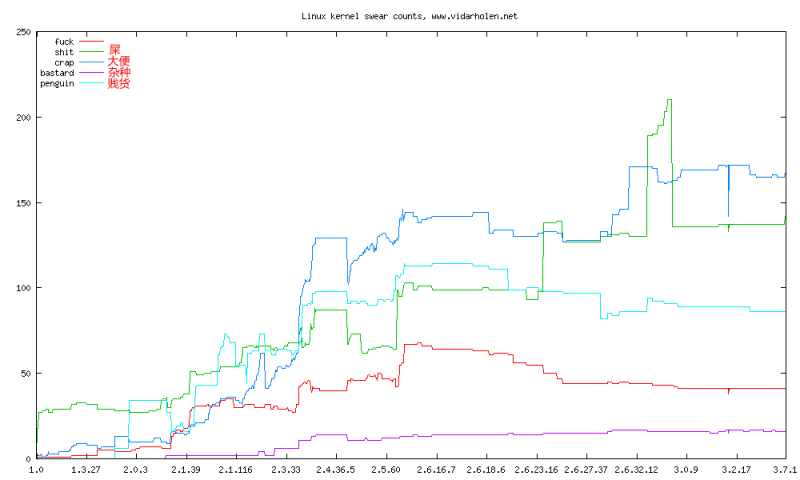
按髒話數/版本號統計
按髒話密度/版本號統計
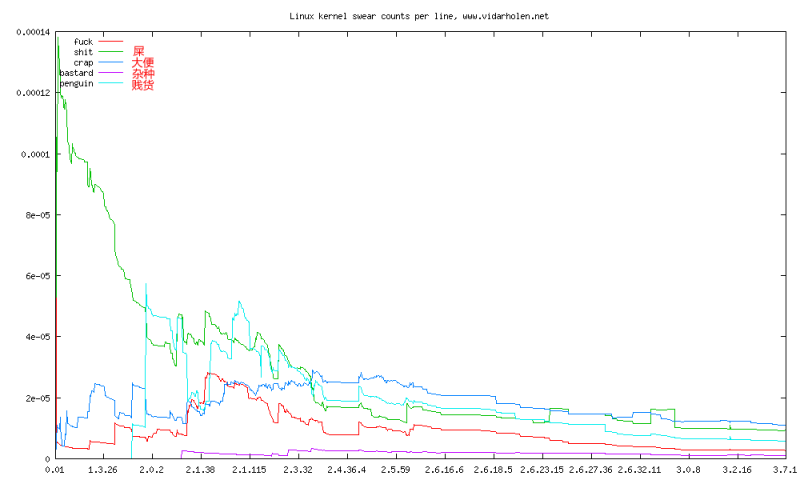
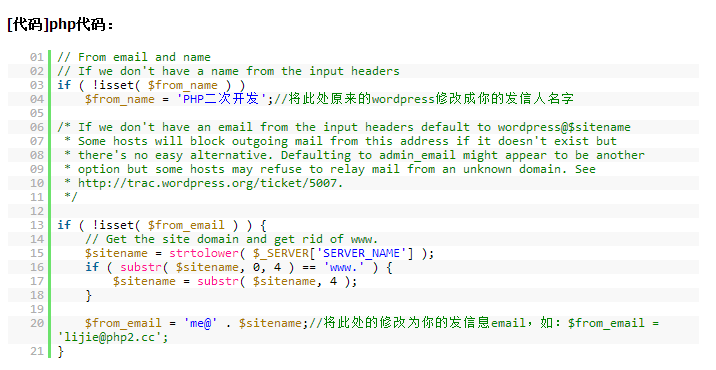
上圖顯示的是對Linux內核裡的c,h和S源代碼裡的髒話統計結果,我會每月更新一次這些數據,當有新版本發布時也會更新一次。我是受the linux kernel fuck count的啟發,但遺憾的是它裡面的數據已經過期了。
從圖中可以很明顯的看出,自從2.4版開始,髒話的數量有大量的增加。然而,總的代碼量也增加了很多,所以,總的來看,平均每行的詛咒密度是減少的。
介紹一下統計方法:不論任何地方出現的髒話詞匯都會計入總數——出現在另一個詞內也算。本來可以做的更合理些,但結果發現FreeBSD的正則表達式引擎有嚴重的內存洩漏問題,我也就沒有再改進了。一行裡對一個髒詞可能會統計出多次,因為有時候一個程序員會遇到非常非常懊惱的一天。
你可以在找到這個腳本,但它寫的實在是太亂了,不推薦。