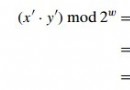第三章 操作內存
在前面的章節中,我們已經了解了寄存器的基本使用方法。而正如結尾提到的那樣,僅僅使用寄存器做一點運算是沒有什麼太大意義的,畢竟它們不能保存太多的數據,因此,對編程人員而言,他肯定迫切地希望訪問內存,以保存更多的數據。
我將分別介紹如何在保護模式和實模式操作內存,然而在此之前,我們先熟悉一下這兩種模式中內存的結構。
3.1 實模式
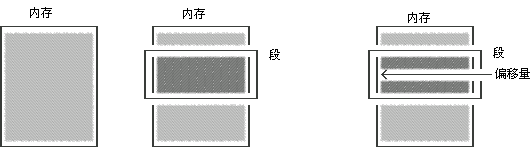
事實上,在實模式中,內存比保護模式中的結構更令人困惑。內存被分割成段,並且,操作內存時,需要指定段和偏移量。不過,理解這些概念是非常容易的事情。請看下面的圖:
段-寄存器這種格局是早期硬件電路限制留下的一個傷疤。地址總線在當時有20-bit。
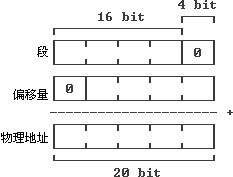
然而20-bit的地址不能放到16-bit的寄存器裡,這意味著有4-bit必須放到別的地方。因此,為了訪問所有的內存,必須使用兩個16-bit寄存器。
這一設計上的折衷方案導致了今天的段-偏移量格局。最初的設計中,其中一個寄存器只有4-bit有效,然而為了簡化程序,兩個寄存器都是16-bit有效,並在執行時求出加權和來標識20-bit地址。
偏移量是16-bit的,因此,一個段是64KB。下面的圖可以幫助你理解20-bit地址是如何形成的:
段-偏移量標識的地址通常記做 段:偏移量 的形式。
由於這樣的結構,一個內存有多個對應的地址。例如,0000:0010和0001:0000指的是同一內存地址。又如,
0000:1234 = 0123:0004 = 0120:0034 = 0100:0234
0001:1234 = 0124:0004 = 0120:0044 = 0100:0244
作為負面影響之一,在段上加1相當於在偏移量上加16,而不是一個“全新”的段。反之,在偏移量上加16也和在段上加1等價。某些時候,據此認為段的“粒度”是16字節。
練習題
嘗試一下將下面的地址轉化為20bit的地址:
稍高一些的要求是,寫一個程序將段為AX、偏移量為BX的地址轉換為20bit的地址,並保存於EAX中。
[上面習題的答案]
我們現在可以寫一個真正的程序了。
經典程序:Hello, world
;;; 應該得到一個29字節的.com文件; 程序結束的同時指定入口點為Main
那麼,我們需要解釋很多東西。
首先,作為匯編語言的抽象,C語言擁有“指針”這個數據類型。在匯編語言中,幾乎所有對內存的操作都是由對給定地址的內存進行訪問來完成的。這樣,在匯編語言中,絕大多數操作都要和指針產生或多或少的聯系。
這裡我想強調的是,由於這一特性,匯編語言中同樣會出現C程序中常見的緩沖區溢出問題。如果你正在設計一個與安全有關的系統,那麼最好是仔細檢查你用到的每一個串,例如,它們是否一定能夠以你預期的方式結束,以及(如果使用的話)你的緩沖區是否能保證實際可能輸入的數據不被寫入到它以外的地方。作為一個匯編語言程序員,你有義務檢查每一行代碼的可用性。
程序中的equ偽指令是宏匯編特有的,它的意思接近於C或Pascal中的const(常量)。多數情況下,equ偽指令並不為符號分配空間。
此外,匯編程序執行一項操作是非常繁瑣的,通常,在對與效率要求不高的地方,我們習慣使用系統提供的中斷服務來完成任務。例如本例中的中斷21h,它是DOS時代的中斷服務,在Windows中,它也被認為是Windows API的一部分(這一點可以在Microsoft的文檔中查到)。中斷可以被理解為高級語言中的子程序,但又不完全一樣——中斷使用系統棧來保存當前的機器狀態,可以由硬件發起,通過修改機器狀態字來反饋信息,等等。
那麼,最後一段通過DB存放的數據到底保存在哪裡了呢?答案是緊挨著代碼存放。在匯編語言中,DB和普通的指令的地位是相同的。如果你的匯編程序並不知道新的助記符(例如,新的處理器上的CPUID指令),而你很清楚,那麼可以用DB 機器碼的方式強行寫下指令。這意味著,你可以超越匯編器的能力撰寫匯編程序,然而,直接用機器碼編程是幾乎肯定是一件費力不討好的事——匯編器廠商會經常更新它所支持的指令集以適應市場需要,而且,你可以期待你的匯編其能夠產生正確的代碼,因為機器查表是不會出錯的。既然機器能夠幫我們做將程序轉換為代碼這件事情,那麼為什麼不讓它來做呢?
