5.0 編譯優化概述
優化是一件非常重要的事情。作為一個程序設計者,你肯定希望自己的程序既小又快。DOS時代的許多書中都提到,“某某編譯器能夠生成非常緊湊的代碼”,換言之,編譯器會為你把代碼盡可能地縮減,如果你能夠正確地使用它提供的功能的話。目前,Intel x86體系上流行的C/C++編譯器,包括Intel C/C++ Compiler, GNU C/C++ Compiler,以及最新的Microsoft和Borland編譯器,都能夠提供非常緊湊的代碼。正確地使用這些編譯器,則可以得到性能足夠好的代碼。
但是,機器目前還不能像人那樣做富於創造性的事情。因而,有些時候我們可能會不得不手工來做一些事情。
使用匯編語言優化代碼是一件困難,而且技巧性很強的工作。很多編譯器能夠生成為處理器進行過特殊優化處理的代碼,一旦進行修改,這些特殊優化可能就會被破壞而失效。因此,在你決定使用自己的匯編代碼之前,一定要測試一下,到底是編譯器生成的那段代碼更好,還是你的更好。
本章中將討論一些編譯器在某些時候會做的事情(從某種意義上說,本章內容更像是計算機專業的基礎課中《編譯程序設計原理》、《計算機組成原理》、《計算機體系結構》課程中的相關內容)。本章的許多內容和匯編語言程序設計本身關系並不是很緊密,它們多數是在為使用匯編語言進行優化做准備。編譯器確實做這些優化,但它並不總是這麼做;此外,就編譯器的設計本質來說,它確實沒有義務這麼做——編譯器做的是等義變換,而不是等效變換。考慮下面的代碼:
// 程序段1for(i=0; i<100; i++) j+=i;
return j;
}
好的,首先,絕大多數編譯器恐怕不會自作主張地把它“篡改”為
// 程序段1(改進1)for(i=1; i<100; i++) j+=i;
return j;
}
多數(但確實不是全部)編譯器也不會把它改為
// 程序段1(改進2)
inline int gaussianSum(){
return 5050;
}
這兩個修改版本都不同於原先程序的語義。首先我們看到,讓i從0開始是沒有必要的,因為j+=i時,i=0不會做任何有用的事情;然後是,實際上沒有必要每一次都計算1+...+100的和——它可以被預先計算,並在需要的時候返回。
這個例子也許並不恰當(估計沒人會寫出最初版本那樣的代碼),但這種實踐在程序設計中確實可能出現。我們把改進2稱為編譯時表達式預先計算,而把改進1成為循環強度削減。
然而,一些新的編譯器的確會進行這兩種優化。不過別慌,看看下面的代碼:
// 程序段2if((k<0) || (k>=10)) return -1;
if((k<=1)) return 1
for(i=1; i<k; i++) j*=i;
return j;
}
程序采用的是一個時間復雜度為O(n)的算法,不過,我們可以把他輕易地改為O(1)的算法:
// 程序段2 (非規范改進)static const int FractorialTable[]={1, 1, 2, 6, 24,
120, 720, 5040, 40320, 362880, 3628800};
if((k<0) || (k>=10)) return -1;
return FractorialTable[k];
}
這是一個典型的以空間換時間的做法。通用的編譯器不會這麼做——因為它沒有辦法在編譯時確定你是不是要這麼改。可以說,如果編譯器真的這樣做的話,那將是一件可怕的事情,因為那時候你將很難知道編譯器生成的代碼和自己想的到底有多大的差距。
當然,這類優化超出了本文的范圍——基本上,我把它們歸入“算法優化”,而不是“程序優化”一類。類似的優化過程需要程序設計人員對於程序邏輯非常深入地了解和全盤的掌握,同時,也需要有豐富的算法知識。
自然,如果你希望自己的程序性能有大幅度的提升,那麼首先應該做的是算法優化。例如,把一個O(n2)的算法替換為一個O(n)的算法,則程序的性能提升將遠遠超過對於個別語句的修改。此外,一個已經改寫為匯編語言的程序,如果要再在算法上作大幅度的修改,其工作量將和重寫相當。因此,在決定使用匯編語言進行優化之前,必須首先考慮算法優化。但假如已經是最優的算法,程序運行速度還是不夠快怎麼辦呢?
