利用Python實現簡單的相似圖片搜索的教程
這篇文章主要介紹了利用Python實現簡單的相似圖片搜索的教程,文中的示例主要在一個圖片指紋數據庫中實現,需要的朋友可以參考下

由於投入了數以百萬計的風險資本(在US大蕭條之前),他們關於真愛並找尋靈魂伴侶的在線廣告勢如破竹。Forbes(福布斯,美國著名財經雜志)采訪了他們。全國性電視節目也對他們進行了專訪。早期的成功促成了事業起步時讓人垂涎的指數級增長現象——他們的用戶數量以每月加倍的速度增長。對他們而言,一切都似乎順風順水。
但他們有一個嚴重的問題——色情問題。
該約會網站的用戶中會有一些人上傳色情圖片,然後設置為其個人頭像。這種行為破壞了很多其他用戶的體驗——導致很多用戶取消了會員。
可能對於現在的一些約會網站隨處可見幾張色情圖片也許並不能稱之為是問題。或者可以說是習以為常甚至有些期待,只是一個被接受然後被無視的在線約會的副產品。
然而,這樣的行為既不應該被接受也應該被忽視。
別忘了,這次創業可是將自己定位在優秀的約會天堂,免於用戶受到困擾其他約會網站的污穢和垃圾的煩擾。簡而言之,他們擁有很實在的以風險資本作為背後支撐的名聲,而這也正是他們需要保持的風格。
該約會網站為了能迅速阻止色情圖片的爆發可以說是不顧一切了。他們雇傭了圖片論壇版主團隊,真是不做其他事只是每天盯著監管頁面8個小時以上,然後移除任何被上傳到社交網絡的色情圖片。
毫不誇張的說,他們投入了數萬美元(更不用說數不清的人工小時)來解決這個問題,然而也僅僅只是緩解,控制情況不變嚴重而不是在源頭上阻止。
色情圖片的爆發在2009年的七月達到了臨界水平。8個月來第一次用戶量沒能翻倍(甚至已經開始減少了)。更糟糕的是,投資者聲稱若該公司不能解決這個問題將會撤資。事實上,污穢的潮汐早已開始沖擊這座象牙塔了,將它推翻流入大海也不過是時間問題。
正在這個約會網站巨頭快要撐不住時,我提出了一個更魯棒的長期解決方案:如果我們使用圖片指紋來與色情圖片的爆發斗爭呢?
你看,每張圖片都有一個指紋。正如人的指紋可以識別人,圖片的指紋能識別圖片。
這促使了一個三階段算法的實現:
1. 為不雅圖片建立指紋,然後將圖片指紋存儲在一個數據庫中。
2. 當一個用戶上傳一份新的頭像時,我們會將它與數據庫中的圖片指紋對比。如果上傳圖片的指紋與數據庫任意一個不雅圖片指紋相符,我們就阻止用戶將該圖片設置為個人頭像。
3. 當圖片監管人標記新的色情圖片時,這些圖片也被賦予指紋並存入我們的數據庫,建立一個能用於阻止非法上傳且不斷進化的數據庫。
我們的方法,盡管不十分完美,但是也卓有成效。慢慢地,色情圖片爆發的情況有所減慢。它永遠不會消失——但這個算法讓我們成功將非法上傳的數量減少了80%以上。
這也挽回了投資者的心。他們繼續為我們提供資金支持——直到蕭條到來,我們都失業了。
回顧過去時,我不禁笑了。我的工作並沒持續太久。這個公司也沒有堅持太久。甚至還有幾個投資者卷鋪蓋走人了。
但有一樣確實存活了下來。提取圖片指紋的算法。幾年之後,我把這個算法的基本內容分享出來,期望你們可以將它應用到你們自己的項目中。
但最大的問題是,我們怎麼才能建立圖片指紋呢?
繼續讀下去一探究竟吧。
即將要做的事情
我們打算用圖片指紋進行相似圖片的檢測。這種技術通常被稱為“感知圖像hash”或是簡單的“圖片hash”。
什麼是圖片指紋/圖片哈希
圖片hash是檢測一張圖片的內容然後根據檢測的內容為圖片建立一個唯一值的過程。
比如,看看本文最上面的那張圖片。給定一張圖片作為輸入,應用一個hash函數,然後基於圖片的視覺計算出一個圖片hash。相似的圖片也應當有相似的hash值。圖片hash算法的應用使得相似圖片的檢測變得相當簡單了。
特別地,我們將會使用“差別Hash”或簡單的DHash算法計算圖片指紋。簡單來說,DHash算法著眼於兩個相鄰像素之間的差值。然後,基於這樣的差值,就建立起一個hash值了。
為什麼不使用md5,sha-1等算法?
