懶人學習的過程就是工作中老大讓干啥讓做啥就研究研究啥,國慶放假回來的周末老大通過釘釘給我布置了個任務, RabbitMQ高可用解決方案,我想說釘釘太坑了:

這是國慶過後9號周日晚上下班給的任務,我周一看到的時候一看,下周五,那豈不是21號,時間是如此的充裕!那不還早呢麼。。恰巧同學要面試了9號晚上一起吃飯,然後問了我幾個算法,然後被鄙視了。。他說我一個前端都比你做後台的算法牛逼,你請客吧-。-於是周一到周三光學算法了(程序員為了吹牛逼,哪有啥節操啊)直到周四老大說,明天任務到期了!研究咋樣了!此時才恍然大悟,釘釘你個坑貨,下周五是14號!!
對於RabbitMQ 高可用集群的說明,我覺得這篇文章講的挺詳細的,就不說了。配置集群的方式看官網就可以了 ,為了采取所謂的Active/Active方案,所以只能選鏡像模式了(3.x版本以上才支持).再抄一段解釋過來(與普通集群相比,其實質和普通模式不同之處在於,消息實體會主動在鏡像節點間同步,而不是在 consumer 取數據時臨時拉取。該模式帶來的副作用也很明顯,除了降低系統性能外,如果鏡像隊列數量過多,加之大量的消息進入,集群內部的網絡帶寬將會被這種同步通訊大大消耗掉。所以在對可靠性要求較高的場合中適用),在搭建好RabbitMq集群以後,
鏡像模式可以通過命令行為隊列添加同步策略,比如
為所有隊列應用鏡像模式的策略
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
或者指定指定隊列名的:
rabbitmqctl set_policy yu-ha "^yu" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
或者直接在管理頁面添加
點擊Admin菜單-->右側的Policies選項-->左側最下下邊的Add / update a policy
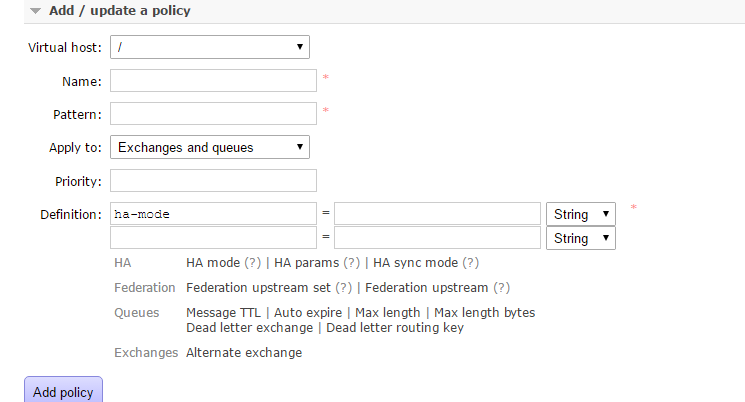
name就是隊列名,Pattern就是匹配的規則,比如寫個^yu就是以yu開頭的隊列,ha-mode=啥就是會同步什麼隊列,比如=all的話就是同步所有匹配的隊列。
然後新建隊列的時候就可以指定那台機器上跑主隊列了。
還是抄一下這篇文章的內容,常用的手段就是通過HAProxy+KeepAlive保證RabbitMq的集群高可用:
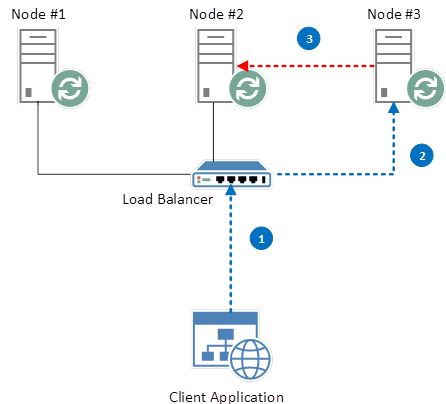
創建 queue 的過程:
假如現在 node2 宕機了:
假設 master queue 還在 node 2 上,客戶端通過 LB 訪問該隊列:
可見,這種配置下,2/3 的客戶端請求需要重定向,這會造成大概率的訪問延遲,但是終究訪問還是會成功的。要優化的話,總共有兩種方式:
為了避免這種n-1/n的這種重定向,知道Master queue所在的節點很重要啊,接下來就不抄了。
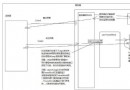
大致的意思就是這張圖:
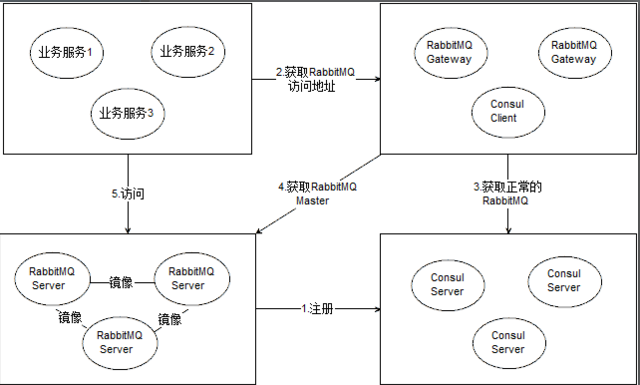
