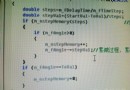
package IkLucene;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class IKAnalyzerTest {
public static void main(String[] args) {
String keyWord = "自動化物流系統,規劃,管理流程,效益";
//創建IKAnalyzer中文分詞對象
IKAnalyzer analyzer = new IKAnalyzer();
// 使用智能分詞
analyzer.setUseSmart(true);
// 打印分詞結果
try {
printAnalysisResult(analyzer, keyWord);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 打印出給定分詞器的分詞結果
*
* @param analyzer
* 分詞器
* @param keyWord
* 關鍵詞
* @throws Exception
*/
private static void printAnalysisResult(Analyzer analyzer, String keyWord)
throws Exception {
System.out.println("["+keyWord+"]分詞效果如下");
TokenStream tokenStream = analyzer.tokenStream("content",
new StringReader(keyWord));
tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset(); //新版中需要有這麼個reset,不可遺漏!
while (tokenStream.incrementToken()) {
CharTermAttribute charTermAttribute = tokenStream
.getAttribute(CharTermAttribute.class);
System.out.println(charTermAttribute.toString());
}
}
}
上面代碼中keyword不管怎麼變,結果卻都是一樣的。求幫忙看看錯哪了?
http://www.lxway.com/950465564.htm