這篇文章主要介紹了在Python程序中實現分布式進程的教程,在多進程編程中十分有用,示例代碼基於Python2.x版本,需要的朋友可以參考下
在Thread和Process中,應當優選Process,因為Process更穩定,而且,Process可以分布到多台機器上,而Thread最多只能分布到同一台機器的多個CPU上。
Python的multiprocessing模塊不但支持多進程,其中managers子模塊還支持把多進程分布到多台機器上。一個服務進程可以作為調度者,將任務分布到其他多個進程中,依靠網絡通信。由於managers模塊封裝很好,不必了解網絡通信的細節,就可以很容易地編寫分布式多進程程序。
舉個例子:如果我們已經有一個通過Queue通信的多進程程序在同一台機器上運行,現在,由於處理任務的進程任務繁重,希望把發送任務的進程和處理任務的進程分布到兩台機器上。怎麼用分布式進程實現?
原有的Queue可以繼續使用,但是,通過managers模塊把Queue通過網絡暴露出去,就可以讓其他機器的進程訪問Queue了。
我們先看服務進程,服務進程負責啟動Queue,把Queue注冊到網絡上,然後往Queue裡面寫入任務:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # taskmanager.py import random, time, Queue from multiprocessing.managers import BaseManager # 發送任務的隊列: task_queue = Queue.Queue() # 接收結果的隊列: result_queue = Queue.Queue() # 從BaseManager繼承的QueueManager: class QueueManager(BaseManager): pass # 把兩個Queue都注冊到網絡上, callable參數關聯了Queue對象: QueueManager.register('get_task_queue', callable=lambda: task_queue) QueueManager.register('get_result_queue', callable=lambda: result_queue) # 綁定端口5000, 設置驗證碼'abc': manager = QueueManager(address=('', 5000), authkey='abc') # 啟動Queue: manager.start() # 獲得通過網絡訪問的Queue對象: task = manager.get_task_queue() result = manager.get_result_queue() # 放幾個任務進去: for i in range(10): n = random.randint(0, 10000) print('Put task %d...' % n) task.put(n) # 從result隊列讀取結果: print('Try get results...') for i in range(10): r = result.get(timeout=10) print('Result: %s' % r) # 關閉: manager.shutdown()請注意,當我們在一台機器上寫多進程程序時,創建的Queue可以直接拿來用,但是,在分布式多進程環境下,添加任務到Queue不可以直接對原始的task_queue進行操作,那樣就繞過了QueueManager的封裝,必須通過manager.get_task_queue()獲得的Queue接口添加。
然後,在另一台機器上啟動任務進程(本機上啟動也可以):
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 # taskworker.py import time, sys, Queue from multiprocessing.managers import BaseManager # 創建類似的QueueManager: class QueueManager(BaseManager): pass # 由於這個QueueManager只從網絡上獲取Queue,所以注冊時只提供名字: QueueManager.register('get_task_queue') QueueManager.register('get_result_queue') # 連接到服務器,也就是運行taskmanager.py的機器: server_addr = '127.0.0.1' print('Connect to server %s...' % server_addr) # 端口和驗證碼注意保持與taskmanager.py設置的完全一致: m = QueueManager(address=(server_addr, 5000), authkey='abc') # 從網絡連接: m.connect() # 獲取Queue的對象: task = m.get_task_queue() result = m.get_result_queue() # 從task隊列取任務,並把結果寫入result隊列: for i in range(10): try: n = task.get(timeout=1) print('run task %d * %d...' % (n, n)) r = '%d * %d = %d' % (n, n, n*n) time.sleep(1) result.put(r) except Queue.Empty: print('task queue is empty.') # 處理結束: print('worker exit.')任務進程要通過網絡連接到服務進程,所以要指定服務進程的IP。
現在,可以試試分布式進程的工作效果了。先啟動taskmanager.py服務進程:
?
1 2 3 4 5 6 7 8 9 10 11 12 $ python taskmanager.py Put task 3411... Put task 1605... Put task 1398... Put task 4729... Put task 5300... Put task 7471... Put task 68... Put task 4219... Put task 339... Put task 7866... Try get results...taskmanager進程發送完任務後,開始等待result隊列的結果。現在啟動taskworker.py進程:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 $ python taskworker.py 127.0.0.1 Connect to server 127.0.0.1... run task 3411 * 3411... run task 1605 * 1605... run task 1398 * 1398... run task 4729 * 4729... run task 5300 * 5300... run task 7471 * 7471... run task 68 * 68... run task 4219 * 4219... run task 339 * 339... run task 7866 * 7866... worker exit.taskworker進程結束,在taskmanager進程中會繼續打印出結果:
?
1 2 3 4 5 6 7 8 9 10 Result: 3411 * 3411 = 11634921 Result: 1605 * 1605 = 2576025 Result: 1398 * 1398 = 1954404 Result: 4729 * 4729 = 22363441 Result: 5300 * 5300 = 28090000 Result: 7471 * 7471 = 55815841 Result: 68 * 68 = 4624 Result: 4219 * 4219 = 17799961 Result: 339 * 339 = 114921 Result: 7866 * 7866 = 61873956這個簡單的Manager/Worker模型有什麼用?其實這就是一個簡單但真正的分布式計算,把代碼稍加改造,啟動多個worker,就可以把任務分布到幾台甚至幾十台機器上,比如把計算n*n的代碼換成發送郵件,就實現了郵件隊列的異步發送。
Queue對象存儲在哪?注意到taskworker.py中根本沒有創建Queue的代碼,所以,Queue對象存儲在taskmanager.py進程中:
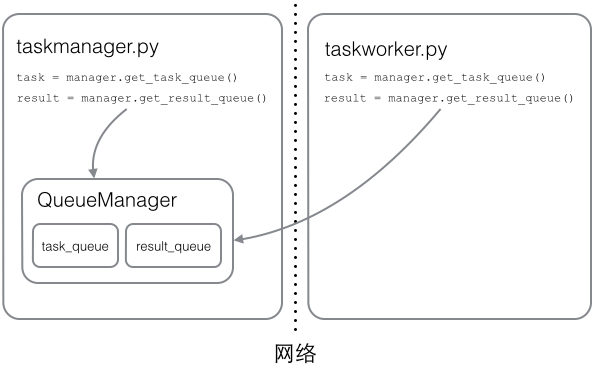
而Queue之所以能通過網絡訪問,就是通過QueueManager實現的。由於QueueManager管理的不止一個Queue,所以,要給每個Queue的網絡調用接口起個名字,比如get_task_queue。
authkey有什麼用?這是為了保證兩台機器正常通信,不被其他機器惡意干擾。如果taskworker.py的authkey和taskmanager.py的authkey不一致,肯定連接不上。
小結
Python的分布式進程接口簡單,封裝良好,適合需要把繁重任務分布到多台機器的環境下。
注意Queue的作用是用來傳遞任務和接收結果,每個任務的描述數據量要盡量小。比如發送一個處理日志文件的任務,就不要發送幾百兆的日志文件本身,而是發送日志文件存放的完整路徑,由Worker進程再去共享的磁盤上讀取文件。