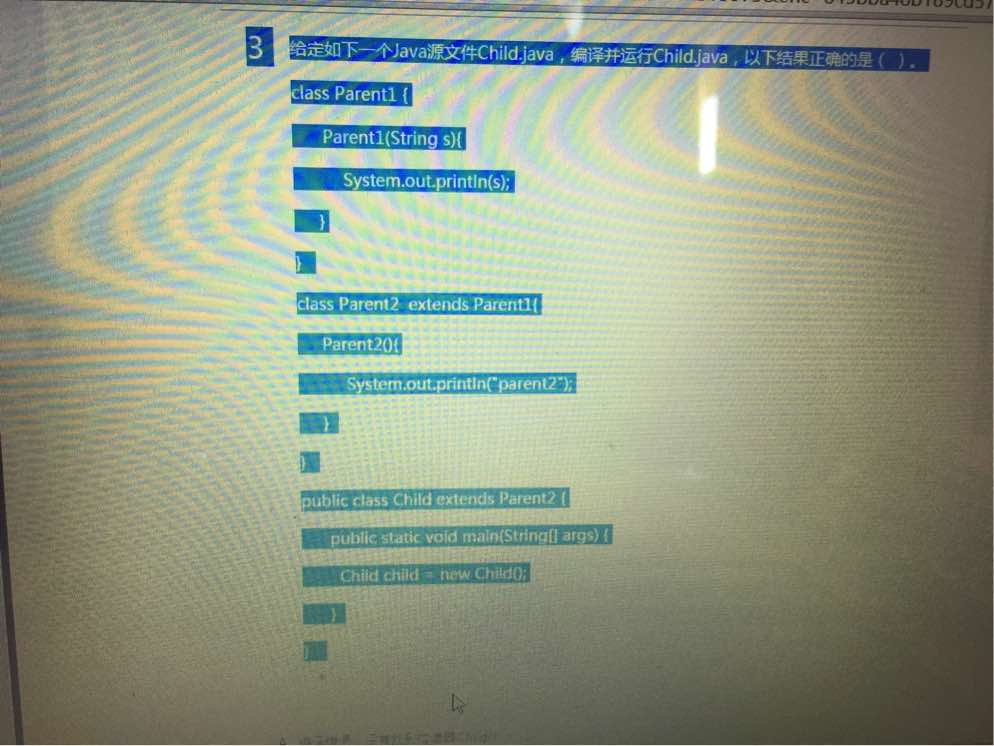
用Java編寫一個程序,對於輸入的一段英語文本,可以統計:
1、該文本中有多少英語單詞;
2、該文本中有多少不同的英語單詞。
如,輸入 I am a good student. I am in Zhengzhou.
則可以統計出有9個英語單詞、7個不同的英語單詞。
首先,需要對輸入信息進行處理,去掉輸入的標點符號,並以空格替換,需要用正則表達式,進行全部替換;
其次,就是對輸入單詞進行統計,使用字符串的分割函數split(" "),以空格分割;
最後,就是遍歷分割結果,進行統計,用Map,以單詞為key,出現次數為value。
實例代碼如下:
import java.util.HashMap;
import java.util.Map;
public class Tee {
/**
* 正則去除所有的英文標點符號
*/
public static String formatInput(String input) {
if (input == null) {
return null;
}
return input.replaceAll("[.|;|\\?]", " ");
}
public static Map<String, Integer> countWords(String input) {
Map<String, Integer> result = new HashMap<String, Integer>();
if (input == null || input.length() == 0) {
return result;
}
// 用字符串的分割函數
String[] split = input.split(" ");
if (split == null || split.length == 0) {
return result;
}
// 統計存入Map,word為key,出現次數為value
for (String value : split) {
if (result.containsKey(value)) {
// 出現過,直接累計+1
result.put(value, result.get(value) + 1);
} else {
// 沒出現過存入
result.put(value, 1);
}
}
return result;
}
public static void main(String[] args) {
String value = "I am a good student.I am in Zhengzhou.Ha?";
String format = formatInput(value);
System.out.println(format);
Map<String, Integer> r = countWords(format);
System.out.println(r.toString());
}
}