1.前言
早期的人臉識別主要是針對面部幾何特征進行分析,Francis Galton於1910年提出了主要集中於檢測重要的人臉特征或是關鍵點的方法,利用眼角、嘴角、鼻尖以及臉頰等關鍵點之間的相應距離進行運算,以此來構造一個表述單個人臉信息的特征向量,然後與未知人臉的特征向量進行比較,選出距離最小的作為識別的結果。1966年,Bledsoe建立了一個半自動的人臉識別系統。該系統對人臉進行分類的特征來自人臉圖像的眼角、嘴角、鼻尖、和下巴等的距離和比例信息。隨後,貝爾實驗室的Goldstein,Harmon等把分類特征增加到21個(如頭發的形狀,耳朵的長度,嘴唇的厚度等),並利用分類器實現了人臉識別。由於上述分類特征都來自主觀的評價,這個階段對人臉識別的研究主要依賴於手工操作,很難進行自動化推廣。Kanade’s於1973采用自頂向下的控制策略,第一次實現了自動人臉識別系統。進入二十世紀九十年代以來,人臉自動識別取得了重大進展,出現了許多新方法,這些方法具有更高的識別率和自動化程度,部分技術已經推廣應用,產生了一些人臉識別系統。
本文通過Delphi調用Matlab,利用libsvm軟件包,實現了一個基於PCA+SVM的實用人臉自動識別系統。
2 識別系統框圖
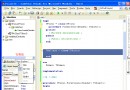
2.1 人臉圖像處理:

圖1 識別系統圖像處理流程圖
2.2 訓練和識別:
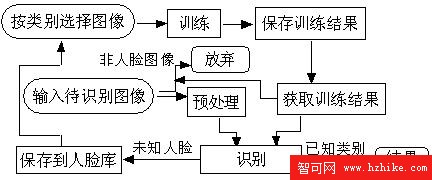
圖2 訓練和識別流程圖
3 算法實現
3.1 算法的matlab實現框圖
Matlab有強大的矩陣數值運算功能,其附帶的各種圖像處理工具箱可以方便對數字圖像進行各種處理,是理想的人臉識別系統仿真工具,可以有效的檢測各種算法的有效性。
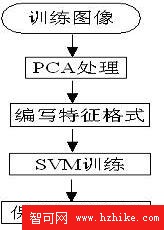
圖3 算法的matlab實現框圖
3.2 LIBSVM軟件包
LIBSVM[4]是台灣大學林智仁(Lin Chih-Jen)副教授等開發設計的一個簡單、易於使用和快速有效的SVM模式識別與回歸的軟件包,不但提供了編譯好的可在Windows系統下執行的文件,還提供了源代碼,方便改進、修改以及在其它操作系統上應用;該軟件對SVM所涉及的參數調節相對比較少,提供了很多的默認參數,利用這些默認參數就可以解決很多問題;並且提供了交互檢驗的功能。
該軟件可以解決C-SVM分類、ν-SVM分類、ε-SVM回歸和ν-SVM回歸等問題,包括基於一對一算法的多類模式識別問題。因此,本文利用LIBSVM實現SVM的人臉分類。
LIBSVM的輸入數據有嚴格的格式,因此在利用該軟件進行SVM計算之前必須將所使用的數據文件轉換成能夠用於LIBSVM的格式。
LIBSVM的所要求的數據格式如下:
<label> <index1>:<value1> <index2>:<value2> ...