1.將RabbitMq注冊到Consul中(步驟1),通過Consul對RabbitMq進行健康監測,同時Consul提供配置中心的服務,可以存儲一些RabbitMq的配置信息,比如隊列賬號,密碼,隊列主機名,所在Ip等,舉個例子:
將RabbitMq服務注冊到Consul:

{
"services": [{
"id":"rabbit@rabbitmq1",
"name":"RabbitMqServer",
"tags":["rabbitMq"],
"address": "192.168.1.101",
"port": 15672,
"checks": [
{
"Http": "http://192.168.1.101:15672/",
"interval": "10s"
}
]
},
{
"id":"rabbit@rabbitmq2",
"name":"RabbitMqServer",
"tags":["rabbitMq"],
"address": "192.168.1.102",
"port": 15672,
"checks": [
{
"Http": "http://192.168.1.102:15672/",
"interval": "10s"
}
]
}
]
}
View Code
將RabbitMq的隊列信息存入到Consul中:
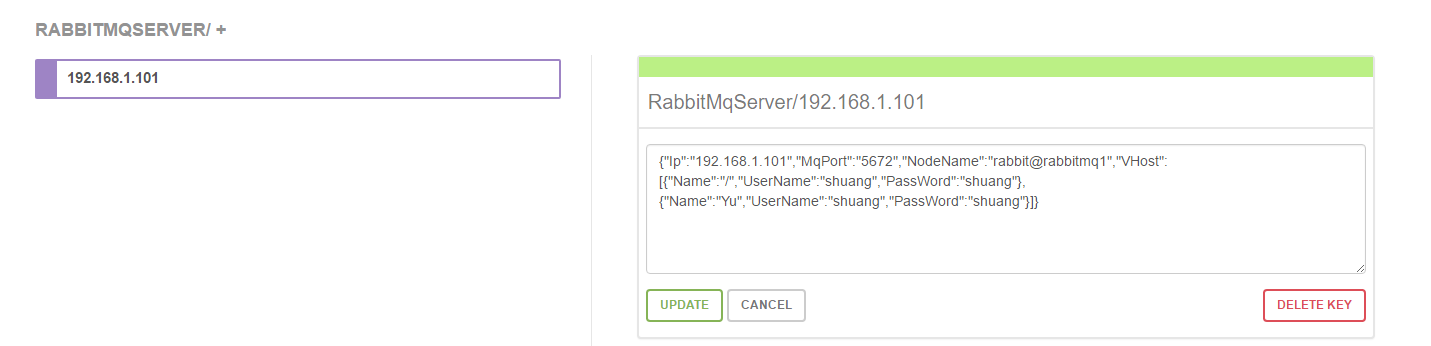
2.業務服務需要配置QueueName+VirthHost,通過步驟2從RabbitMq網關進行隊列信息的獲取,然後才能通過步驟5與隊列進行推拉操作,這裡可以獲取可用隊列對應的Master隊列所在的節點信息,避免n-1/n這種接受推送轉發的問題。
3.RabbitMq網關接受到業務服務的請求後,通過Consul獲取集群中任意一個健康的RabbitMq隊列的信息(Consul提供的健康監測功能),然後根據該隊列獲得與RabbitMq通信的WebApi,RabbitMq的Http Api文檔提供了獲取隊列詳情的接口,比如獲取隊列對用的Master信息是可用通過接口:http://127.0.0.1:15672/api/queues/%2F/yu_queue,%2F對應的是VirthHost,是/的轉碼,yu_queue是隊列名,這倆參數通過業務服務請求Api時提供,通過Api返回的Json字符串中包含了該隊列Master的節點的對用信息,其中node屬性對應的就是rabbitmq的節點名,如:rabbit@rabbitmq1,然後可以通過之前在consul中配置的RabbitMq信息來查找該節點對用的隊列信息返回給業務服務。
這裡會有個坑需要注意:
訪問RabbitMq的Http Api是需要身份驗證的,這個Basic驗證的Token獲取查了查文檔沒找到- -
後來驚奇發現。。 Convert.ToBase64String(Encoding.ASCII.GetBytes(userName + ":" + password))); 哎。。不想多說了。。。
還有個Api參數中帶/的問題,.net 4.5以上的版本用HttpClient沒啥問題,4.5以下版本或者用HttpWebRequest的時候需要對Uri做下處理
