Class
order by AvgScore desc
7. 一個TestDB表有A,B兩個字段。
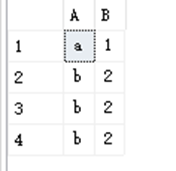
①寫一句SQL求出有重復值的記錄。
--解題專用
select * from TestDB
where A in
(
select A from TestDB
group by A,B
having count(*)>1
)
order by A
--推薦:實際運用(真實環境下往往是為了找出重復值然後假刪掉)
select * from
(
select row_number() over(partition by A,B order by A) ID,* from TestDB
) Temp
where Temp.ID>1
執行效率還是有很大差距的,有圖有真相:
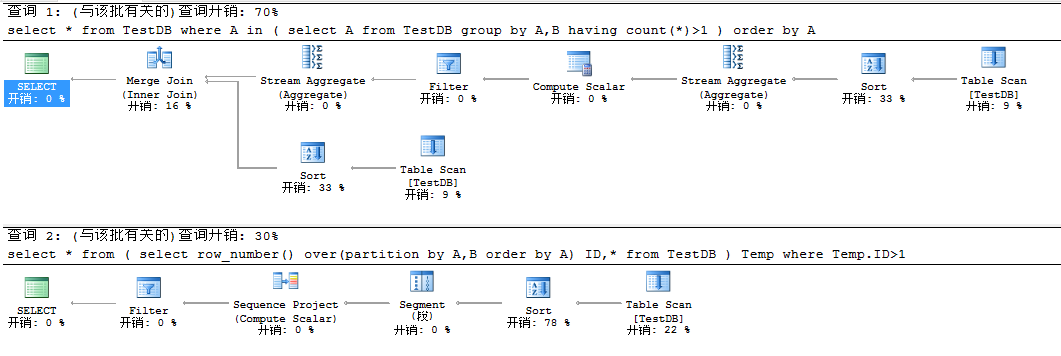
②請刪除重復項。(最好用兩種方法)
--傳統寫法:
select * into #Temp from (select distinct * from TestDB) A
drop table TestDB
select * into TestDB from #Temp
drop table #Temp
--推薦寫法(真正項目中基本上不會真刪)
delete Temp from (select row_number() over(partition by A,B order by A) ID,* from TestDB)Temp
where Temp.ID>1
8. 表中有A,B,C三列,用SQL實現:當A列>B列選擇A,否則選擇B,當B列>C列選擇B,否則選擇C

select
(
case
when A>B then A
else B
end
),
(
case
when B>C then B
else C
end
)from ABC
9. 數據行列互換
轉換前:

轉換後:

select Name,
sum(
case Courses
when '語文' then Score else 0
end
) 語文,
sum(
case Courses
when '數學' then Score else 0
end
)數學,
sum(
case Courses
when '物理' then Score else 0
end
)物理 from Student_Courses_Score
group by Name
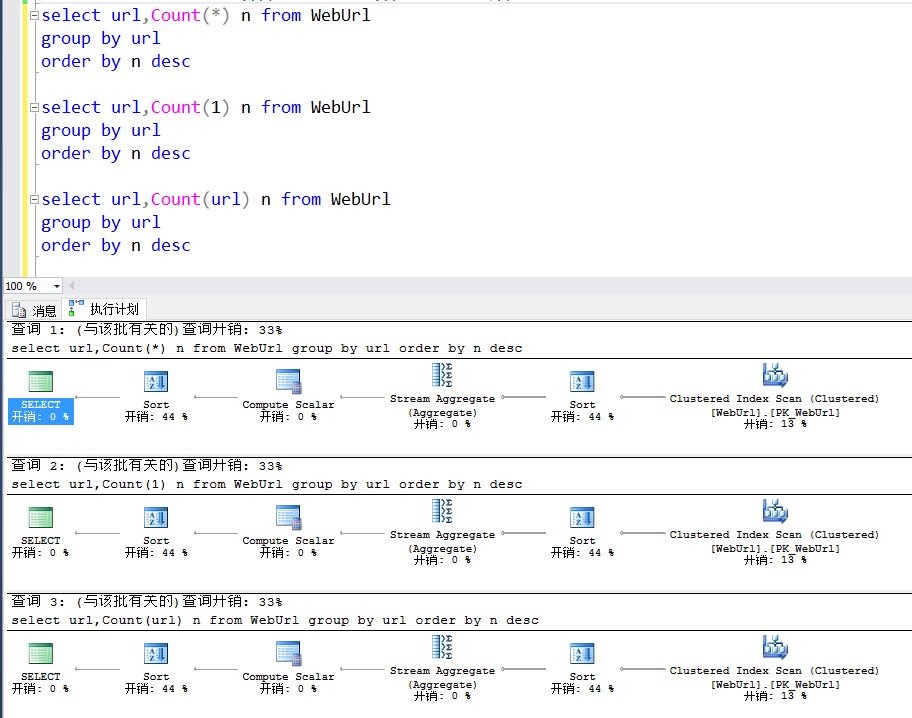
10. 請統計每個URL訪問次數,並按訪問次數由高到低的順序排序
select url,Count(*) n from WebUrl
group by url
order by n desc
順便打破一個偽結論:count(1)性能大於count(*)==》不要麻木相信優化,自己證實後再說~
11. 用戶注冊表中id是自增長的。
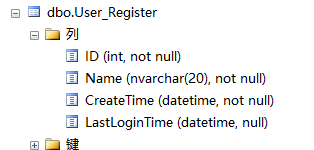
①請查詢出一天24h每小時注冊的人數
select datepart(hh,CreateTime) '小時',count(*) '注冊人數' from User_Register
where CreateTime>=convert(varchar(10),getdate(),120) and CreateTime <convert(varchar(10),dateadd(day,1,getdate()),120)
group by datepart(hh,CreateTime)
②請查詢第4條記錄
select * from (select row_number() over(order by ID) RId,* from User_Register) Temp
where RId=4
③請查詢ID重復次數大於2次的記錄
--傳統方法(偏向於全部找出來)
select * from User_Register
where ID in
(
select ID from User_Register
group by ID having count(ID)>1
)
order by ID
--推薦方法(偏向於找多余重復值)
select * from (select row_number() over(partition by ID order by ID) RId,* from User_Register) Temp
where RId>1
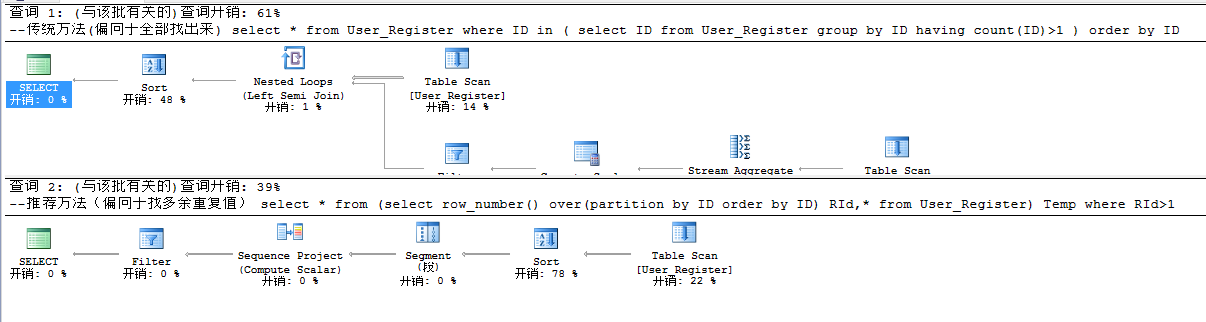
12. 圖書表(圖書號,圖書名,作者編號,出版社,出版日期)作者表(作者編號,作者姓名,年齡,性別)。用SQL語句查詢出年齡小於平均年齡的作者名稱、圖書名,出版社
select WriterName,BookName,PublishingHouse from Books
inner join Writer on Books.WriterNo=Writer.WriterNo
where Writer.Age < (select avg(Age) from Writer)
13. 返回num最小的記錄(禁止使用min,max等統計函數)

select top 1 * from TestNums
where num is not null
order by num
14. 舉例說下項目中視圖的好處?