好的,現在,假定你已經使用了已知最好的算法,決定把它交給編譯器,讓我們來看看編譯器會為我們做什麼,以及我們是否有機會插手此事,做得更好。
5.1 循環優化:強度削減和代碼外提
比較新的編譯器在編譯時會自動把下面的代碼:
for(i=0; i<10; i++){至少變換為
for(i=0; i<10; i++);甚至
j=i=10; k=20;當然,真正的編譯器實際上是在中間代碼層次作這件事情。
原理 如果數據項的某個中間值(程序執行過程中的計算結果)在使用之前被另一中間值覆蓋,則相關計算不必進行。
也許有人會問,編譯器不是都給咱們做了嗎,管它做什麼?注意,這裡說的只是編譯系統中優化部分的基本設計。不僅在從源代碼到中間代碼的過程中存在優化問題,而且編譯器生成的最終的機器語言(匯編)代碼同樣存在類似的問題。目前,幾乎所有的編譯器在最終生成代碼的過程中都有或多或少的瑕疵,這些瑕疵目前只能依靠手工修改代碼來解決。
5.2 局部優化:表達式預計算和子表達式提取
表達式預先計算非常簡單,就是在編譯時盡可能地計算程序中需要計算的東西。例如,你可以毫不猶豫地寫出下面的代碼:
const unsigned long nGiga = 1024L * 1024L * 1024L;而不必擔心程序每次執行這個語句時作兩遍乘法,因為編譯器會自動地把它改為
const unsigned long nGiga = 1073741824L;而不是傻乎乎地讓計算機在執行到這個初始化賦值語句的時候才計算。當然,如果你願意在上面的代碼中摻上一些變量的話,編譯器同樣會把常數部分先行計算,並拿到結果。
表達式預計算並不會讓程序性能有飛躍性的提升,但確實減少了運行時的計算強度。除此之外,絕大多數編譯器會把下面的代碼:
// [假設此時b, c, d, e, f, g, h都有一個確定的非零整數值,並且,a[0] = b*c;
a[1] = b+c;
a[2] = d*e;
a[3] = b*d + c*d;
a[4] = b*d*e + c*d*e;
優化為(再次強調,編譯器實際上是在中間代碼的層次,而不是源代碼層次做這件事情!):
// [假設此時b, c, d, e, f, g, h都有一個確定的非零整數值,並且,a[0] = b*c;
a[1] = b+c;
a[2] = d*e;
a[3] = a[1] * d;
a[4] = a[3] * e;
更進一步,在實際代碼生成過程中,一些編譯器還會對上述語句的次序進行調整,以使其運行效率更高。例如,將語句調整為下面的次序:
// [假設此時b, c, d, e, f, g, h都有一個確定的非零整數值,並且,a[0] = b*c;
a[1] = b+c;
a[3] = a[1] * d;
a[4] = a[3] * e;
a[2] = d*e;
在某些體系結構中,剛剛計算完的a[1]可以放到寄存器中,以提高實際的計算性能。上述5個計算任務之間,只有1, 3, 4三個計算任務必須串行地執行,因此,在新的處理器上,這樣做甚至能夠提高程序的並行度,從而使程序效率變得更高。
5.3 全局寄存器優化
[待修訂內容] 本章中,從這一節開始的所有優化都是在微觀層面上的優化了。換言之,這些優化是不能使用高級語言中的對應設施進行解釋的。這一部分內容將進行較大規模的修訂。
通常,此類優化是由編譯器自動完成的。我個人並不推薦真的由人來完成這些工作——這些工作多半是枯燥而重復性的,編譯器通常會比人做得更好(沒說的,肯定也更快)。但話說回來,使用匯編語言的程序設計人員有責任了解這些內容,因為只有這樣才能更好地駕馭處理器。
在前面的幾章中我已經提到過,寄存器的速度要比內存快。因此,在使用寄存器方面,編譯器一般會做一種稱為全局寄存器優化的優化。
例如,在我們的程序中使用了4個變量:i, j, k, l。它們都作為循環變量使用:
for(i=0; i<1000; i++){這段程序的優化就不那麼簡單了。顯然,按照通常的壓棧方法,i, j, k, l應該按照某個順序被壓進堆棧,然後調用do_something(),然後函數做了一些事情之後返回。問題在於,無論如何壓棧,這些東西大概都得進內存(不可否認某些機器可以用CPU的Cache做這件事情,但Cache是寫通式的和回寫式的又會造成一些性能上的差異)。
聰明的讀者馬上就會指出,我們不是可以在定義do_something()的時候加上inline修飾符,讓它在本地展開嗎?沒錯,本地展開以增加代碼量為代價換取性能,但這只是問題的一半。編譯器盡管完成了本地展開,但它仍然需要做許多額外的工作。因為寄存器只有那麼有限的幾個,而我們卻有這麼多的循環變量。
把四個變量按照它們在循環中使用的頻率排序,並決定在do_something()塊中的優先順序(放入寄存器中的優先順序)是一個解決方案。很明顯,我們可以按照l, k, j, i的順序(從高到低,因為l將被進行1000*1000*1000*1000次運算!)來排列,但在實際的問題中,事情往往沒有這麼簡單,因為你不知道do_something()中做的到底是什麼。而且,憑什麼就以for(l=0; l<1000; l++)作為優化的分界點呢?如果do_something()中還有循環怎麼辦?