不幸的是,我們不能在實現中使用加密hash算法。由於加密hash算法的本質使然,輸入文件中非常微小的差別也能造成差異極大的hash值。而在圖片指紋的案例中,我們實際上希望相似的輸入可以有相似的hash輸出值。
圖片指紋可以用在哪裡?
正如我上面舉的例子,你可以使用圖片指紋來維護一個保存不雅圖片的數據庫——當用戶嘗試上傳類似圖片時可以發出警告。
你可以建立一個圖片的逆向搜索引擎,比如TinEye,它可以記錄圖片以及它們出現的相關網頁。
你還可以使用圖片指紋幫助管理你個人的照片收集。假設你有一個硬盤,上面有你照片庫的一些局部備份,但需要一個方法刪除局部備份,一張圖片僅保留一份唯一的備份——圖片指紋可以幫你做到。
簡單來說,你幾乎可以將圖片指紋/哈希用於任何需要你檢測圖片的相似副本的場景中。
需要的庫有哪些?
為了建立圖片指紋方案,我們打算使用三個主要的Python包:
PIL/Pillow用於讀取和載入圖片
ImageHash,包括DHash的實現
以及NumPy/SciPy,ImageHash的依賴包
你可以使用下列命令一鍵安裝所需要的必備庫:
?
1 $ pip install pillow imagehash第一步:為一個圖片集建立指紋
第一步就是為我們的圖片集建立指紋。
也許你會問,但我們不會,我們不會使用那些我為那家約會網站工作時的色情圖片。相反,我創建了一個可供使用的人工數據集。
對計算機視覺的研究人員而言,數據集CALTECH-101 是一個傳奇般的存在。它包含來自101個不同分類中的至少7500張圖片,內容分別有人物,摩托車和飛機。
從這7500多張圖片中,我隨機的挑選了17張。
然後,從這17張隨機挑選的圖片中,以幾個百分點的比例隨機放大/縮小並創建N張新圖片。這裡我們的目標是找到這些近似副本的圖片——有點大海撈針的感覺。
你也想創建一個類似的數據集用於工作嗎?那就下載CALTECH-101 數據集,抽取大概17張圖片即可,然後運行repo下的腳本文件gather.py。
回歸正題,這些圖片除了寬度和高度,其他各方面都是一樣的。而且因為他們沒有相同的形狀,我們不能依賴簡單的md5校驗和。最重要的是,有相似內容的圖片可能有完全不相同的md5哈希。然而,采取圖片哈希,相似內容的圖片也有相似的哈希指紋。
所以趕緊開始寫代碼為數據集建立指紋吧。創建一個新文件,命名為index.py,然後開始工作:
?
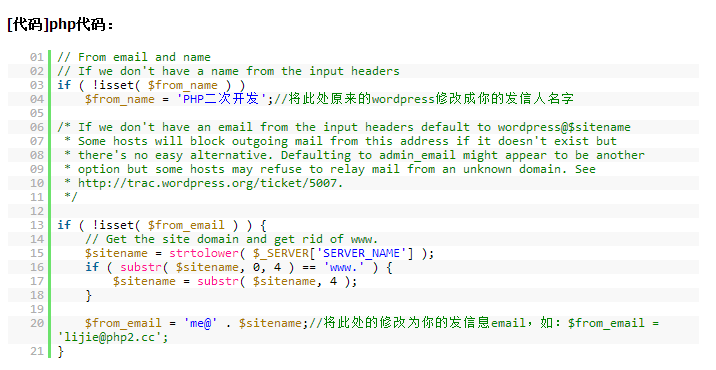
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # import the necessary packages from PIL import Image import imagehash import argparse import shelve import glob # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-d", "--dataset", required = True, help = "path to input dataset of images") ap.add_argument("-s", "--shelve", required = True, help = "output shelve database") args = vars(ap.parse_args()) # open the shelve database db = shelve.open(args["shelve"], writeback = True)要做的第一件事就是引入我們需要的包。我們將使用PIL或Pillow中的Image類載入硬盤上的圖片。這個imagehash庫可以被用於構建哈希算法。
Argparse庫用於解析命令行參數,shelve庫用作一個存儲在硬盤上的簡單鍵值對數據庫(Python字典)。glob庫能很容易的獲取圖片路徑。
然後傳遞命令行參數。第一個,—dataset是輸入圖片庫的路徑。第二個,—shelve是shelve數據庫的輸出路徑。
下一步,打開shelve數據庫以寫數據。這個db數據庫存儲圖片哈希。更多的如下所示:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # loop over the image dataset for imagePath in glob.glob(args["dataset"] + "/*.jpg"): # load the image and compute the difference hash image = Image.open(imagePath) h = str(imagehash.dhash(image)) # extract the filename from the path and update the database # using the hash as the key and the filename append to the # list of values filename = imagePath[imagePath.rfind("/") + 1:] db[h] = db.get(h, []) + [filename] # close the shelf database db.close()以上就是大部分工作的內容了。開始循環從硬盤讀取圖片,創建圖片指紋並存入數據庫。
現在,來看看整個范例中最重要的兩行代碼:
?
