tesseract是google的一個開源OCR項目,項目地址已經遷移到github(現在 2016/09),地址 https://github.com/tesseract-ocr/tesseract
首先使用git將代碼clone到本地。使用最新的commit, SHA-1: c943fc1a339d6378f34cccf4ff96949adb2f37ec
編譯步驟參考 https://github.com/tesseract-ocr/tesseract/wiki/Compiling
下面是詳細步驟和相關問題解決方法
我使用的VS2010
1.安裝cmake 並添加到環境變量.下載地址 https://cmake.org/download/
2.安裝cppan 並添加到環境變量,下載地址 https://cppan.org/client/cppan-master-win32-client.zip
3.在你本地的源碼目錄tesseract下執行下列命令
cppan mkdir build && cd build cmake .. -DSTATIC=1
注意:cppan執行過程中可能需要FANQIANG。
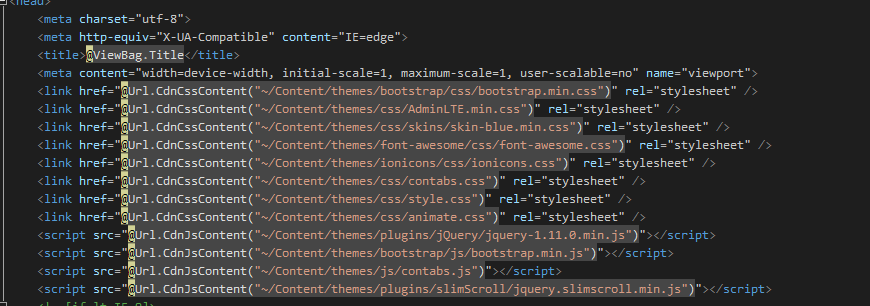
4.在tesseract\build目錄下生成了項目文件,使用VS打開tesseract.sln,如下
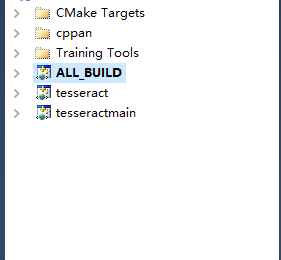
啟動項目是ALL_BUILD,解決方案配置我使用的是 Release。開始編譯,當然這過程中會出現一大堆錯誤和警告,不用理會靜靜等待編譯完成
1.使用可以轉換編碼格式的工具,將 tesseract\ccmain\equationdetect.cpp 的格式轉化下。 我使用的是 Notepad ++ ,格式->轉為 ANSI 編碼格式
原因:tesseract的源文件的編碼格式是UTF-8的,但是中文系統下VS裡的代碼頁編碼格式是GB2312
2.bool相關,根據錯誤信息定位到pvt.cppan.demo.gif這個項目,我的是 pvt.cppan.demo.gif-5.1.4.vcxproj ,雙擊打開之,然後在項目中找到 stdbool.h,然後將
#define bool _bool
更換為
#define bool int
3. snprintf相關,根據錯誤信息定位到pvt.cppan.demo.tiff這個項目,我的是 pvt.cppan.demo.tiff-4.0.6,雙擊打開之,然後在項目中找到 tiffiop.h ,定位到
#if !defined(HAVE_SNPRINTF) && !defined(HAVE__SNPRINTF) #undef snprintf
將下面的3行換成
#define snprintf _snprintf //extern int snprintf(char* str, size_t size, const char* format, ...); #endif
然後切換到 tesseract.sln ,清理解決方案重新編譯一遍。
然後將 tesseractmain 設為啟動項目,編譯。
編譯步驟到此結束,可執行文件在 tesseract\build\bin\Release 下,但是現在還不能直接用,沒有語言包。
語言包下載地址
英文 https://github.com/tesseract-ocr/tessdata/raw/master/eng.traineddata
簡中 https://github.com/tesseract-ocr/tessdata/raw/master/chi_sim.traineddata
繁中 https://github.com/tesseract-ocr/tessdata/raw/master/chi_tra.traineddata
創建一個tessdata目錄,和tesseract.exe同級,將下載的語言包復制到tessdata目錄下。然後打開cmd,執行命令就可以看到結果
tesseract.exe test.png -l eng+chi_sim result
test.png 是待識別的圖片
-l eng+chi_sim 指定識別語言為英文和簡體中文,多語言使用+連接
result 指定輸出的文本文件
更多的命令請參考 https://github.com/tesseract-ocr/tesseract/wiki/Command-Line-Usage