本系列拖了蠻久了,主要是因為LZ寫的時候其實剛看到第二章,因此這一段時間快速看了下第三章,並花了點時間沉澱了一下,這才耽誤了下來。
本文是3.X系列的第一篇,也是匯編世界的開篇。LZ一直在想如何能讓這一系列稍微變得有趣一些,因為第二章實在是太枯燥了,連LZ都覺得無聊至極,不過LZ竟然鬼使神差的把課後題做了不少。匯編這一部分相對而言會好很多,盡管它依然不是我們熟悉的編程語言,但是終歸還是語言,而不再是我們幾乎不打交道的0和1。
對於大部分猿友來說,平時寫的都是一些高級程序設計語言,是計算機領域的諸多大神,經過幾層的封裝才讓我們享有了這樣的待遇。這樣一來,我們在平時的開發過程中,可以省去很多底層的麻煩。試想一下,倘若在你寫一個方法的時候,你還需要去操心哪些變量需要放在寄存器,哪些變量放在主存,放在寄存器的話又該放在哪一個裡面,放在主存的話又該放在那個內存區域等等這一類底層的問題,以及還要去記各種各樣的寄存器名稱和它們的作用等等諸如此類的事,你是否會崩潰呢。
因此這不難看出,高級語言給我們帶來了很多便捷,但是事情總不是十全十美的,這樣所帶來的便捷也同時引來了一些問題。這是因為我們看到的代碼,在實際執行它們的時候,可能已經面目全非了,所以很多時候會造成一些莫名其妙的問題發生。
舉一個小例子,LZ曾經在群裡問過類似的問題,這次LZ寫一個小程序,各位學過Java的猿友來看看這個程序的結果。
public class Main
{
public static void main(String[] args)
{
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b);
System.out.println(c == d);
}
}
相信有不少人看不出來這個程序的問題在哪,覺得應該輸出兩個true就對了。可是這個程序的結果卻是一個true和一個false,如果哪位猿友不信的話可以自己試一下。至於原因是什麼,各位有興趣的可以去研究下Java的自動拆裝箱,另外再看一下Integer對象的valueOf方法緩存的范圍,答案就會自動揭曉。
產生這個問題的根本原因,其實還是因為編譯器給開發者蒙上了一層迷霧,導致一些開發人員只知其然,而不知其所以然,他們根本不清楚自己寫出來的程序,實際上到底是如何運行的。這樣的一層迷霧注定會降低開發者的水平,所以為了提高自己,我們有必要揭開這層迷霧。對於C/C++的開發者來講,揭開這層迷霧其實就是了解匯編語言的過程。
匯編語言對於C/C++程序猿來講,就像class文件對於Java程序猿是一樣的,因為它們都是編譯器處理後的產物,我們可以從下圖當中簡單的了解一下兩者的關聯。
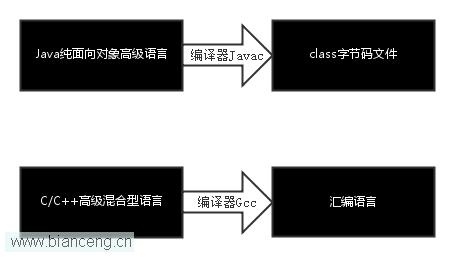
這個圖中應該看起來還算比較清晰,其實LZ說了這麼多,只是想說一件事,那就是了解匯編語言的知識,對我們平時的開發有著不可忽視的好處,尤其是對於從事C/C++的開發者來說,好處更是無窮無盡的。
可能會有猿友覺得,LZ是一個靠Java吃飯的家伙,了解匯編語言是不是有點多此一舉了,畢竟Java語言離匯編還是有點太遠了吧。畢竟Java要先編譯成class文件,然後交給虛擬機的執行引擎,而虛擬機的執行引擎則是由C/C++來實現的,C/C++又需要經過預處理和GCC編譯器的編譯才能最終成為匯編語言。這猛地一看,Java確實離匯編語言太遠了。
可是LZ想說的是,無論你處於什麼樣的一個崗位當中,只要你做的事是指揮計算機幫助你完成一些事情,那麼你就必須了解計算機如何幫你完成這些事情,否則你就只會指揮,而不會懂得如何去做。不知道如何去做的後果就是,你不會知道如何才能做的更好,反映到現實當中,就是你不知道如何寫出更好的程序。這點其實不難理解,試想一下,你都不知道你的程序實際上是如何運行的,你又怎麼可能知道怎麼寫是更好的呢。
查看本欄目
在編譯一段C語言程序的過程中,其實做了很多步驟,比如預編譯處理、編譯處理、匯編處理以及鏈接處理。我們要了解的匯編語言,就是在編譯處理後的產物。因此我們可以在GCC的編譯器當中加入一些參數來控制它只生成匯編語言,而不進行匯編處理和鏈接處理。
