從詞典文件中讀取數據,輸出的時候為什麼顯示亂碼?
代碼如下:
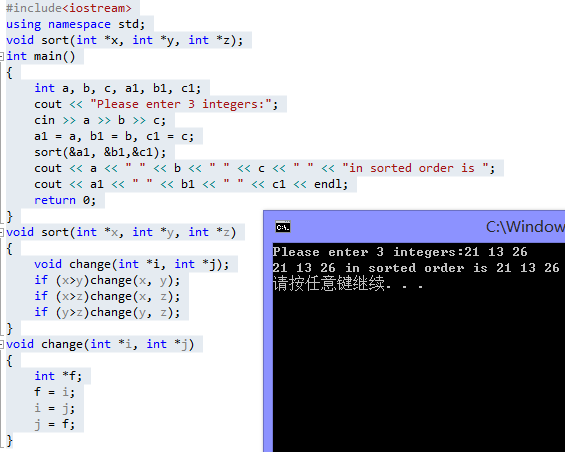
#include
2 #include
3
4 int main()
5 {
6 FILE *fp = fopen("text.txt","r");
7 char english[32],chinese[64],attribute[8];
8 int i=0,j=0,k=0;
9 int flag_null = 0, flag_p = 0;
10 while(!feof(fp))
11 {
12 char ch = fgetc(fp);
13 if(ch == ' ')
14 {
15 flag_null = 1;
16 }
17
18 if(ch == '.')
19 {
20 flag_p = 1;
21 }
22 if(flag_null!=1)
23 {
24 english[i] = ch;
25 i++;
26 }
27 else if(isalpha(ch)||ch=='.')
{
29 attribute[k] = ch;
30 k++;
31 }
32 else if(ch < 0)
33 {
34 chinese[j] = ch;
35 j++;
36 }
37
38 if(ch == '\n')
39 {
40 printf("%s %s %s\n",english,chinese,attribute);
41 }
42
43 }
44
45 fclose(fp);
46 }
text.txt文件內容
across prep.橫越 adv.橫穿
輸出:
across .??越橫穿? prep.adv.??越橫穿?
漢字編碼格式跟英文字符編碼格式是不一樣的。標准C語言庫函數不能直接處理漢字。
%c,%s只能處理ASCII在[32,127]區間的字符輸出。漢字編碼超過這個范圍了