GProf使用了一種異常簡單但是非常有效的方法來優化C++/C++程序,而且能很容易的識別出值得優化的代碼。一個簡單的案例分析將會顯示,GProf如何通過識別並優化兩個關鍵的數據結構,將實際應用中的程序從3分鐘的運行時優化到5秒的。
這個程序最早可以追溯到1982年關於編譯器構建的特別討論大會(the SIGPLAN Symposium on Compiler Construction)。現在這個程序成了各種UNIX平台上的一個標准工具。
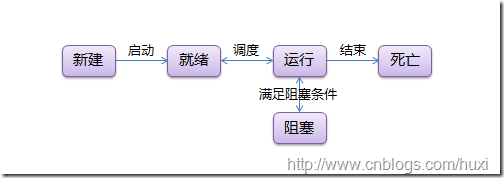
Profiling in a nutshell
程序概要分析的概念非常簡單:通過記錄各個函數的調用和結束時間,我們可以計算出程序的最大運行時的程序段。這種方法聽起來似乎要花費很多氣力——幸運的是,我們其實離真理並不遠!我們只需要在用gcc編譯時加上一個額外的參數('-pg'),運行這個(編譯好的)程序(來搜集程序概要分析的有關數據),然後運行'gprof'以更方便的分析這些結果。
案例分析:Pathalizer
我使用了一個現實中使用的程序來作為例子,是pathalizer的一部分:即event2dot,一個將路徑“事件”描述文件轉化為圖形化“dot” 文件的工具(executablewhichtranslatesapathalizer'events'filetoagraphviz'dot'file)。
簡單的說,它從一個文件裡面讀取各種事件,然後將它們分別保存為圖像(以頁為節點,且將頁與頁之間的轉變作為邊),然後將這些圖像整合為一張大的圖形,並保存為圖形化的'dot'格式文件。
給程序計時
先讓我們給我們未經優化的程序計一下時,看看它們的運行要多少時間。在我的計算機上使用event2dot並用源碼裡的例子作為輸入(大概55000的數據),大致要三分多鐘:
real3m36.316s
user0m55.590s
sys0m1.070s
程序分析
要使用gprof作概要分析,在編譯的時候要加上'-pg'選項,我們就是如下重新編譯源碼如下:
g++-pgdotgen.cppreadfile.cppmain.cppgraph.cppconfig.cpp-oevent2dot
現在我們可以再次運行event2dot,並使用我們前面使用的測試數據。這次我們運行的時候,event2dot運行的分析數據會被搜集並保存在'gmon.out'文件中,我們可以通過運行'gprofevent2dot|less'來查看結果。
gprof會顯示出如下的函數比較重要:
%cumulativeselfselftotal
timesecondssecondscallss/calls/callname
43.3246.0346.033399529890.000.00CompareNodes(Node*,Node*)
25.0672.6626.63550000.000.00getNode(char*,NodeListNode*&)
16.8090.5117.853394333740.000.00CompareEdges(Edge*,AnnotatedEdge*)
12.70104.0113.50519870.000.00addAnnotatedEdge(AnnotatedGraph*,Edge*)
1.98106.112.10519870.000.00addEdge(Graph*,Node*,Node*)
0.07106.180.0710.070.07FindTreshold(AnnotatedEdge*,int)
0.06106.240.0610.0628.79getGraphFromFile(char*,NodeListNode*&,Config*)
0.02106.260.0210.0277.40summarize(GraphListNode*,Config*)
0.00106.260.00550000.000.00FixName(char*)
可以看出,第一個函數比較重要:程序裡面絕大部分的運行時都被它給占據了。
優化
上面結果可以看出,這個程序大部分的時間都花在了CompareNodes函數上,用grep查看一下則發現CompareNodes只是被 CompareEdges調用了一次而已,而CompareEdges則只被addAnnotatedEdge調用——它們都出現在了上面的清單中。這兒就是我們應該做點優化的地方了吧!
我們注意到addAnnotatedEdge遍歷了一個鏈表。雖然鏈表是易於實現,但是卻實在不是最好的數據類型。我們決定將鏈表g->edges用二叉樹來代替:這將會使得查找更快。
結果
現在我們看一下優化後的運行結果:
real2m19.314s
user0m36.370s
sys0m0.940s
第二遍
再次運行gprof來分析:
%cumulativeselfselftotal
timesecondssecondscallss/calls/callname
87.0125.2525.25550000.000.00getNode(char*,NodeListNode*&)
10.6528.343.09519870.000.00addEdge(Graph*,Node*,Node*)
看起來以前占用大量運行時的函數現在已經不再是占用運行時的大頭了!我們試一下再優化一下呢:用節點哈希表來取代節點樹。
這次簡直是個巨大的進步:
real0m3.269s
user0m0.830s
sys0m0.090s
其他C/C++程序分析器
還有其他很多分析器可以使用gprof的數據,例如

KProf(截屏)和cgprof。雖然圖形界面的看起來更舒服,但我個人認為命令行的gprof使用更方便。
對其他語言的程序進行分析
我們這裡介紹了用gprof來對C/C++的程序進行分析,對其他語言其實一樣可以做到:對Perl,我們可以用Devel::DProf模塊。你的程序應該以perl-d:DProfmycode.pl來開始,並使用dprofpp來查看並分析結果。如果你可以用gcj來編譯你的Java程序,你也可以使用gprof,然而目前還只支持單線程的Java代碼。
結論
就像我們已經看到的,我們可以使用程序概要分析快速的找到一個程序裡面值得優化的地方。在值得優化的地方優化,我們可以將一個程序的運行時從3分36秒減少到少於5秒,就像從上面的例子看到的一樣。