1 2 filename = imagePath[imagePath.rfind("/") + 1:] db[h] = db.get(h, []) + [filename]正如本文早些時候提到的,有相同指紋的圖片被認為是一樣的。
因此,如果我們的目標是找到近似圖片,那就需要維護一個有相同指紋值的圖片列表。
而這也正是這幾行代碼做的事情。
前一個代碼段提取了圖片的文件名。而後一個代碼片段維護了一個有相同指紋值的圖片列表。
為了從我們的數據庫中提取圖片指紋並建立哈希數據庫,運行下列命令:
?
1 $ python index.py —dataset images —shelve db.shelve這個腳本會運行幾秒鐘,完成後,就會出現一個名為db.shelve的文件,包含了圖片指紋和文件名的鍵值對。
這個基本算法正是幾年前我為這家約會創業公司工作時使用的算法。我們獲得了一個不雅圖片集,為其中的每張圖片構建一個圖片指紋並將其存入數據庫。當來一張新圖片時,我只需簡單地計算它的哈希值,檢測數據庫查看是否上傳圖片已被標識為非法內容。
下一步中,我將展示實際如何執行查詢,判定數據庫中是否存在與所給圖片具有相同哈希值的圖片。
第二步:查詢數據集
既然已經建立了一個圖片指紋的數據庫,那麼現在就該搜索我們的數據集了。
打開一個新文件,命名為search.py,然後開始寫代碼:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # import the necessary packages from PIL import Image import imagehash import argparse import shelve # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-d", "--dataset", required = True, help = "path to dataset of images") ap.add_argument("-s", "--shelve", required = True, help = "output shelve database") ap.add_argument("-q", "--query", required = True, help = "path to the query image") args = vars(ap.parse_args())我們需要再一次導入相關的包。然後轉換命令行參數。需要三個選項,—dataset初始圖片集的路徑,—shelve,保存鍵值對的數據庫的路徑,—query,查詢/上傳圖片的路徑。我們的目標是對於每個查詢圖片,判定數據庫中是否已經存在。
現在,寫代碼執行實際的查詢:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # open the shelve database db = shelve.open(args["shelve"]) # load the query image, compute the difference image hash, and # and grab the images from the database that have the same hash # value query = Image.open(args["query"]) h = str(imagehash.dhash(query)) filenames = db[h] print "Found %d images" % (len(filenames)) # loop over the images for filename in filenames: image = Image.open(args["dataset"] + "/" + filename) image.show() # close the shelve database db.close()首先打開數據庫,然後載入硬盤上的圖片,計算圖片的指紋,找到具有相同指紋的所有圖片。
如果有圖片具有相同的哈希值,會遍歷這些圖片並展示在屏幕上。
這段代碼使我們僅僅使用指紋值就能判定圖片是否已在數據庫中存在。
結果
正如本文早些時候提到的,我從CALTECH-101數據集的7500多張圖片中隨機選取17張,然後通過任意縮放一部分點產生N張新的圖片。
這些圖片在尺寸上僅僅是少數像素不同—但也是因為這一點我們不能依賴於文件的md5哈希(這一點已在“優化算法”部分進行了詳盡的描述)。然而,我們可以使用圖片哈希找到近似圖片。
打開你的終端並執行下述命令:
?
1 $ python search.py —dataset images —shelve db.shelve —query images/84eba74d-38ae-4bf6-b8bd-79ffa1dad23a.jpg如果一切順利你就可以看到下述結果:
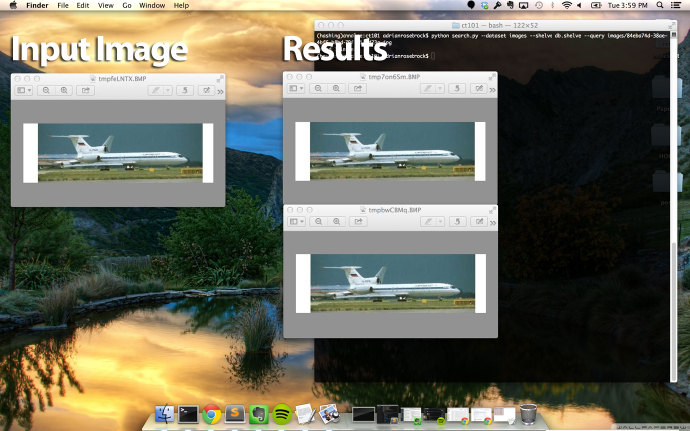
左邊是輸入圖片。載入這張圖片,計算它的圖片指紋,在數據庫中搜索指紋查看是否存在有相同指紋的圖片。
當然——正如右邊所示,我們的數據集中有其他兩張指紋相同的圖片。盡管從截圖中還不能十分明顯的看出,這些圖片,雖然有完全相同的視覺內容,也不是完全相同!這三張圖片的高度寬度各不相同。
嘗試一下另外一個輸入圖片:
?