我們看下面這一段簡單的C語言代碼,假設為sum.c。
int simple(int *xp,int y){
int t = *xp+y;
*xp=t;
return t;
}
我們使用GCC編譯器加-S參數來編譯這段代碼,最終我們可以得到一個sum.s的文件,我們使用cat來查看一下這個文件。
.file "sum.c"
.text
.globl simple
.type simple, @function
simple:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl 8(%ebp), %eax//這一步是從主存取變量xp
movl (%eax), %eax//取*xp的值
addl 12(%ebp), %eax//計算*xp+y,並存到%eax寄存器
movl %eax, -4(%ebp)//將*xp+y賦給變量t
movl 8(%ebp), %eax//再取xp
movl -4(%ebp), %edx//取t
movl %edx, (%eax)//執行t->*xp
movl -4(%ebp), %eax//將t放入%eax准備返回
leave
ret
.size simple, .-simple
.ident "GCC: (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3"
.section .note.GNU-stack,"",@progbits
這裡我們主要看一下匯編語言是如何描述我們的計算過程的,因此LZ只是簡單的加了幾個注釋,來大致描述下上面的程序的計算過程。其中需要說明的是,以%開頭的為寄存器,有小括號的為主存。
熟悉GCC的猿友們應該知道,我們可以控制編譯器的優化級別,因此我們使用另外一種方式來編譯一下sum.c,我們在-S的基礎上再加一個-O1的參數。之後使用cat打開sum.s文件。
.file "sum.c"
.text
.globl simple
.type simple, @function
simple:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %edx//取xp
movl 12(%ebp), %eax//取y
addl (%edx), %eax//計算*xp+y並存到%eax寄存器,准備返回
movl %eax, (%edx)//將*xp+y存入*xp
popl %ebp
ret
.size simple, .-simple
.ident "GCC: (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3"
.section .note.GNU-stack,"",@progbits
可以很明顯的看出,匯編指令的數目急劇減少,這裡LZ也加入了簡單的注釋。從LZ簡單的注釋中可以看出,這裡的優化主要是去掉了變量t的存在,因此減少了指令數。
如果哪位猿友實在看不明白這兩段匯編語言的含義,可以暫且忽略,這裡LZ只是讓各位體驗一下匯編語言的格式,以及親自接觸一下匯編語言,我們的目的並不是搞清楚它的意義。相信經過3.X的系列講解,各位猿友再回來看這兩段匯編代碼時,應該會很輕松的看出其中的意義。
文章小結
這一章拖的時間有點久,主要是因為LZ作為一個Java開發人員來講,對匯編語言的學習有些許難度,畢竟LZ並不擅長C/C++。還有一個原因,則是由於LZ希望盡量的搞清楚來龍去脈,以免誤導某些猿友。
當然了,就算如此,LZ也不敢保證現在對3.X的內容已經了如指掌,因此如果文中有任何與各位猿友的理解不一致的地方,希望各位猿友盡管提出。不僅可以避免誤導看博文的猿友,還可以幫助LZ糾正錯誤的認識。
好了,本文的主要目的就是將各位猿友拉近匯編的世界,因此就只是簡單的介紹了一下。接下來,我們將深入的討論寄存器、數據格式以及一些匯編指令。
作者:zuoxiaolong(左潇龍)
出處:博客園左潇龍的技術博客--http://www.cnblogs.com/zuoxiaolong