看深入理解計算機系統裡面。關於規格化的一段描述:
......也就是說,指數的值是E=e-Bias,其中e是無符號數,其位表示為ek-1···e1e0,而Bias是一個
等於2k-1 -1(單精度是127,雙精度是1023)的偏置值。....
我知道C語言單精度的指數位是8位,取值范圍是-126到127.但是我對E=e-Bias不理解。這裡的e代表的是什麼?本人小白求解釋。。
e就是你的指數值,給個例子
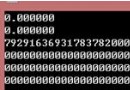
0100 0010 1**111 0110 0000 0000 0000 0000**
第一個粗體的0是符號位,後面的10000101 = 133(十進制),這個是個單精度數,bias=127,所以指數是E - bias = 133 - 127 = 6
第二個粗體長串111 0110 0000 0000 0000 0000是你的小數部分.111011
這個數字的F = .111011 + 1 = 1.111011
這個的值 = 1.111011 x 2^6 = 1111011 = 123
這裡之所以采用bias是因為指數從0~255,如何表示負數(小於1)的數,采用的是e - bias。(e大於127,是大於1,e小於127是小於1)。這樣既可以表示大的數,也可以表示非常小的數(2的-128次方)。