如此復雜的計算問題交給計算機來做通常會有比較滿意的結果。一般說來,編譯器能夠對程序中變量的使用進行更全面地估計,因此,它分配寄存器的結果有時雖然讓人費解,但卻是最優的(因為計算機能夠進行大量的重復計算,並找到最好的方法;而人做這件事相對來講比較困難)。
編譯器在許多時候能夠作出相當讓人滿意的結果。考慮以下的代碼:
int a=0;for(int i=1; i<10; i++)
for(int j=1; j<100; j++){
a += (i*j);
}
讓我們把它變為某種形式的中間代碼:
00: 0 -> a程序中執行強度最大的無疑是03到05這一段,涉及的需要寫入的變量包括a, j;需要讀出的變量是i。不過,最終的編譯結果大大出乎我們的意料。下面是某種優化模式下Visual C++ 6.0編譯器生成的代碼(我做了一些修改):
xor eax, eax ; a=0(eax: a)這段代碼可能有些令人費解。主要是因為它不僅使用了大量寄存器,而且還包括了5.2節中曾提到的子表達式提取技術。表面上看,多引入的那個變量(t)增加了計算時間,但要注意,這個t不僅不會降低程序的執行效率,相反還會讓它變得更快!因為同樣得到了計算結果(本質上,i*j即是第j次累加i的值),但這個結果不僅用到了上次運算的結果,而且還省去了乘法(很顯然計算機計算加法要比計算乘法快)。
這裡可能會有人問,為什麼要從999循環到0,而不是按照程序中寫的那樣從0循環到999呢?這個問題和匯編語言中的取址有關。在下兩節中我將提到這方面的內容。
5.4 x86體系結構上的並行最大化和指令封包
考慮這樣的問題,我和兩個同伴現在在山裡,遠處有一口井,我們帶著一口鍋,身邊是樹林;身上的飲用水已經喝光了,此處允許砍柴和使用明火(當然我們不想引起火災:),需要燒一鍋水,應該怎麼樣呢?