細心的讀者不難發現,在程序中我們沒有對DS進行賦值。那麼,這是否意味著程序的結果將是不可預測的呢?答案是否定的。DOS(或Windows中的MS-DOS VM)在加載.com文件的時候,會對寄存器進行很多初始化。.com文件被限制為小於64KB,這樣,它的代碼段、數據段都被裝入同樣的數值(即,初始狀態下DS=CS)。
也許會有人說,“嘿,這聽起來不太好,一個64KB的程序能做得了什麼呢?還有,你吹得天花亂墜的堆棧段在什麼地方?”那麼,我們來看看下面這個新的Hello world程序,它是一個EXE文件,在DOS實模式下運行。
;;; 應該得到一個561 字節的EXE文件; 采用“SMALL”內存模型
; 堆棧段
; 回車
; 換行
; DOS字符串結束符
; 定義數據段
; 定義顯示串
; 定義代碼段
; 將數據段
; 加載到DS寄存器
; 設置DX
; 顯示
; 終止程序
561字節?實現相同功能的程序大了這麼多!為什麼呢?我們看到,程序擁有了完整的堆棧段、數據段、代碼段,其中堆棧段足足占掉了512字節,其余的基本上沒什麼變化。
分成多個段有什麼好處呢?首先,它讓程序顯得更加清晰——你肯定更願意看一個結構清楚的程序,代碼中hard-coded的字符串、數據讓人覺得費解。比如,mov dx, 0152h肯定不如mov dx, offset Message來的親切。此外,通過分段你可以使用更多的內存,比如,代碼段騰出的空間可以做更多的事情。exe文件另一個吸引人的地方是它能夠實現“重定位”。現在你不需要指定程序入口點的地址了,因為系統會找到你的程序入口點,而不是死板的100h。
程序中的符號也會在系統加載的時候重新賦予新的地址。exe程序能夠保證你的設計容易地被實現,不需要考慮太多的細節。
當然,我們的主要目的是將匯編語言作為高級語言的一個有用的補充。如我在開始提到的那樣,真正完全用匯編語言實現的程序不一定就好,因為它不便於維護,而且,由於結構的原因,你也不太容易確保它是正確的;匯編語言是一種非結構化的語言,調試一個精心設計的匯編語言程序,即使對於一個老手來說也不啻是一場惡夢,因為你很可能掉到別人預設的“陷阱”中——這些技巧確實提高了代碼性能,然而你很可能不理解它,於是你把它改掉,接著就發現程序徹底敗掉了。使用匯編語言加強高級語言程序時,你要做的通常只是使用匯編指令,而不必搭建完整的匯編程序。絕大多數(也是目前我遇到的全部)C/C++編譯器都支持內嵌匯編,即在程序中使用匯編語言,而不必撰寫單獨的匯編語言程序——這可以節省你的不少精力,因為前面講述的那些偽指令,如equ等,都可以用你熟悉的高級語言方式來編寫,編譯器會把它轉換為適當的形式。
需要說明的是,在高級語言中一定要注意編譯結果。編譯器會對你的匯編程序做一些修改,這不一定符合你的要求(附帶說一句,有時編譯器會很聰明地調整指令順序來提高性能,這種情況下最好測試一下哪種寫法的效果更好),此時需要做一些更深入的修改,或者用db來強制編碼。
3.2 保護模式
實模式的東西說得太多了,盡管我已經刪掉了許多東西,並把一些原則性的問題拿到了這一節討論。這樣做不是沒有理由的——保護模式才是現在的程序(除了操作系統的底層啟動代碼)最常用的CPU模式。保護模式提供了很多令人耳目一新的功能,包括內存保護(這是保護模式這個名字的來源)、進程支持、更大的內存支持,等等。