項目裡面一般把一些業務比較復雜的東西封裝在一個視圖裡面,比如說項目裡面這個查詢用到了10多張表,表與表之間的關系邏輯你都得搞清楚,後期維護的時候又要拿出來弄懂,太浪費時間了,這時候視圖的作用就突襲出了
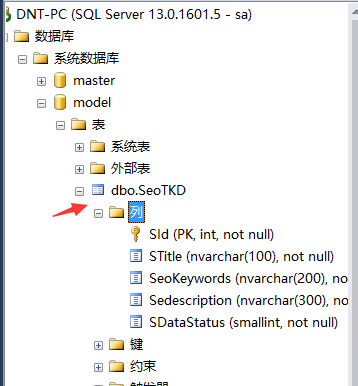
15. SQLServer有哪些系統數據庫?分別是干什麼的?
Master,系統用的一些表、存儲過程
Tempdb,臨時表存放的數據庫
Msdb,定時任務存放的系統數據庫
Model,數據庫模版,新建數據庫的時候,他會把Model裡面的東西拷貝一份到新的數據庫裡面
eg:(其實不止這些系統表,這些是比較常用的)
16. 索引有什麼好處,又有何缺點?聚集索引和非聚集索引有什麼區別?
索引都是為了提高查詢速度的,索引一般添加到不是頻繁改動的字段上。
索引也是占空間滴,查詢速度是快了增刪改可就慢咯~
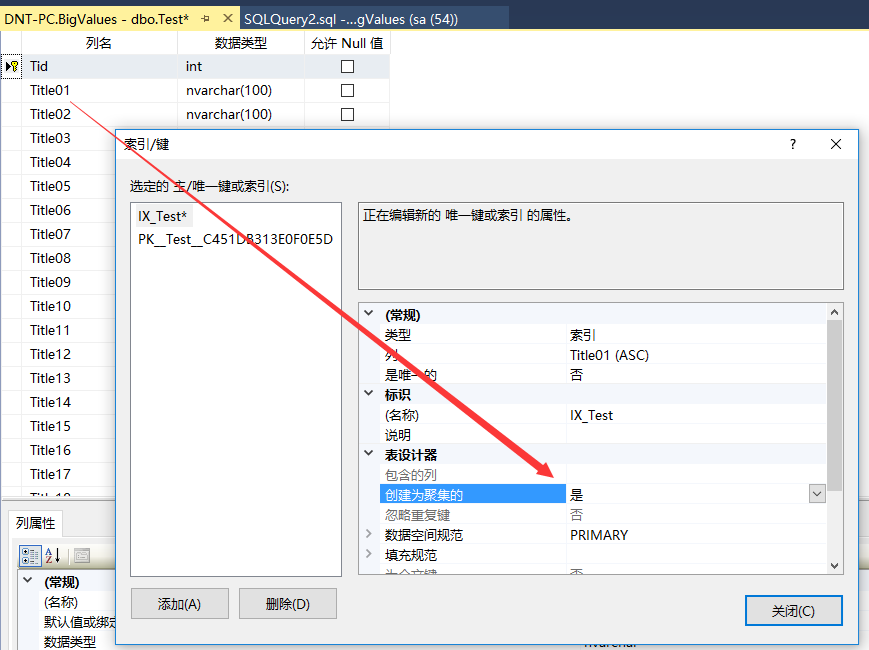
聚集索引影響排序,非聚集索引不影響排序。(主鍵默認是聚集索引哦)
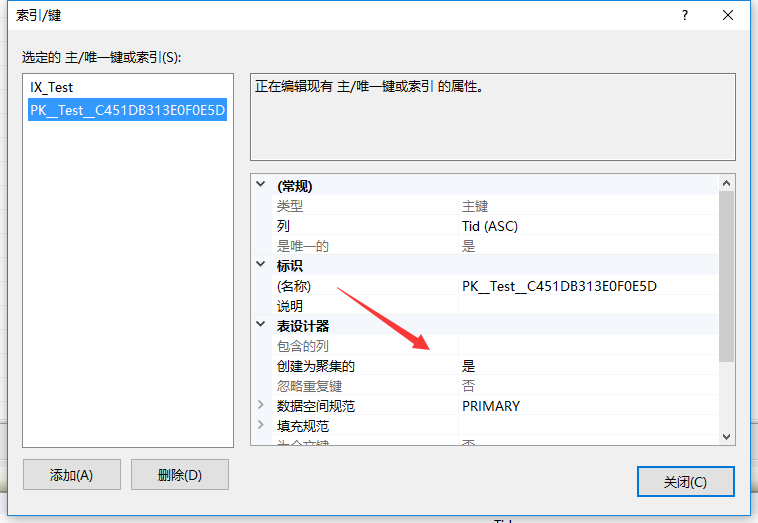
聚集索引是主鍵時候的排序是這個樣子的:

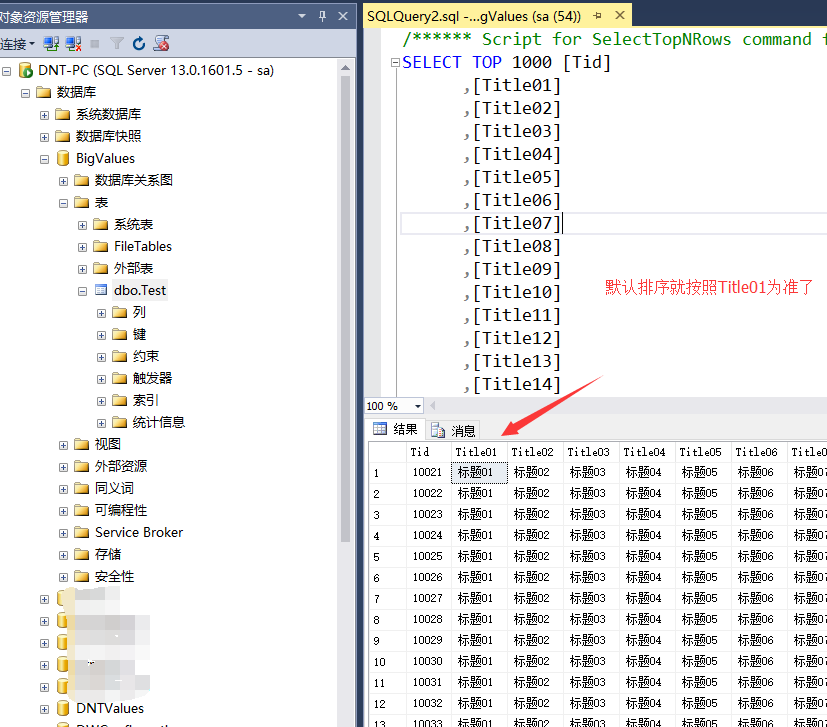
聚集索引改成Title01
默認排序就以Title01為准了
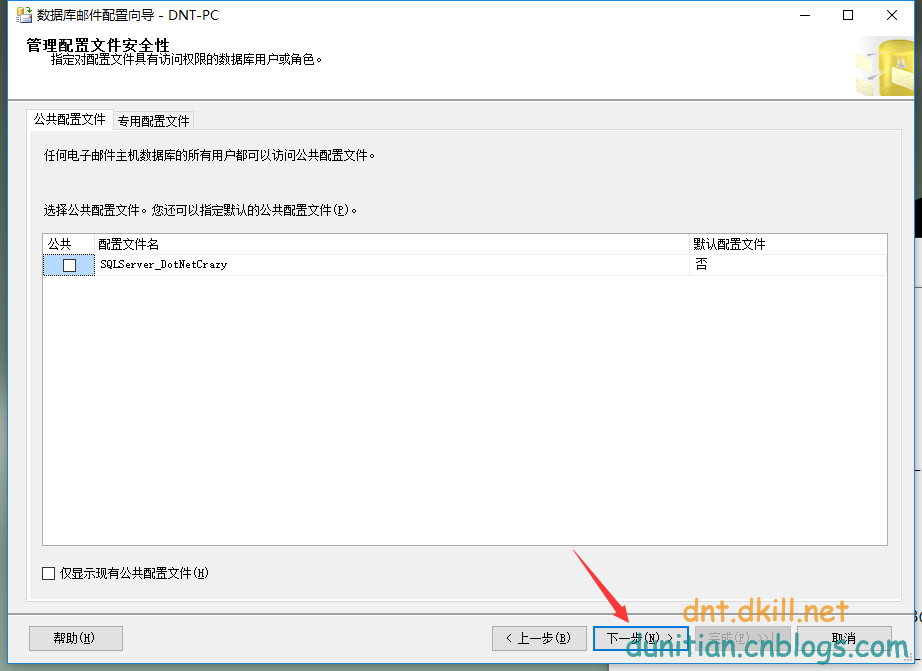
17. 什麼時候需要SQLServer發郵件?怎麼去發郵件(只要求掌握圖形化頁面,命令會使用即可)?