一種方案是,三個人一起搭灶,一起砍柴,一起打水,一起把水燒開。
另一種方案是,一個人搭灶,此時另一個人去砍柴,第三個人打水,然後把水燒開。
這兩種方案畫出圖來是這樣:
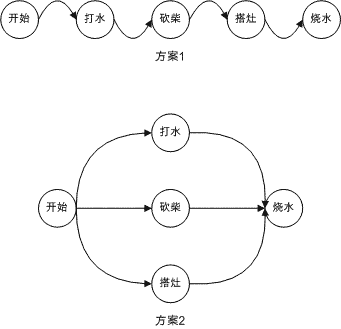
僅僅這樣很難說明兩個方案孰優孰劣,因為我們並不明確三個人一起打水、一起砍柴、一起搭灶的效率更高,還是分別作效率更高(通常的想法,一起做也許效率會更高)。但假如說,三個人一個只會搭灶,一個只會砍柴,一個只會打水(當然是說這三件事情),那麼,方案2的效率就會搞一些了。
在現實生活中,某個人擁有專長是比較普遍的情況;在設計計算機硬件的時候則更是如此。你不可能指望加法器不做任何改動就能去做移位甚至整數乘法,然而我們注意到,串行執行的程序不可能在同一時刻同時用到處理器的所有功能,因此,我們(很自然地)會希望有一些指令並行地執行,以充分利用CPU的計算資源。
CPU執行一條指令的過程基本上可以分為下面幾個階段:取指令、取數據、計算、保存數據。假設這4個階段各需要1個時鐘周期,那麼,只要資源夠用,並且4條指令之間不存在串行關系(換言之這些指令的執行先後次序不影響最終結果,或者,更嚴格地說,沒有任何一條指令依賴其他指令的運算結果)指令也可以像下面這樣執行:
指令1 取指令 取數據 計 算 存數據 指令2 取指令 取數據 計 算 存數據 指令3 取指令 取數據 計 算 存數據 指令4 取指令 取數據 計 算 存數據這樣,原本需要16個時鐘周期才能夠完成的任務就可以在7個時鐘周期內完成,時間縮短了一半還多。如果考慮灰色的那些方格(這些方格可以被4條指令以外的其他指令使用,只要沒有串行關系或沖突),那麼,如此執行對於性能的提升將是相當可觀的(此時,CPU的所有部件都得到了充分利用)。
當然,作為程序來說,真正做到這樣是相當理想化的情況。實際的程序中很難做到徹底的並行化。假設CPU能夠支持4條指令同時執行,並且,每條指令都是等周期長度的4周期指令,那麼,程序需要保證同一時刻先後發射的4條指令都能夠並行執行,相互之間沒有關聯,這通常是不太可能的。
最新的Intel Pentium 4-XEON處理器,以及Intel Northwood Pentium 4都提供了一種被稱為超線程(Hyper-Threading TM)的技術。該技術通過在一個處理器中封裝兩組執行機構來提高指令並行度,並依靠操作系統的調度來進一步提升系統的整體效率。
由於線程機制是與操作系統密切相關的,因此,在本文的這一部分中不可能做更為深入地探討。在後續的章節中,我將介紹Win32、FreeBSD 5.x以及Linux中提供的內核級線程機制(這三種操作系統都支持SMP及超線程技術,並且以線程作為調度單位)在匯編語言中的使用方法。
關於線程的討論就此打住,因為它更多地依賴於操作系統,並且,無論如何,操作系統的線程調度需要更大的開銷並且,到目前為止,真正使用支持超線程的CPU,並且使用相應操作系統的人是非常少的。因此,我們需要關心的實際上還是同一執行序列中的並發執行和指令封包。不過,令人遺憾的是,實際上在這方面編譯器做的幾乎是肯定要比人好,因此,你需要做的只是開啟相應的優化;如果你的編譯器不支持這樣的特性,那麼就把它扔掉……據我所知,目前在Intel平台上指令封包方面做的最好的是Intel的C++編譯器,經過Intel編譯器編譯的代碼的性能令人驚異地高,甚至在AMD公司推出的兼容處理器上也是如此。
5.5 存儲優化
從前一節的圖中我們不難看出,方案2中,如果誰的動作慢,那麼他就會成為性能的瓶頸。實際上,CPU也不會像我描述的那樣四平八穩地運行,指令執行的不同階段需要的時間(時鐘周期數)是不同的,因此,縮短關鍵步驟(即,造成瓶頸的那個步驟)是縮短執行時間的關鍵。
至少對於使用Intel系列的CPU來說,取數據這個步驟需要消耗比較多的時間。此外,假如數據跨越了某種邊界(如4或8字節,與CPU的字長有關),則CPU需要啟動兩次甚至更多次數的讀內存操作,這無疑對性能構成不利影響。
基於這樣的原因,我們可以得到下面的設計策略:
程序設計中的內存數據訪問策略
盡可能減少對於內存的訪問。在不違背這一原則的前提下,如果可能,將數據一次處理完。 盡可能將數據按4或8字節對齊,以利於CPU存取 盡可能一段時間內訪問范圍不大的一段內存,而不同時訪問大量遠距離的分散數據,以利於Cache緩存*第一條規則比較簡單。例如,需要求一組數據中的最大值、最小值、平均數,那麼,最好是在一次循環中做完。
“於是,這家伙又攢了一段代碼”……
int a[]={1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6,7,8,9,0};avg=max=min=a[0];