對於一個編程人員來說,能“偷懶”是一件令人愉快的事情。這裡“偷懶”是說把“應該”由系統做的事情做的事情全都交給系統。為什麼呢?這出自一個基本思想——人總有犯錯誤的時候,然而規則不會,正確地了解規則之後,你可以期待它像你所了解的那樣執行。對於C程序來說,你自己用C語言寫的實現相同功能的函數通常沒有系統提供的函數性能好(除非你用了比函數庫好很多的算法),因為系統的函數往往使用了更好的優化,甚至可能不是用C語言直接編寫的。
當然,“偷懶”的意思是說,把那些應該讓機器做的事情交給計算機來做,因為它做得更好。我們應該把精力集中到設計算法,而不是編寫源代碼本身上,因為編譯器幾乎只能做等價優化,而實現相同功能,但使用更好算法的程序實現,則幾乎只能由人自己完成。
舉個例子,這樣一個函數:
int fun(){在某種編譯模式[DEBUG]下被編譯為
push ebp; 保護現場
; 初始化變量-調試版本特有。
; 本質是在堆中挖一塊地兒,存CCCCCCCC。
; 用串操作進行,這將發揮Intel處理器優勢
; ‘a=0’
; ‘i=0’
; 走著
; i++
; i<1000?
; a+=i;
; return a;
; 恢復現場
; 返回
而在另一種模式[RELEASE/MINSIZE]下卻被編譯為
xor eax,eax; a=0;
; i=0;
; a+=i;
; i++;
; i<1000?
; 是->繼續繼續
; return a
如果讓我來寫,多半會寫成
mov eax, 079f2ch; return 499500
為什麼這樣寫呢?我們看到,i是一個外界不能影響、也無法獲知的內部狀態量。作為這段程序來說,對它的計算對於結果並沒有直接的影響——它的存在不過是方便算法描述而已。並且我們看到的,這段程序實際上無論執行多少次,其結果都不會發生變化,因此,直接返回計算結果就可以了,計算是多余的(如果說一定要算,那麼應該是編譯器在編譯過程中完成它)。
更進一步,我們甚至希望編譯器能夠直接把這個函數變成一個符號常量,這樣連操作堆棧的過程也省掉了。
第三種結果屬於“等效”代碼,而不是“等價”代碼。作為用戶,很多時候是希望編譯器這樣做的,然而由於目前的技術尚不成熟,有時這種做法會造成一些問題(gcc和g++的頂級優化可以造成編譯出的FreeBSD內核行為異常,這是我在FreeBSD上遇到的唯一一次軟件原因的kernel panic),因此,並不是所有的編譯器都這樣做(另一方面的原因是,如果編譯器在這方面做的太過火,例如自動求解全部“固定”問題,那麼如果你的程序是解決固定的問題“很大”,如求解迷宮,那麼在編譯過程中你就會找錘子來砸計算機了)。然而,作為編譯器制造商,為了提高自己的產品的競爭力,往往會使用第三種代碼來做函數庫。正如前面所提到的那樣,這種優化往往不是編譯器本身的作用,盡管現代編譯程序擁有編譯執行、循環代碼外提、無用代碼去除等諸多優化功能,但它都不能保證程序最優。最後一種代碼恐怕很少有編譯器能夠做到,不信你可以用自己常用的編譯器加上各種優化選項試試:)
發現什麼了嗎?三種代碼中,對於內存的訪問一個比一個少。這樣做的理由是,盡可能地利用寄存器並減少對內存的訪問,可以提高代碼性能。在某些情況下,使代碼既小又快是可能的。
書歸正傳,我們來說說保護模式的內存模型。保護模式的內存和實模式有很多共同之處。