這個應用案例很多,一般都是預警,比如異常連接的時候,或者數據庫報錯的時候,一般都會和定時任務聯合使用。
發郵件相關介紹:http://www.cnblogs.com/dunitian/p/6022826.html
簡單說下:
在配置之前請先把郵件的POP3之類的設置一下:
圖形化演示:
配置名字隨意取,可以用項目名。顯示名稱建議用版本號+服務器ip,這樣出問題可以定位跟蹤
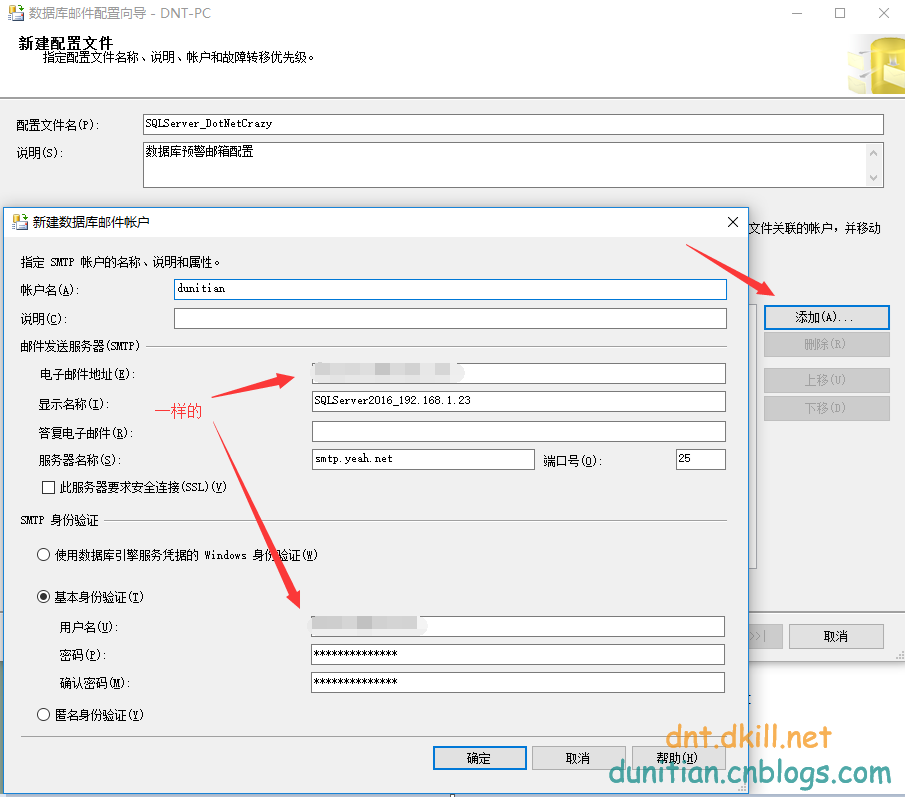
微軟圖形化的東西一般有個特點,一路下一步基本上能解決所有基礎問題
勾選一下(貌似不勾選也沒事)
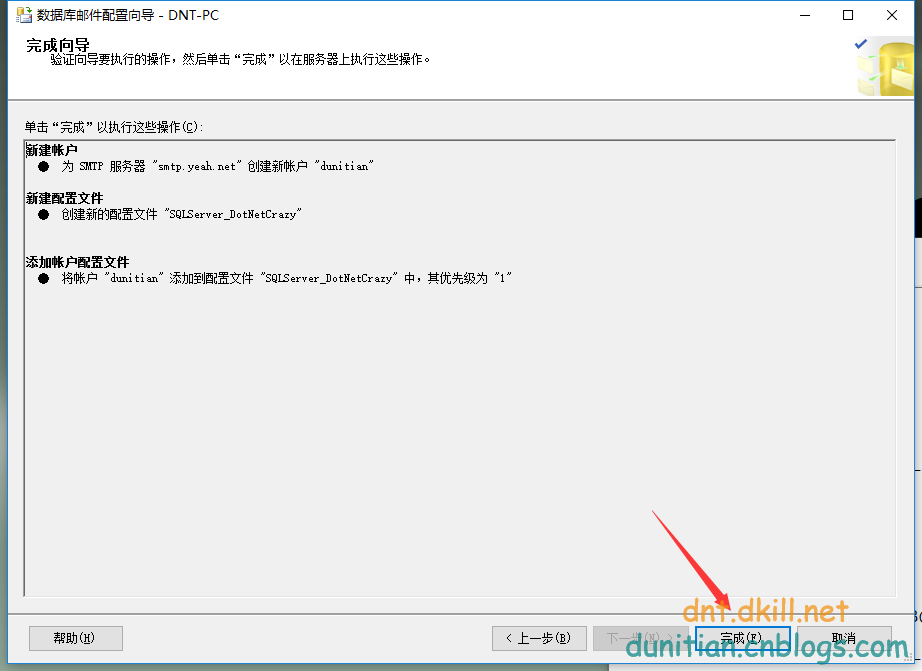
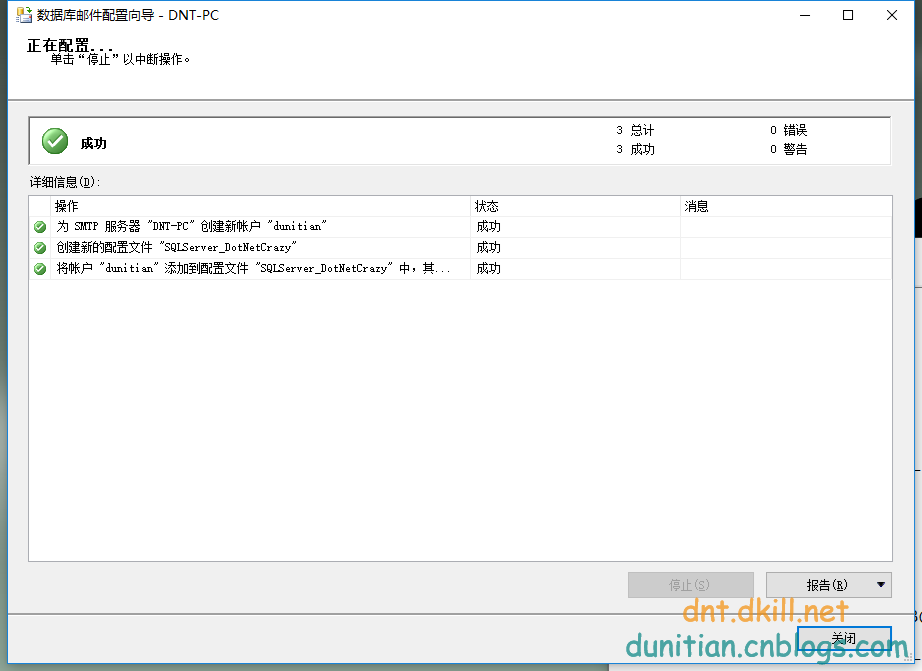
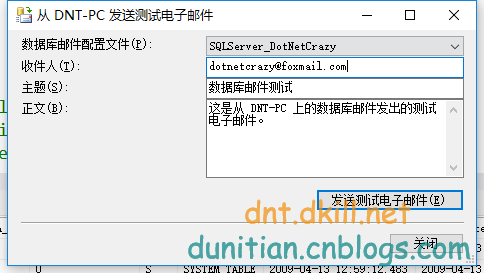
測試一下:
發一封郵件到"我為NET狂"的官方郵件去
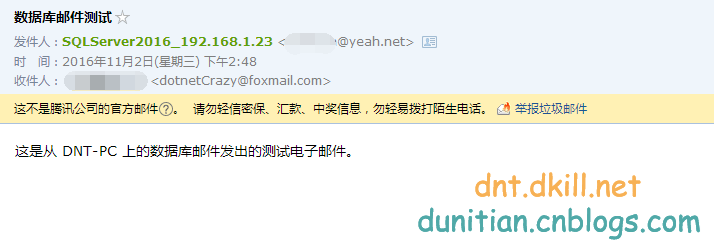
去看看:
命令演示:(不需要記,你又不是DBA,會用即可)

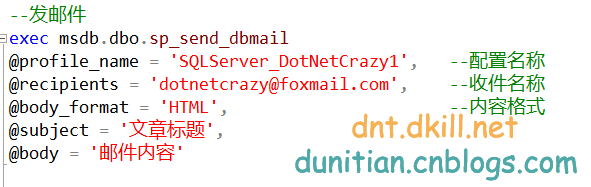
發送郵件腳本:
1
2
3
4
5
6
exec msdb.dbo.sp_send_dbmail
@profile_name = 'SQLServer_DotNetCrazy1', --配置名稱
@recipients = 'dotnetcrazy@foxmail.com', --收件名稱
@body_format = 'HTML', --內容格式
@subject = '文章標題',
@body = '郵件內容'
結果:20的ip也發過來了
--相關查詢
--select * from msdb.dbo.sysmail_allitems
--select * from msdb.dbo.sysmail_faileditems --失敗狀態的消息
--select * from msdb.dbo.sysmail_unsentitems --看未發送的消息
--select * from msdb.dbo.sysmail_sentitems --查看已發送的消息
--select * from msdb.dbo.sysmail_event_log --記錄日記
18. 存儲過程有什麼優點?又有哪些缺點?