for(i=1; i<(sizeof(a)/sizeof(int)); i++){
avg+=a[i];
if(max < a[i])
max = a[i];
else if(min > a[i])
min = a[i];
}
avg /= i;
Visual C++編譯器把最開始一段賦值語句翻譯成了一段簡直可以說是匪夷所思的代碼:
; int a[]={1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6,7,8,9,0};
mov edi, 2 ; 此時edi沒有意義
mov esi, 3 ; esi也是!臨時變量而已。
mov DWORD PTR _a$[esp+92], edi
mov edx, 5 ; 黑名單加上edx
mov eax, 7 ; eax也別跑:)
mov DWORD PTR _a$[esp+132], edi
mov ecx, 9 ; 就差你了,ecx
; int i;
; int avg, max, min;
; avg=max=min=a[0];
mov edi, 1 ; edi搖身一變,現在它是min了。
mov DWORD PTR _a$[esp+96], esi
mov DWORD PTR _a$[esp+104], edx
mov DWORD PTR _a$[esp+112], eax
mov DWORD PTR _a$[esp+136], esi
mov DWORD PTR _a$[esp+144], edx
mov DWORD PTR _a$[esp+152], eax
mov DWORD PTR _a$[esp+88], 1 ; 編譯器失誤? 此處edi應更好
mov DWORD PTR _a$[esp+100], 4
mov DWORD PTR _a$[esp+108], 6
mov DWORD PTR _a$[esp+116], 8
mov DWORD PTR _a$[esp+120], ecx
mov DWORD PTR _a$[esp+124], 0
mov DWORD PTR _a$[esp+128], 1
mov DWORD PTR _a$[esp+140], 4
mov DWORD PTR _a$[esp+148], 6
mov DWORD PTR _a$[esp+156], 8
mov DWORD PTR _a$[esp+160], ecx
mov DWORD PTR _a$[esp+164], 0
mov edx, edi ; edx是max。
mov eax, edi ; 期待已久的avg, 它被指定為eax
這段代碼是最優的嗎?我個人認為不是。因為編譯器完全可以在編譯過程中直接把它們作為常量數據放入內存。此外,如果預先對a[0..9]10個元素賦值,並利用串操作指令(rep movsdw),速度會更快一些。
當然,犯不上因為這些問題責怪編譯器。要求編譯器知道a[0..9]和[10..19]的內容一樣未免過於苛刻。我們看看下面的指令段:
; for(i=1; ...上面的程序倒是沒有什麼驚人之處。唯一一個比較嚇人的東西是那個jmp SHORT指令,它是否有用取決於具體的問題。C/C++編譯器有時會產生這樣的代碼,我過去曾經錯誤地把所有的此類指令當作沒用的代碼而刪掉,後來發現程序執行時間沒有明顯的變化。通過查閱文檔才知道,這類指令實際上是“占位指令”,他們存在的意義在於占據那個地方,一來使其他語句能夠正確地按CPU覺得舒服的方式對齊,二來它可以占據CPU的某些周期,使得後續的指令能夠更好地並發執行,避免沖突。另一個比較常見的、實現類似功能的指令是NOP。
占位指令的去留主要是靠計時執行來判斷。由於目前流行的操作系統基本上都是多任務的,因此會對計時的精確性有一定影響。如果需要進行測試的話,需要保證以下幾點:
計時測試需要注意的問題
測試必須在沒有額外負荷的機器上完成。例如,專門用於編寫和調試程序的計算機 盡量終止計算機上運行的所有服務,特別是殺毒程序 切斷計算機的網絡,這樣網絡的影響會消失 將進程優先級調高。對於Windows系統來說,把進程(線程)設置為Time-Critical; 對於*nix系統來說,把進程設置為實時進程 將測試函數運行盡可能多次運行,如10000000次,這樣能夠減少由於進城切換而造成的偶然誤差 最後,如果可能的話,把函數放到單進程的系統(例如FreeDOS)中運行。
對於絕大多數程序來說,計時測試是一個非常重要的東西。我個人傾向於在進行優化後進行計時測試並比較結果。目前,我基於經驗進行的優化基本上都能夠提高程序的執行性能,但我還是不敢過於自信。優化確實會提高性能,但人做的和編譯器做的思路不同,有時,我們的確會做一些費力不討好的事情。