請教:從HDFS裡讀一個文件,map開拿出數據,轉換成dataframe類型,再放入phoenix裡面。轉換成dataframe後,為什麼給數據自動加一個前綴"_1","_2"。這樣導致數據放入phoenix的時候,列簇對應不上,phoenix表已經創建好,定義過列簇名,下面是代碼,和報錯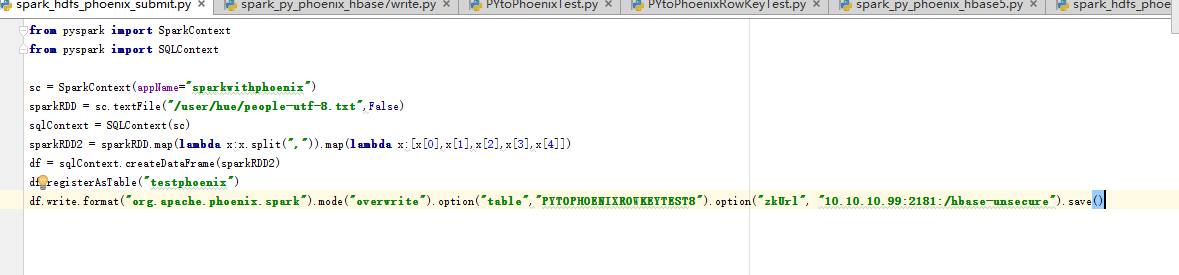
我創建phoenix表的行鍵列簇名字已經定義好了:HANGJIAN , LIECU ,LIECU2 ,LEICU5 ,HANGJIAN5
spark轉換rdd的時候自動添加了"_1", "_2","_3"' "_4", "_5"
能不能轉換數據的時候 ,不自動 加: _1 _2 等等前綴,直接讓數據存入phoenix表中。請問大神們是怎麼做的?
問題搞定了
df = sqlContext.createDataFrame(sparkRDD2,["HANGJIAN","LIECU","LIECU2","LIECU5","HANGJIAN5"])
這是官網的
from pyspark.sql import Row
Person = Row('name', 'age')
person = rdd.map(lambda r: Person(*r))
df2 = sqlContext.createDataFrame(person)
df2.collect()
[Row(name=u'Alice', age=1)]