存儲過程執行效率高。1.傳輸的字節少響應也就快了嘛;2.存儲過程創建的時候已經預編譯好了,運行時直接進行執行計劃,而傳統的sql腳本得先生成執行計劃再執行。3.SQL注入防護
擴展不方便,比如數據庫是復合的Nosql+MSSQL,代碼修改業務更方便。存儲過程裡面的SQL就不適合了(你SQLServer的腳本總不能和其他NoSQL的通用吧),得抽出來用代碼實現。
19. 數據庫TestStudent中學生表用到了TestMain中的Class表。
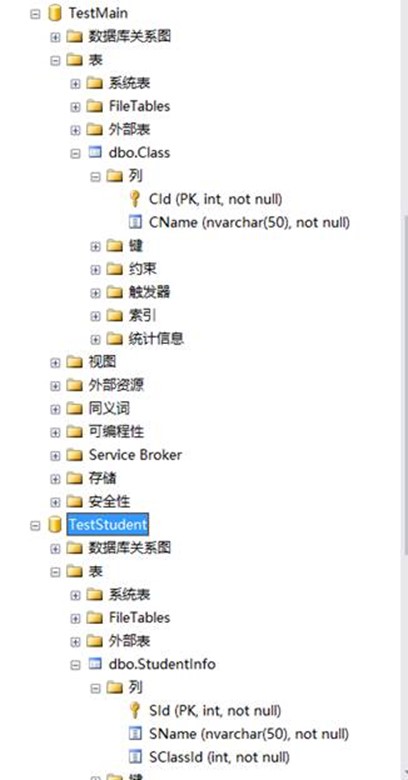
①請查詢一下TestStudent中的學生在哪個班級?
一個服務器,多個數據庫
--跨數據庫查詢
select SId,SName,CName from [TestStudent].[dbo].[StudentInfo] as Student
inner join [TestMain].[dbo].[Class] as Class on Student.SClassId=Class.CId
go
--多個服務器,多個數據庫
--先鏈接服務器
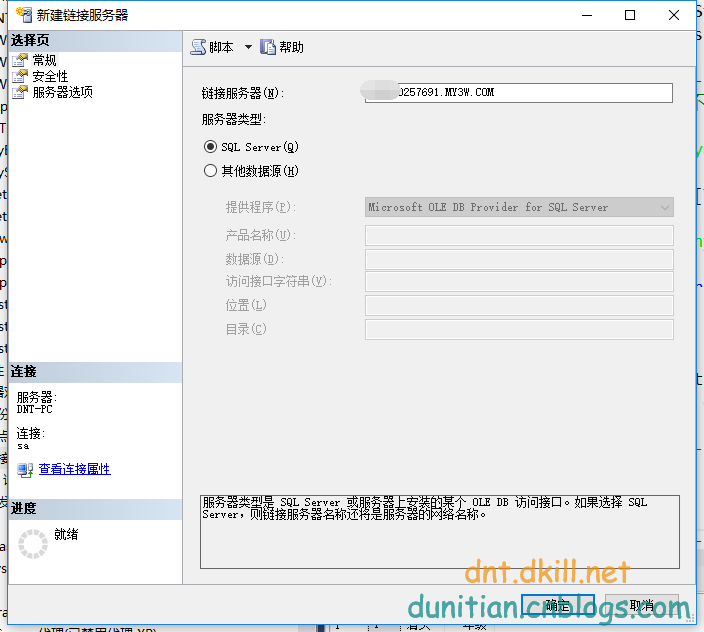
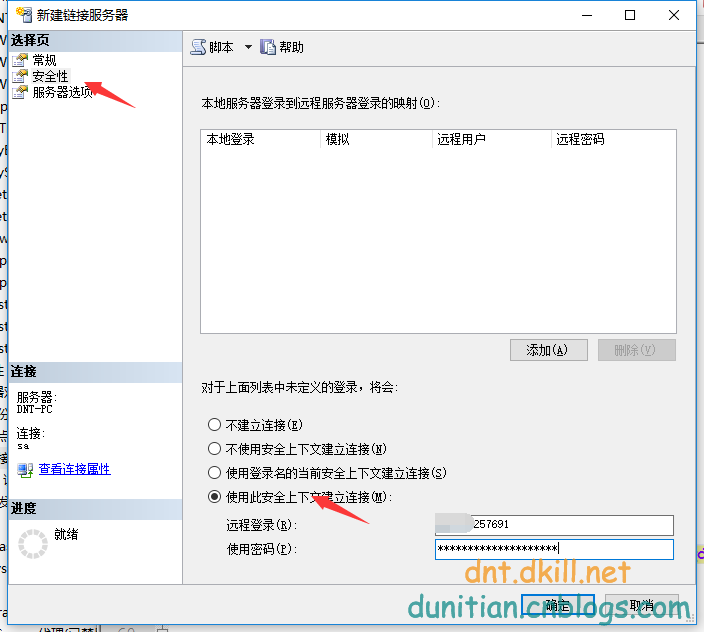
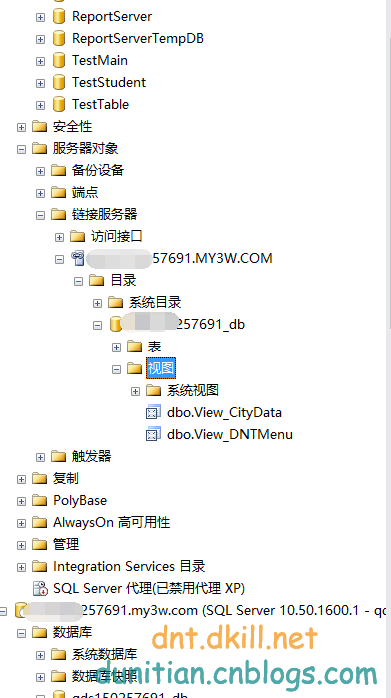
--跨數據庫查詢
select SId,SName,CName from [q***257691.my3w.com].[q***257691_db].[dbo].[StudentInfo] as Student
inner join [TestMain].[dbo].[Class] as Class on Student.SClassId=Class.CId
go
②思考一下要是我修改了TestMain的數據庫名如何避免再次去批量修改SQL?
一個服務器,多個數據庫
--要是我手動改了數據庫名或者表名豈不歇菜?所有就有了同義詞
use TestMain
if(exists(select * from sys.synonyms where name='TestMainClass'))
drop synonym TestMainClass
create synonym TestMainClass for [TestMain].[dbo].[Class]
if(exists(select * from sys.synonyms where name='TestStudentInfo'))
drop synonym TestStudentInfo
create synonym TestStudentInfo for [TestStudent].[dbo].[StudentInfo]
--跨數據庫查詢
use TestMain
select SId,SName,CName from TestStudentInfo as Student
inner join TestMainClass as Class on Student.SClassId=Class.CId
go
--多個服務器,多個數據庫
--先鏈接服務器,再同義詞
--要是我手動改了數據庫名或者表名豈不歇菜?所有就有了同義詞
use TestMain
if(exists(select * from sys.synonyms where name='TestMainClass'))
drop synonym TestMainClass
create synonym TestMainClass for [TestMain].[dbo].[Class]
if(exists(select * from sys.synonyms where name='TestStudentInfo'))
drop synonym TestStudentInfo
create synonym TestStudentInfo for [q***257691.my3w.com].[q***257691_db].[dbo].[StudentInfo]
--跨數據庫查詢
use TestMain
select SId,SName,CName from TestStudentInfo as Student
inner join TestMainClass as Class on Student.SClassId=Class.CId
go
20. 針對索引缺點,項目中我們一般怎麼解決?
