1、讀取“d:/users/v-lingao/from_lei/wordsegmentation/testdata”目錄下的所有txt文檔,利用Parallel.For並行處理各個txt文檔中的內容,每次讀取一行存儲到string line中,利用line = sr.ReadLine() (StreamReader sr); 沒處理一行也入“d:/users/v-lingao/from_lei/wordsegmentation/testdata1”目錄下新創建的對應的txt文件中。方法ComputeIDF()實現次功能。
2、讀取在“d:/users/v-lingao/from_lei/wordsegmentation/testdata1”目錄下創建的txt文件,利用Parallel.For並行處理每個txt文檔中的內容,類似於ComputeIDF()方法,利用line = sr.ReadLine().。法ComputingTfIdf()實現此功能。錯誤也就出現在此方法中,錯誤提示根據寫入文件時編碼方式的不同有所改變。
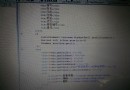
部分代碼如下所示:
public static Dictionary ComputeIDF(List stopWordsList)
{
DirectoryInfo di = new DirectoryInfo(@"d:/users/v-lingao/from_lei/wordsegmentation/testdata");
FileInfo[] ff = di.GetFiles("*.txt");
Dictionary featureDoc = new Dictionary();
Parallel.For(0, ff.Length, (part) =>
{
FileInfo file = ff[part];
Dictionary<string, int> featureFile = new Dictionary<string,int>();
string name = file.Name.Substring(file.Name.LastIndexOf("\\") + 1);
string path = Path.Combine(@"d:/users/v-lingao/from_lei/wordsegmentation/testdata1", name);
FileStream aFile = new FileStream(path, FileMode.Create);
StreamWriter sw = new StreamWriter(aFile, Encoding.UTF8);
int lineCount = 0;
char[] charArray = new char[] { ' ' };
StreamReader sr = new StreamReader(file.OpenRead(),Encoding.UTF8);
string line = sr.ReadLine();
while (line != null)
{
//部分代碼省略
lineCount++;
sw.Write(lineCount);
foreach (KeyValuePair<string, int> keyvalue in featureLine)
{
sw.Write(' ' + keyvalue.Key + ':' + (0.5 + 0.5 * ((float)keyvalue.Value / maxCount)));
}
sw.WriteLine();
line = sr.ReadLine();
}
//combine the featureFiles into featureDoc without repeating
featureDoc.Add(featurename, featureFile[featurename]);
sr.Close();
sw.Close();
});
Dictionary<string, float> idf = new Dictionary<string, float>();
foreach (KeyValuePair<string, int> keyvalue in featureDoc)
{
idf.Add(keyvalue.Key, (float)Math.Log10((float)sumLine / (float)keyvalue.Value));
}
return idf;
}
這個方法沒有問題。接下來是ComputingTfIdf(idf),問題出在這個方法中。
public static void ComputingTfIdf(Dictionary idf)
{
DirectoryInfo dir = new DirectoryInfo(@"d:/users/v-lingao/from_lei/wordsegmentation/testdata1");
FileInfo[] ff = dir.GetFiles("*.txt");
StreamReader sr;
Parallel.For(0, ff.Length, (part) =>
{
FileInfo file = ff[part];
List<string> idfList = new List<string>();
idfList.AddRange(idf.Keys);
int linenum = 0;
sr = new StreamReader(file.OpenRead(),Encoding.UTF8);
char[] charArray = new char[] { ' ' };
char[] charArray1 = new char[] { ':' };
string name = file.Name.Substring(file.Name.LastIndexOf("\\") + 1);
string path = Path.Combine(@"d:/users/v-lingao/from_lei/wordsegmentation/idfdata", name);
FileStream aFile = new FileStream(path, FileMode.Create);
StreamWriter sw = new StreamWriter(aFile, Encoding.UTF8);
** *string line = sr.ReadLine();* ** //這行有時也會出錯
while (line != null)
{
linenum++;
string[] words = line.Split(charArray);
int i = 1;
foreach (string word in words)
{
if (i == 1)
{
sw.Write(word + ' ');
i++;
}
else
{
string[] wds = word.Split(charArray1);
if (wds.Length == 2)
{
string key = wds[0];
if (idf.Keys.Contains(key))
{
double tfidf = (double)idf[key] * (Convert.ToDouble(wds[1]));
sw.Write(idfList.IndexOf(key)+ ':'+tfidf +' ');
}
}
}
}
sw.WriteLine();
** *line = sr.ReadLine();* ** //問題常常出現在這行
}
}
sw.Close();
});
}
錯誤提示根據寫入文件時編碼方式的不同有所改變。當讀取、寫入文件用UTF8或者Unicode時,寫入和讀取的都是亂碼,並且line = sr.ReadLine()出錯,錯誤提示為: ** The output char buffer is too small to contain the decoded characters, encoding 'Unicode (UTF-8)' fallback 'System.Text.DecoderReplacementFallback' **
很是無語,功能相同的代碼,為什麼ComputeIDF()方法中line = sr.ReadLine()就不出錯。我將編碼換成Encoding.GetEncoding("GBK")讀寫文件不會出現亂碼,但line = sr.ReadLine()還是出錯,相當無語!
還有就是當不用並行處理Parallel.For,而是用for循環時也不出錯。
求大俠幫忙,不勝感激!
問題在朋友的幫助下已經解決,很感謝我的朋友!
現在把結果和大家分享下,希望遇到類似問題的同仁能從中有所啟發。
用並行處理Parallel.For,要特別注意局部變量的位置。在我的代碼中sr是在Parallel.For結構外面定義的,這樣在執行的過程中幾個線程會共享一個sr,最終導致異常的產生。