其中<label> 是訓練數據集的目標值,對於分類,它是標識某類的整數(支持多個類,如+1,-1或者1,2,3等);對於回歸,是任意實數。<index> 是以1開始的整數,可以是不連續的;<value>為實數,表示自變量。
格式例子:
+1 1:0.291667 2:1 3:1 4:-0.132075 5:-0.237443 6:-1
-1 1:0.25 2:1 3:1 4:-0.226415 5:-0.506849 6:-1
LIBSVM軟件DOS命令執行方式來實現其提供的各種功能。本文主要用到兩個程序,svmtrain和svmpredict。其中svmtrain 用於對人臉訓練數據進行建模,svmpredict則利用建立的模型進行人臉分類。
Svmtrain的用法:
svmtrain [options] training_file [TrainResult_file]
training_file為待訓練的數據集;TrainResult_file為訓練後建立的模型;如果TrainResult_file參數沒有,則程序將自動建立training_file.model的模型文件。Options為訓練參數。
Svmpredict的用法:
svmpredict test_file TrainResult_file Result_file
test_file為待識別(測試)數據;TrainResult_file為svmtrain訓練後建立的模型;
Result_file為識別(測試)結果。
3.3 Delphi和matlab的交互
(1) Delphi聲明變量:
MatLabOLEWin : Variant;
(2) Delphi中啟動Matlab程序:
MatLabOLEWin := CreateOLEObject('Matlab.Application');
(3) Matlab訓練結果的保存和調入:
fidout=fopen('irow.txt','wt'); %保存變量值
fprintf(fidout,'%2dn',irow);
fclose(fidout);
save m.mat m %保存矩陣
fid=fopen('irow.txt','r') %讀取變量值
irow= fscanf(fid,'%5d')
fclose(fid);
m=[];%讀取矩陣
load m.mat m;
(4) matlab調用LIBSVM的方法:(假設svmtrain和svmpredict程序在matlab當前工作目錄下)
SVM訓練:
DOS(['svmtrain -s 3 -c 1 FaceFeactureSpace.dat TrainResult.dat']);
說明:s為選擇的多項式內積函數的自由度,c為終止條件,FaceFeactureSpace.dat為PCA算法得到的訓練圖像的臉空間數據,TrainResult.dat為訓練產生的模型文件;FaceFeactureSpace.dat的格式要符合libsvm的數據格式要求。
SVM測試:
DOS(['svmpredict NewFace.dat TrainResult.dat Result.txt']);
說明: NewFace.dat為待識別人臉圖像的特征數據,其格式也要符合libsvm的數據格式要求,其中的label可以用一個數表示,也可以空著不填。Result.txt內為識別結果。
4 系統的使用
4.1 訓練過程
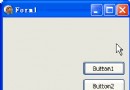
人臉數據庫采用已處理的ORL人臉庫的人臉圖像。每人隨機選擇5張圖像作為訓練樣本,其余5張作為測試樣本。選擇測試選項(如圖4所示),啟動Matlab進行訓練。訓練結果保存到本地,供識別使用。
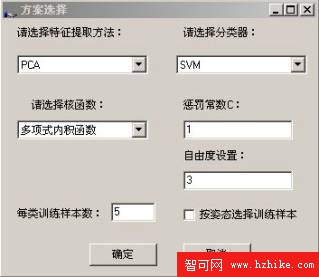
圖4 選擇訓練方案
4.2 識別過程
把待識別圖像向訓練過程產生的特征空間投影,根據投影距離判斷是否包含人臉,如無人臉,則退出識別過程,操作結束。
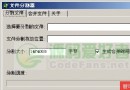
對待識別的人臉圖像進行預處理,並向訓練過程產生的特征空間投影,投影結果利用訓練過程產生的訓練結果通過支持向量機進行分類識別。正確分類則結束(如圖5所示)。
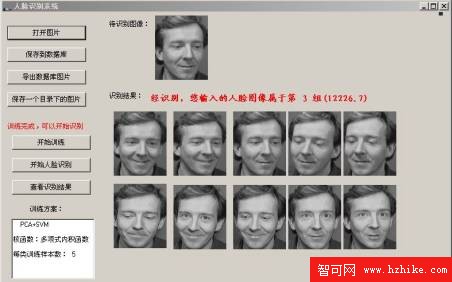
圖5 識別結果圖
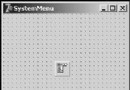
由於參數的選擇等問題,分類結果會出現誤差,分類結果可能不唯一,則給出可能屬於其他類的提示(如圖6所示)。待識別人臉圖像本來屬於第一類,但識別結果為第2類,對比誤差參數,給出也可能屬於第一類的結果。

圖6 識別誤差提示
對無法歸入當前任一類別的人臉圖像,保存到人臉庫,增加一個新的類別,重新進行訓練樣本的選擇,獲取新的訓練結果,以備下次識別使用。
4.3 系統的實驗結果
利用多姿態人臉庫[5],對原始ORL人臉庫和處理後的ORL人臉庫采用不同的核函數進行識別實驗,每類選擇200張圖片進行訓練(共40人,每人5張),其余200張作為測試。核函數采用多項式內積函數和徑向基函數兩種。多項式內積函數的自由度分別選擇1,2,3,4,徑向基函數的參數選擇0.3,系統的實驗結果如下:
表1 支持向量機分類實驗結果表
人臉數據庫
采用不同的核函數的SVM分類器的識別率
多項式函數
徑向基函數
q=1
q=2
q=3
q=4
原始ORL人臉庫
90.3%
91%
91.8%
90.8%
91%
處理後的ORL人臉庫
97.3%
98%
98.5%
97.5%
98%
5 結論
從表1可以看出,並不是多項式內積函數的自由度越高識別率越高,當q=3時識別效果是最好的。原因是隨著自由度的提高,支持向量的個數也有明顯的增加,這不僅導致識別率降低,而且運算速度明顯變慢。原始ORL人臉數據庫和處理後的人臉數據庫在識別率上差別較大,是因為經過圖像預處理後,干擾因素大大減少,而且光照和姿態得到了較好的控制。對比徑向基函數和多項式內積函數的識別結果,可以看出,支持向量機在核函數的選擇上對性能影響較小,相反核函數參數的選擇則對識別結果有較大的影響。