讀寫分離(發布訂閱)
讀庫建立索引,寫庫不建立索引
簡單演示一下發布訂閱,具體的可以自行研究:
發布:
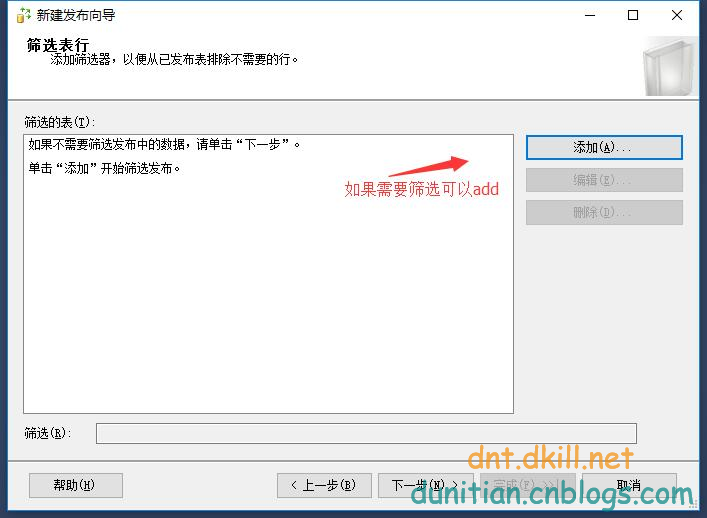
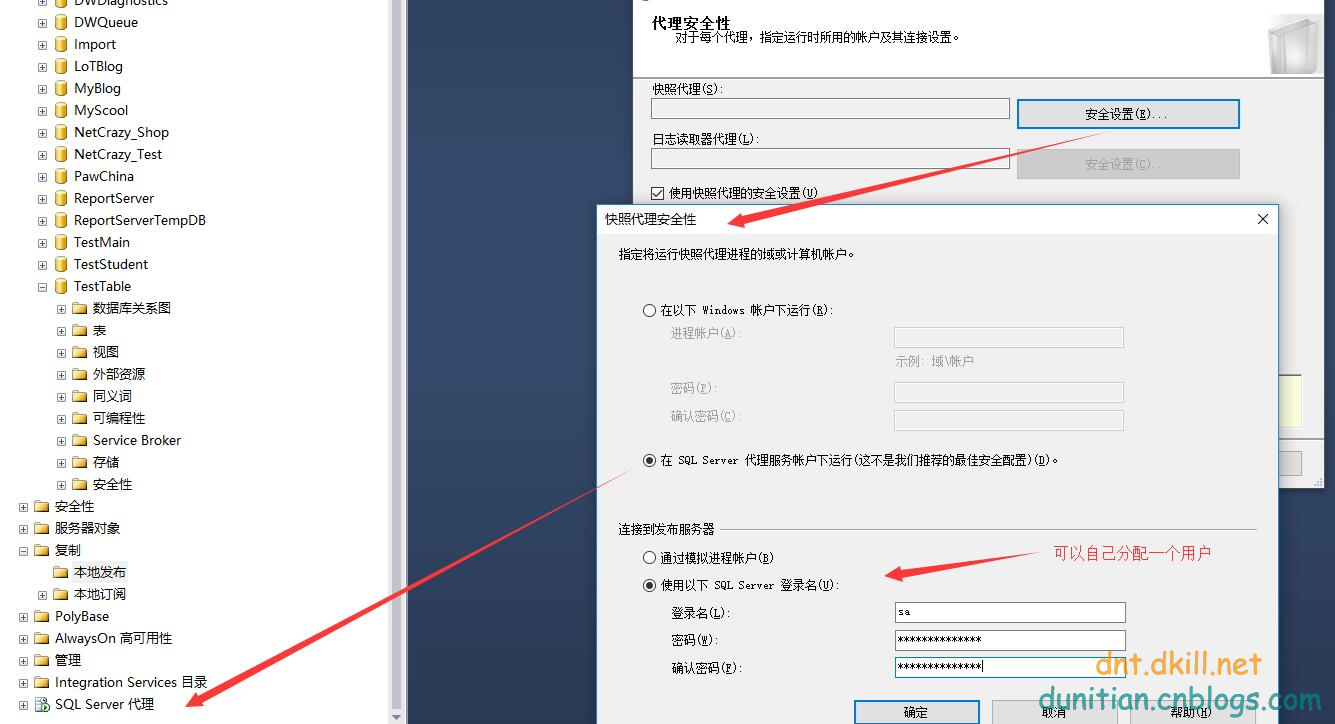
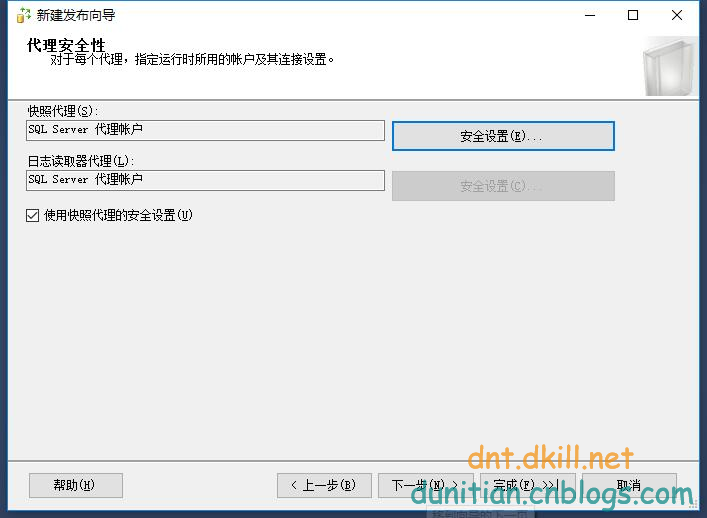
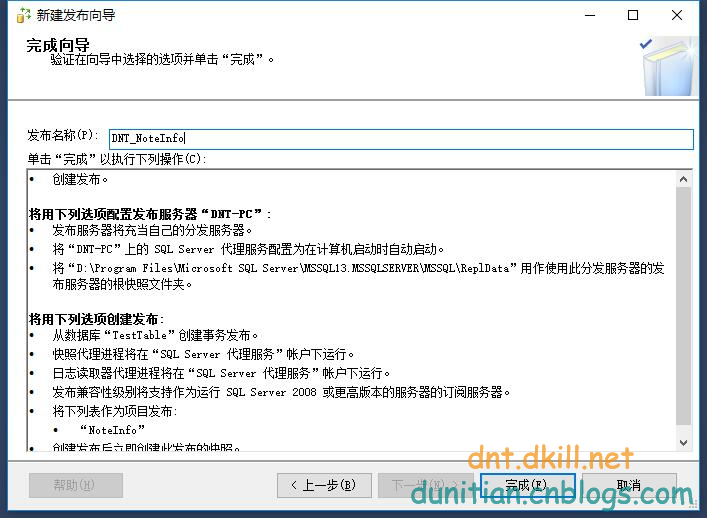
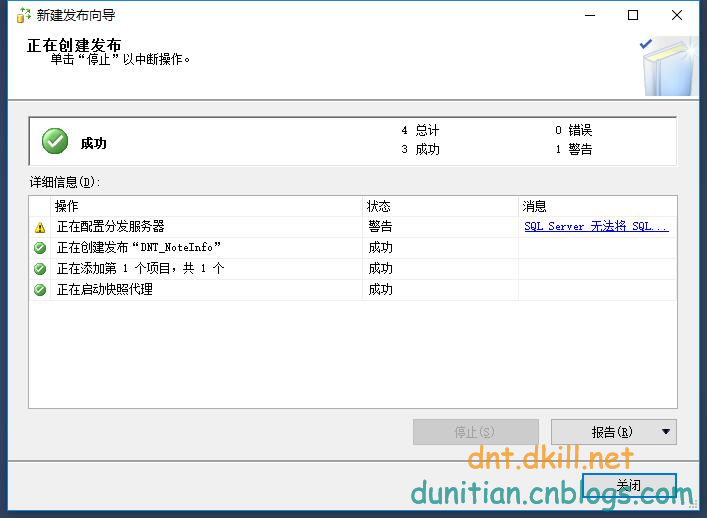
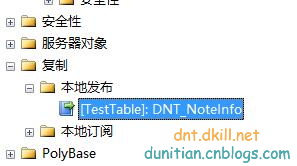
訂閱:
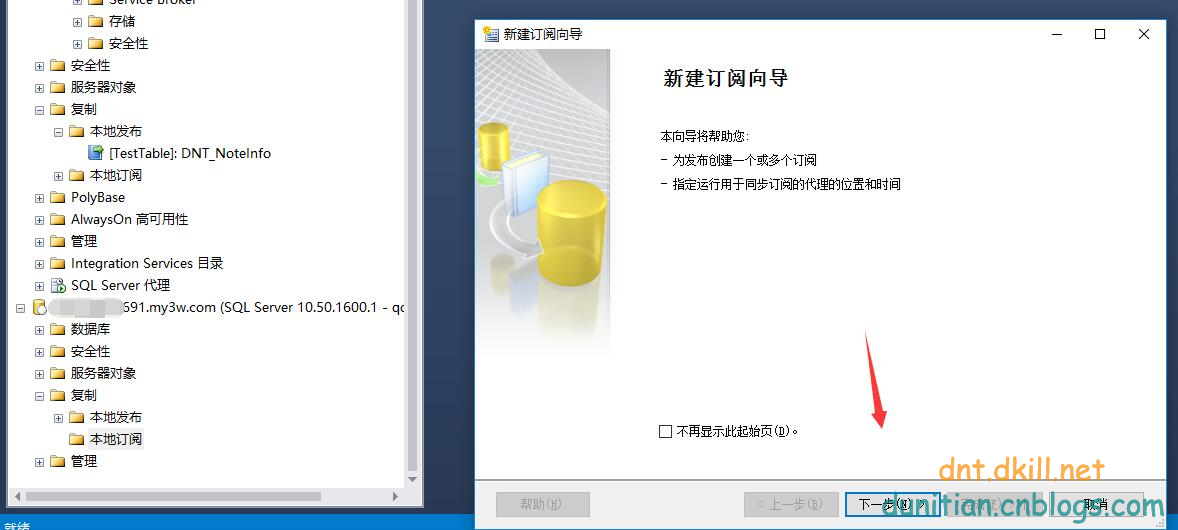
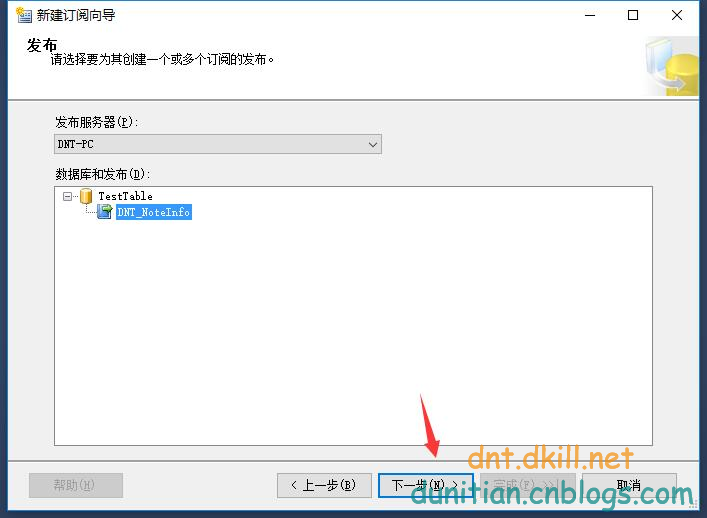
