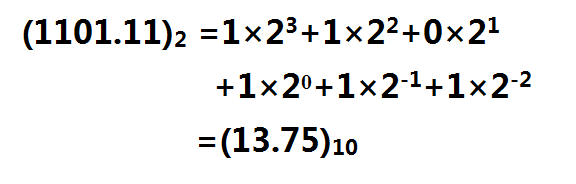上一章(1.1-1.4)LZ和各位簡單的探討了一下計算機系統中的一些基本概念,本次我們將進入一個嶄新的世界。在1.1那一章當中,我們已經簡單的提及了信息的概念,本次我們會逐漸深入的討論信息的相關內容。
我們很難想象,1和0這兩個再簡單不過的數字,給計算機科學帶來了徹底的改變。對於無法與人腦相比的計算機來說,簡單的1和0就是最適合它們的數字。不過1個1或者1個0往往代表不了任何意義,它們必須被賦予上下文,才能有具體的含義。比如,如果我們知道1和0是代表的布爾類型的值,那麼我們就知道1是true,0是false。
對於二進制所表示的數字來說,主要有三種,即無符號、補碼以及浮點數。
由於計算機對於固定類型的二進制數字往往都是有位數限制的,比如int類型使用四個字節(32位二進制)來表示,因此在計算的時候,會發生溢出的情況,最簡單的我們使用無符號整數0xFFFFFFFF與無符號整數0xFFFFFFFF相乘,則會產生溢出。
在產生溢出的時候,得出的結果往往會令人大跌眼鏡。比如兩個正數相乘可能得到負值,兩個正數相加也可能得到負值。而對於不同的計算機來說,由於數值范圍可能有所不同,因此掌握信息相關的內容對於寫出跨平台的程序來講也是很有幫助的。
大多數計算機使用8位的塊,或者說字節,來作為最小的可尋址的存儲器單位,而不是在存儲器中訪問單獨的位。換句話說,我們在訪問存儲器的內容時,最小的訪問單位一般是字節。
在我們編程的時候,往往會把虛擬存儲器(virtual memory)抽象為一個字節數組,而每一個數組內的元素或者說字節都有唯一的地址(address),這些地址的集合就被稱作虛擬地址空間。虛擬地址空間是為了給機器級的程序一個概念上的映像,實際上為了提供這個映像,內部的實現是非常復雜的。
對於機器來說,可能比較喜歡0和1,但是對於人類這種高級生物來說,1和0就有點不夠看了。因此通常情況下,為了便於閱讀,我們會使用十六進制去表示二進制。1位十六進制的數字可以表示4位二進制數字,因此一個字節就可以表示為0x00---0xFF。
有關十六進制、二進制以及十進制的轉換,LZ這裡就直接略過了,相信大部分人應該都對這個轉換並不陌生。
字
每台計算機都有一個字長(word size),用於指明整數和指針數據的標准大小(nominal size)。而由於虛擬地址空間中的地址就是使用一個字來表示的,因此操作系統中的字長就決定了虛擬地址空間的大小。
比如32位操作系統下,最大內存就是232 = 4 * 210 * 210 * 210 B = 4GB,而在64位操作系統下,LZ還專門問了問群裡的猿友,最終得到的結果是234GB。
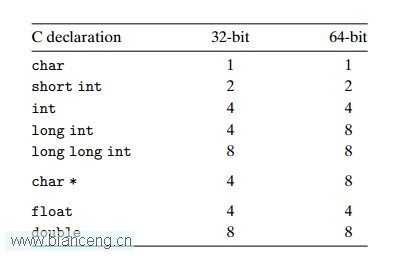
由於計算機位數的不同,會造成在數據類型的存儲上,采用的位數略有不同,下表是在32位和64位機器下,C語言當中的數字數據類型需要的位數。
查看本欄目
對於一個特定的數據類型來講,計算機在解釋這類數據的值的時候,是根據起始位置以及數據類型的位數來確定的。比如對於無符號int類型的數據來說,倘若我們知道它的起始位置為0x1,而當前的操作系統采取的是大端法規則,假設0x1-0x4的內存地址中存儲的字節依次為0xFF,0xFF,0xFF,0xFF,由此計算機將會幫我們計算出這個無符號int類型的值為232-1,也就是無符號int類型的最大值。
這其中計算機是根據0x1-0x4這四個字節上的值,以及無符號int類型的解釋方式,最終得到的這個無符號int類型的值。
由此可見,計算機在解釋一個數據類型的值時主要有四個因素:位排列規則(大端或者小端)、起始位置、數據類型的字節數、數據類型的解釋方式。
對於特定的系統來說,前兩種因素都是特定的,而對於後兩種因素的改變,則可以改變一個數據類型的值的最終計算結果,這就是強制類型轉換。對於大部分高級程序設計語言來講,都提供了強制類型轉換。
比如C語言,我們可以將一個無符號int類型的值強制轉換為其它類型,在轉換之後,對於上面四個因素之中,改變的是最後兩個。為此我們寫一個小程序來看下這個有意思的事情。
#include <stdio.h>
int main(){
unsigned int x = 0xFFFFFF61;
int *p = &x;
char *cp = (char *)p;
printf("%c\n",*cp);
}
這是一個簡單的強制類型轉換示例,可以看到我們將一個無符號int類型的值,先賦給了一個int類型的指針,又強制轉換成了char類型的指針,最終我們輸出這個char類型指針所代表的字符,結果的輸出是一個a。
![]()
輸出a的原因就是由上面的四個因素決定的,我們看這個具體程序上的四個因素。
1、cp指針的值與x變量的起始內存地址相等。(起始位置)
2、LZ的linux系統是小端表示法,也就是說假設x變量的起始內存地址為0x1,那麼0x1-0x4的值分別為0x61、0xFF、0xFF、0xFF。(位排列規則)
3、char只占一個字節,因此會只讀取0x61這個值。(數據類型的字節數,或者說大小)
4、0x61為十進制的97,對應ascii表的話,代表的是字符a,因此最終輸出了a。(數據類型的解釋方式)
可以看出,強制類型轉換有時候會讓結果變的讓人難以預料,因此這種技巧一般不太推薦使用,但是這種手段也確實是程序設計語言所必需的。
這一點其實上面我們已經提到了,我們知道97其實代表的是字符'a',而這個的由來就是根據ascii表來的,我們在linux系統上可以輸入man ascii命令來查看。
二進制如何表示代碼?
其實這些都是編譯器的責任了,我們只需要寫出像上面那個小程序一樣的人們可以看懂的代碼,編譯器便會幫我們將其翻譯成對應的機器所認識的二進制序列。從這個角度上來講,程序語言其實就是一個二進制序列的簡單描述,它提供我們更簡單的編寫計算機可以執行的二進制序列的方式。
本次我們初步探索了信息的存儲以及信息所代表的結果的計算,這些內容都比較基礎,相信不難看懂。
作者:zuoxiaolong(左潇龍)
出處:博客園左潇龍的技術博客--http://www.cnblogs.com/zuoxiaolong