public static void ForceCanonicalPathAndQuery(Uri uri)
{
string paq = uri.PathAndQuery; // need to access PathAndQuery
FieldInfo flagsFieldInfo = typeof(Uri).GetField("m_Flags", BindingFlags.Instance | BindingFlags.NonPublic);
ulong flags = (ulong)flagsFieldInfo.GetValue(uri);
flags &= ~((ulong)0x30); // Flags.PathNotCanonical|Flags.QueryNotCanonical
flagsFieldInfo.SetValue(uri, flags);
}
View Code
其實思路很簡單,不過明明可以通過封裝一個SDK(況且本來就得封裝- -)就完成的事情為什麼還要牽扯出Consul和多余的一個RabbitMq網關呢,況且有了RabbitMq網關豈不是說還要單點問題了?!
針對單點問題。。我覺得部署幾份無狀態的網關還是沒啥壓力的吧。。SKD封裝的時候自己輪訓去吧!
對於為什麼要用到Consul,一方面是為了健康監測,健康監測可以讓Consul通過Consul Http Api直接獲取可用的RabbitMq的Http Api信息,還有就是配置中心,業務服務通過配置隊列名,VirthHost,和獲取隊列服務的RabbitMq網關即可,RabbirMq網關負責通過配置中心獲取隊列信息,配置中心的數據是動態的,更新起來也比較方便。
對於為啥不通過SDK直連RabbitMq的Api而是通過網關作為一個中間代理,在通過Consul獲取隊列信息時可以做個定時緩存,而且像隊列的用戶名密碼的這種信息通過業務服務配置的話維護不方便,業務服務通過SDK直接通過Consul獲取的話,依賴關系也會變得略微錯綜復雜。通過RabbitMq的Api也可以動態獲取隊列的集群節點信息,權限信息等,在業務服務SDK裡定期更新也未嘗不可,但SDK終究變復雜了,你干那個多不累麼。。
為什麼參數要VirthHost+QueueName,不同部門的人總歸不是同一個人。。
針對這種思路,對於RabbitMq中的Routing模式和Topic模式會有問題,單routekey對應單隊列時可以通過隊列獲取Exhange下該routekey有效發送到某台服務器上的隊列上,假如該routekey綁定的隊列分布在多台服務器上,並且這些隊列的主從分布在多台服務器上時,我通過獲取到的“Master隊列”只能針對某一隊列時真Master,對於其他隊列如果Master不在該ip上還是會存在轉發的問題。這個問題在拉數據時沒啥問題(拉數據我是需要隊列名的!),推數據時只用到Exchange+RouteKey,誰還管你的隊列是主是從呢?
代碼在整理整理。。。。
參考鏈接:
http://www.cnblogs.com/sammyliu/p/4730517.html
https://insidethecpu.com/2014/11/17/load-balancing-a-rabbitmq-cluster/