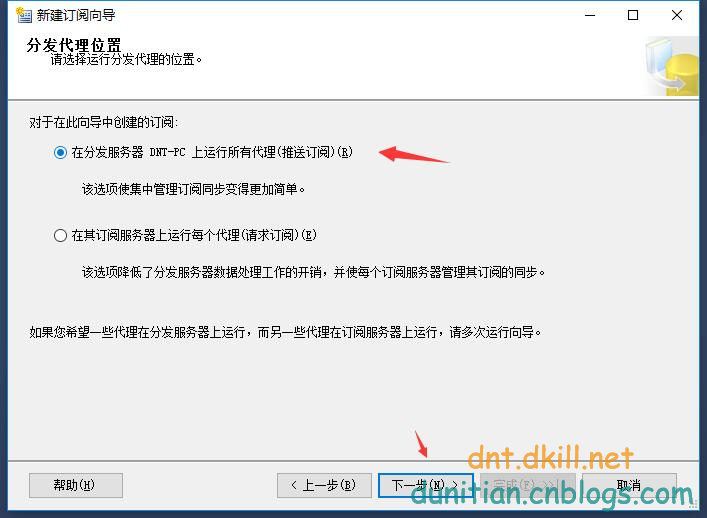
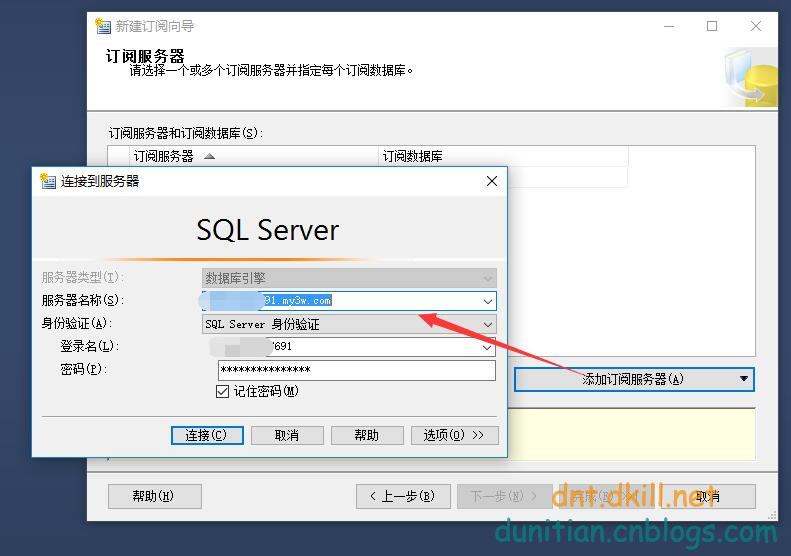
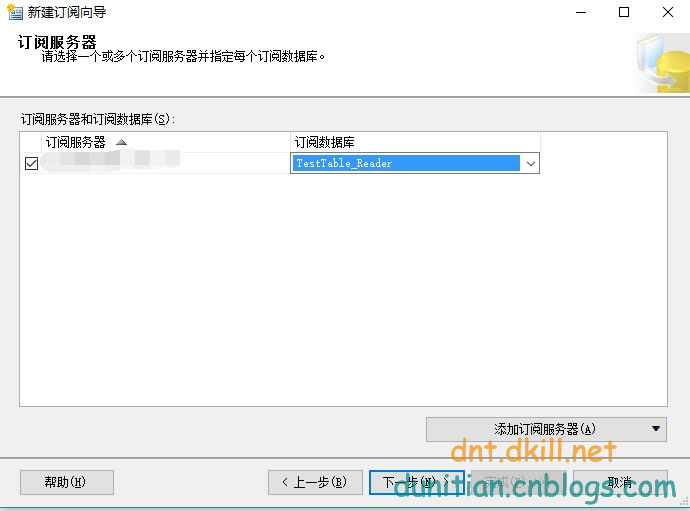
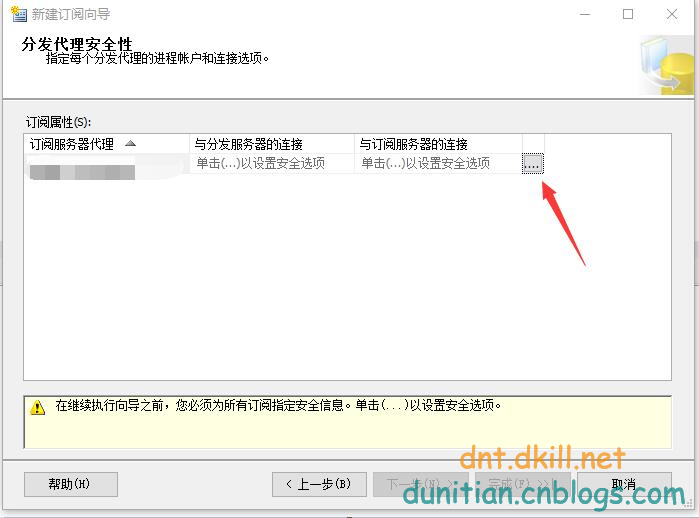
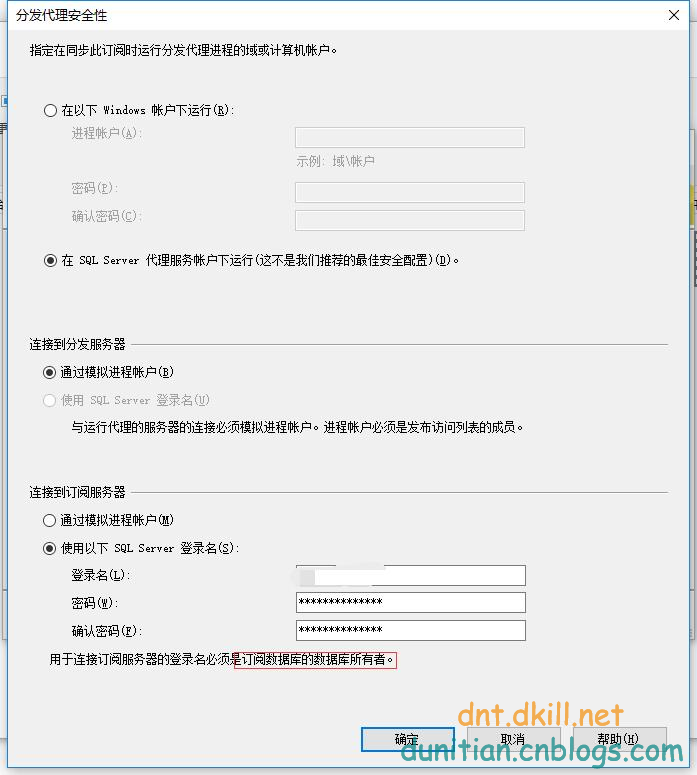
數據同步問題就不用你操心了
21. 隨著業務的發展,你們數據庫層面是怎麼逐步處理的?(我以前在群裡也系統的說過,這個主要考察你是否真正參與一次頗具規模的完整項目中,不一定長篇大論,說你知道的就行了)
先聲明一些,如果有什麼錯誤歡迎反饋,畢竟這個下面的東西都是逆天自己慢慢摸索的,並沒有人指導,所以難免會出錯~~~(還是先說下的好,不然有些不願意分享的人會揪著小問題說啥誤人子弟。PS:逆天寧願別人也這樣誤誤我,自己搗鼓說出來都是淚啊!)
