小弟我曾經寫過HttpClient的網絡爬蟲 但是那種爬蟲對於html內部內嵌的js無能為力,有的js會有跳轉指令
所以想到利用開源的浏覽器實現真實模擬訪問+抓取正確內容(總之就是要實現真實的訪問) 查詢了c++的js引擎有duktape(這個好像只是js執行器),v8 浏覽器內核有webkit 但是確實不知該怎麼下手 不知有哪位朋友做過類似的東西,可否給些提示? 萬分感謝
c++用webkit來加載頁面執行js,然後得到頁面的dom內容等。
求解 C語言的數組問題
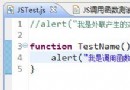
初學JS遇到的問題,求指教
懸賞40分 全英文的介紹的簡
關於C++函數指針數組問題
linux io 讀取文件問
如何跳出紅蜘蛛的監控?