1 $ python search.py —dataset images —shelve db.shelve —query images/9d355a22-3d59-465e-ad14-138a4e3880bc.jpg下面是結果:
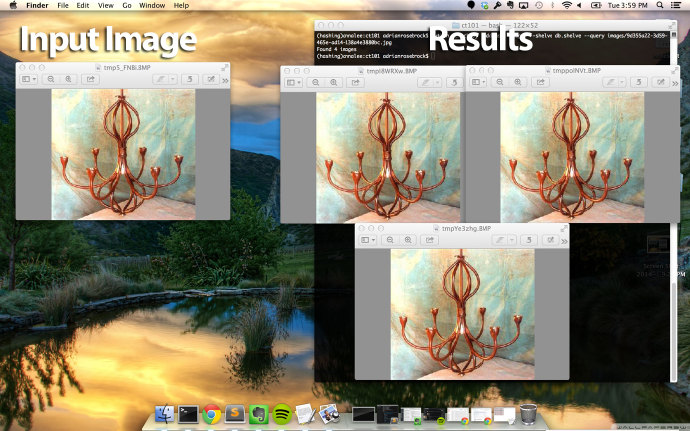
左邊仍然是我們的輸入圖片。正如右邊展示的,我們的圖片指紋算法能夠找出具有相同指紋的三張完全相同的圖片。
最後一個例子:
?
1 $ python search.py —dataset images —shelve db.shelve —query images/5134e0c2-34d3-40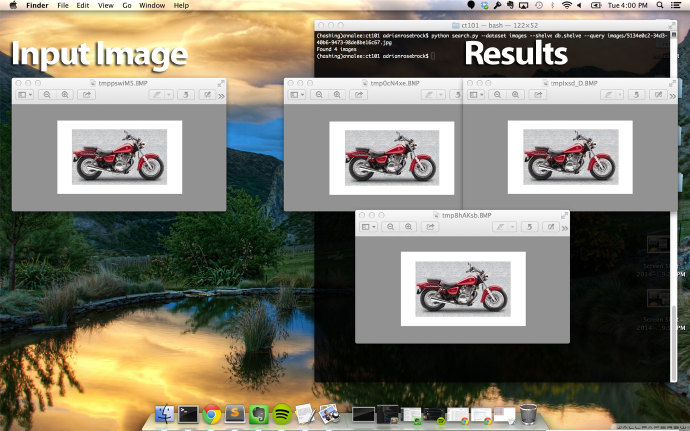
這一次左邊的輸入圖片是一個摩托車。拿到這張摩托車圖片,計算它的圖片指紋,然後在指紋數據庫中查找該指紋。正如我們在右邊看到的,我們也能判斷出數據庫中有三張圖片具有相同指紋。
優化算法
有很多可以優化本算法的方法——但最關鍵性的是要考慮到相似但不相同的哈希。
比如,本文中的圖片僅僅是一小部分點重組了(依比例增大或減小)。如果一張圖片以一個較大的因素調整大小,或者縱橫比被改變了,對應的哈希就會不同了。
然而,這些圖片應該仍然是相似的。
為了找到相似但不相同的圖片,我們需要計算漢明距離(Hamming distance).漢明距離被用於計算一個哈希中的不同位數。因此,哈希中只有一位不同的兩張圖片自然比有10位不同的圖片更相似。
然而,我們遇到了第二個問題——算法的可擴展性。
考慮一下:我們有一張輸入圖片,又被要求在數據庫中找到所有相似圖片。然後我們必須計算輸入圖片和數據庫中的每一張圖片之間的漢明距離。
隨著數據庫規模的增長,和數據庫比對的時間也隨著延長。最終,我們的哈希數據庫會達到一個線性比對已經不實際的規模。
解決辦法,雖然已超出本文范圍,就是利用K-d trees和VP trees將搜索問題的復雜度從線性減小到次線性。
總結
本文中我們學會了如何構建和使用圖片哈希來完成相似圖片的檢測。這些圖片哈希是使用圖片的視覺內容構建的。
正如一個指紋可以識別一個人,圖片哈希也能唯一的識別一張圖片。
使用圖片指紋的知識,我們建立了一個僅使用圖片哈希就能找到和識別具有相似內容的圖片的系統。
然後我們又演示了圖片哈希是如何應用於快速找到有相似內容的圖片。
從repo目錄下下載代碼。