一開始是數據量慢慢大了查詢特別慢,於是在不經常修改又經常使用的列建立了索引,等差不多表裡有100w左右的數據了,開始有點吃不消了,於是就有了分表技術。分表技術很多,hashcode取余,路由表等等。。。剛開始就是偽分表,也就是傳說中的水平分表,還是在一個數據庫裡面,主要目的就是為了解決ID溢出或者單個表數據太多而導致查詢太慢。
後來還是有點吃不消,總不能因為某個表而影響整體性能吧,於是就把這個特別影響數據庫整體性能的表拎出來,放到另外的數據庫裡面,這個就是分庫技術,把一些影響整體性能的表單獨放到其他數據庫裡面叫做垂直分庫,因為不在同一個數據庫了,也就可以不放在一個盤裡面了,大大化解了IO的壓力。後來衍生出了垂直分表的概念(把某些分表放在其他庫裡面,這時候路由表的表名就得寫全了)。
(擴:水平分庫:http://www.cnblogs.com/dunitian/p/5276431.html)
舉了個簡單的例子:
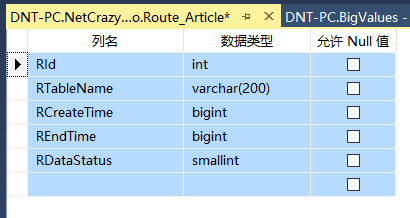
後來系統繼續用繼續用,發現...又不給力了,這時候是服務器瓶頸了(網絡,IO,連接數,CPU,內存等硬件瓶頸),這時候所謂的本機垂直分庫就意義不大了,就有了分布式的概念,分布式分布式,也就是單機變成多機器嘛,這時候sql上遇到各種問題,為了解決這些問題引入了同義詞和鏈接服務器的概念(19題考察的就是這個),這下以為沒啥事情了,發現...什麼情況,增刪改各種慢?查詢倒是還行。
細細研究發現,我去,是索引的問題(16,20題考察的內容)。然後借鑒MySQL的相關概念,他們天天說什麼讀寫分離,那麼我們是不是也可以走一個呢?於是就搞了多個庫,2個讀1個寫。這時候想到一個問題!數據同步怎麼辦?數據怎麼保證一致性?!!!
於是就有了發布訂閱(這個裡面又有兩種,一種是主數據庫一改變就推送給從數據庫,一種是從數據庫定期向主數據庫發起同步請求【效率低】)這種讀寫分離,主數據庫進行增刪改,2個從數據庫只用來查,只給新手讀庫的權限,再也不用擔心他們修改不加where了~
後來就是業務問題了,我點,我點,我再點~我去,報了一個莫名的錯誤怎麼辦?
靠,是誰刪了這條數據!怎麼知道?
靠,磁盤快滿了,怎麼沒人說?!!
不用擔心==》引入數據庫異常預警的功能(XEVENT+數據庫發郵件)【這個是站在前人肩上的成果】
現在:集群怎麼搞?故障轉移怎麼走起?逆天正在研究中........
如果經過上面優化而且數據庫數據不算大(百G左右吧),那麼可以得出個結論==》代碼太爛,重構去,二期走起~
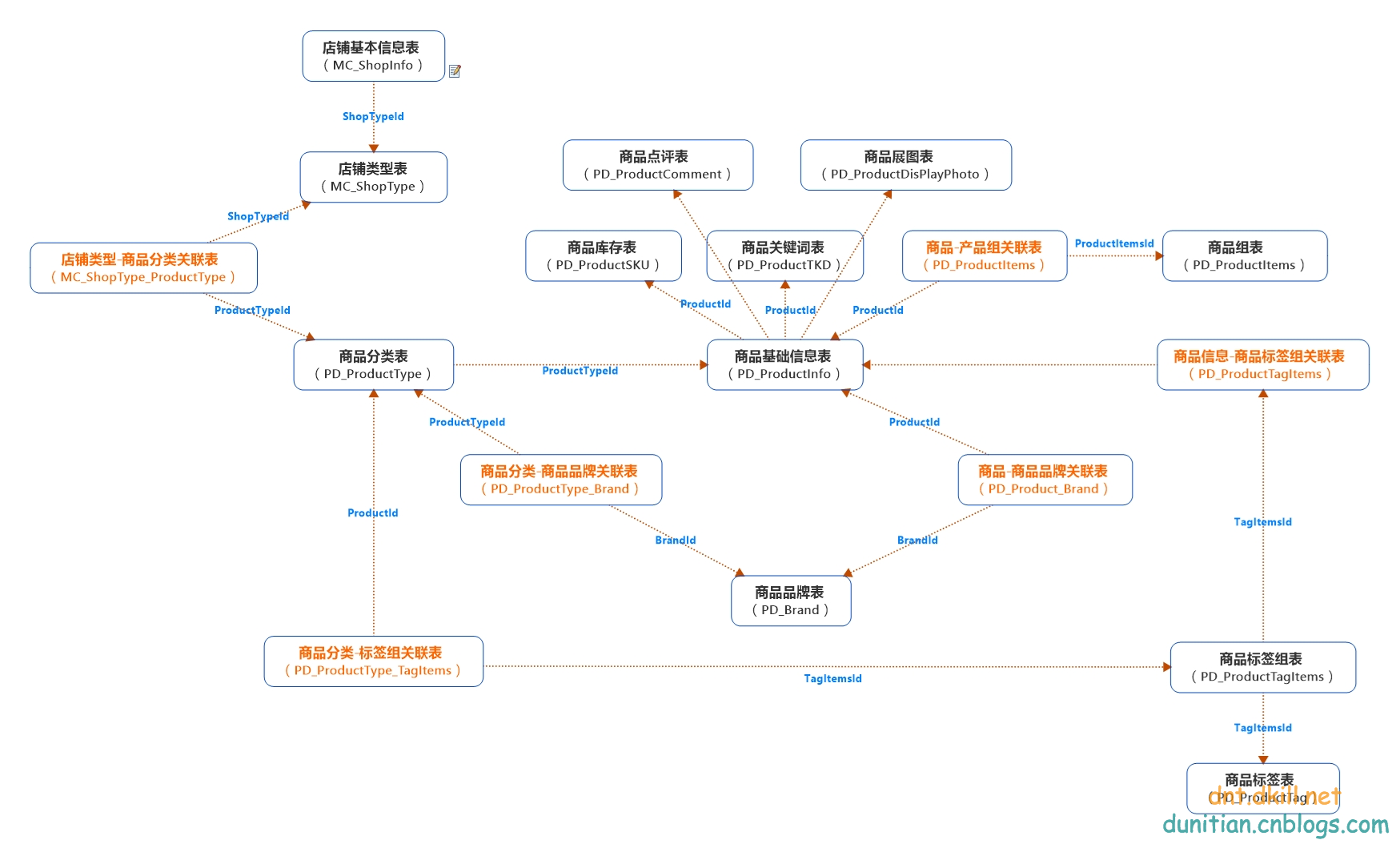
22. 設計題:請根據以下圖設計一下商品相關的簡表(不包含活動、訂單、運費等)
a. 畫出設計圖【主要考察是否有一定的真實項目經歷】
b. 寫出建庫建表語句(每個表數據不少於3個)【主要考察SQL基礎】
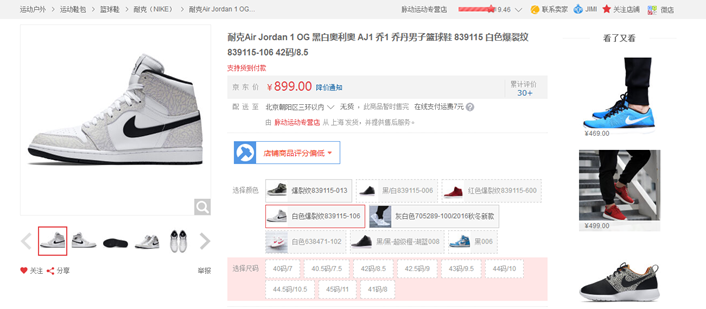
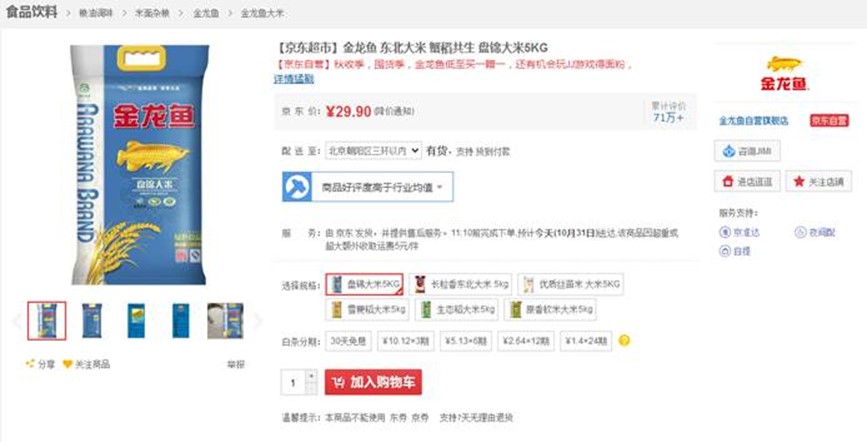
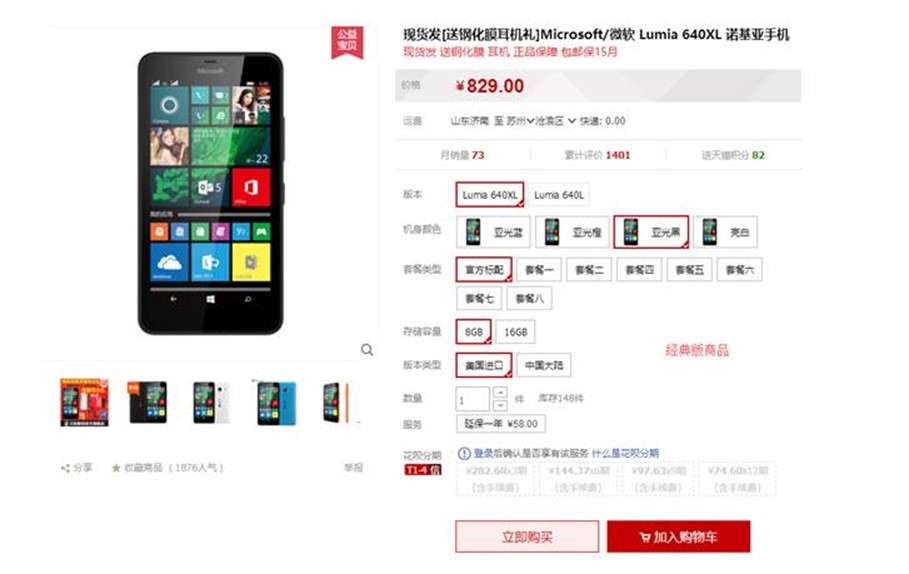
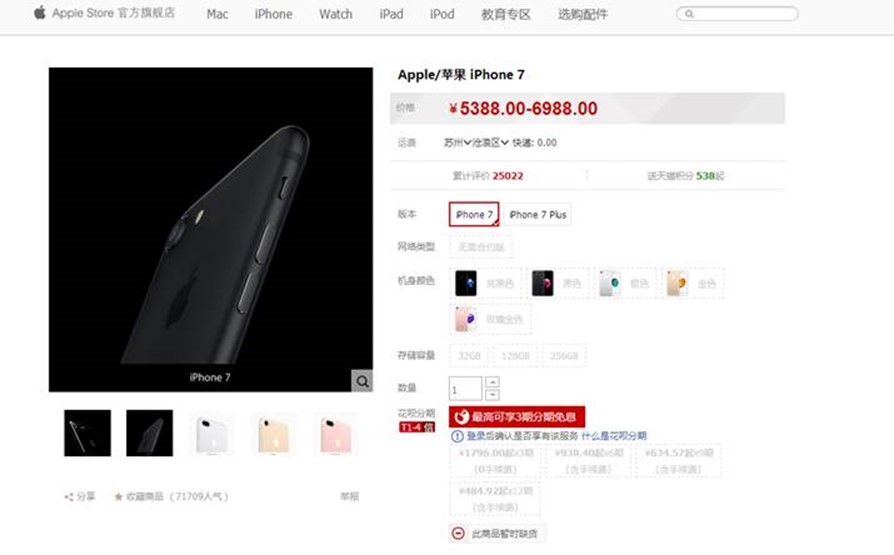
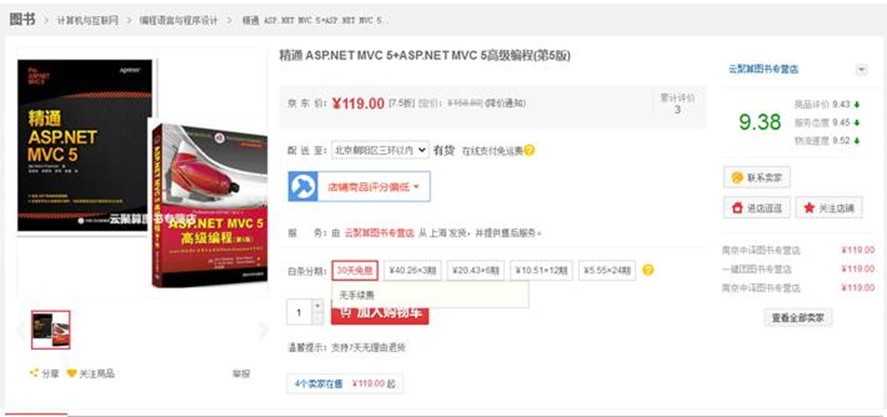
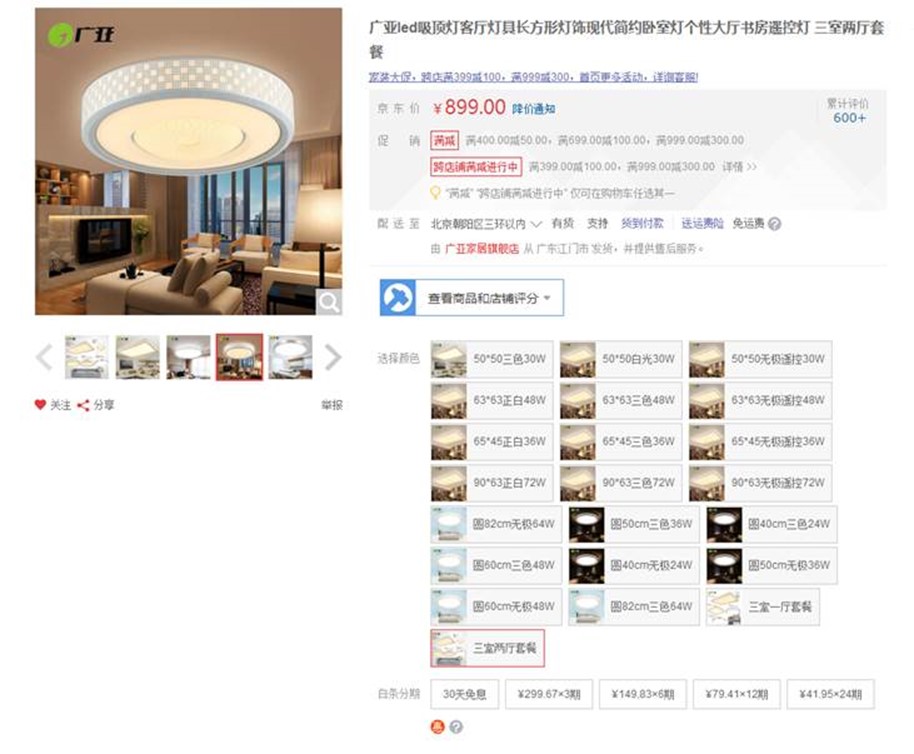
建庫你們就自己慢慢建吧,我簡單設計了一個模型:(有不合理的設計歡迎提出)