毫無疑問,以'protected mode'(保護模式), 'global descriptor table'(全局描述符表), 'local descriptor table'(本地描述符表)和'selector'(選擇器)搜索,你會得到完整介紹它們的大量信息。
保護模式與實模式的內存類似,然而,它們之間最大的區別就是保護模式的內存是“線性”的。
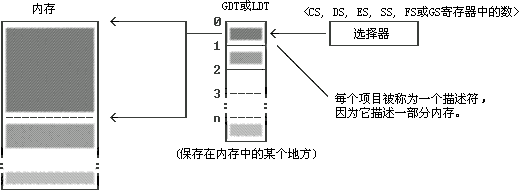
新的計算機上,32-bit的寄存器已經不是什麼新鮮事(如果你哪天聽說你的CPU的寄存器不是32-bit的,那麼它——簡直可以肯定地說——的字長要比32-bit還要多。新的個人機上已經開始逐步采用64-bit的CPU了),換言之,實際上段/偏移量這一格局已經不再需要了。盡管如此,在繼續看保護模式內存結構時,仍請記住段/偏移量的概念。不妨把段寄存器看作對於保護模式中的選擇器的一個模擬。選擇器是全局描述符表(Global Descriptor Table, GDT)或本地描述符表(Local Descriptor Table, LDT)的一個指針。
如圖所示,GDT和LDT的每一個項目都描述一塊內存。例如,一個項目中包含了某塊被描述的內存的物理的基地址、長度,以及其他一些相關信息。
保護模式是一個非常重要的概念,同時也是目前撰寫應用程序時,最常用的CPU模式(運行在新的計算機上的操作系統很少有在實模式下運行的)。
為什麼叫保護模式呢?它“保護”了什麼?答案是進程的內存。保護模式的主要目的在於允許多個進程同時運行,並保護它們的內存不受其他進程的侵犯。這有點類似於C++中的機制,然而它的強制力要大得多。如果你的進程在保護模式下以不恰當的方式訪問了內存(例如,寫了“只讀”內存,或讀了不可讀的內存,等等),那麼CPU就會產生一個異常。這個異常將交給操作系統處理,而這種處理,假如你的程序沒有特別說明操作系統該如何處理的話,一般就是殺掉做錯了事情的進程。
我像這樣的對話框大家一定非常熟悉(臨時寫了一個程序故意造成的錯誤):
好的,只是一個程序崩潰了,而操作系統的其他進程照常運行(同樣的程序在DOS中幾乎是板上釘釘的死機,因為NULL指針的位置恰好是中斷向量表),你甚至還可以調試它。
保護模式還有其他很多好處,在此就不一一贅述了。實模式和保護模式之間的切換問題我打算放在後面的“高級技巧”一章來講,因為多數程序並不涉及這個。
了解了內存的格局,我們就可以進入下一節——操作內存了。
3.3 操作內存
前兩節中,我們介紹了實模式和保護模式中使用的不同的內存格局。現在開始解釋如何使用這些知識。
回憶一下前面我們說過的,寄存器可以用作內存指針。現在,是他們發揮作用的時候了。
可以將內存想象為一個順序的字節流。使用指針,可以任意地操作(讀寫)內存。
現在我們需要一些其他的指令格式來描述對於內存的操作。操作內存時,首先需要的就是它的地址。
讓我們來看看下面的代碼:
mov ax,[0]
方括號表示,裡面的表達式指定的不是立即數,而是偏移量。在實模式中,DS:0中的那個字(16-bit長)將被裝入AX。
然而0是一個常數,如果需要在運行的時候加以改變,就需要一些特殊的技巧,比如程序自修改。匯編支持這個特性,然而我個人並不推薦這種方法——自修改大大降低程序的可讀性,並且還降低穩定性,性能還不一定好。我們需要另外的技術。
mov bx,0
mov ax,[bx]
看起來舒服了一些,不是嗎?BX寄存器的內容可以隨時更改,而不需要用冗長的代碼去修改自身,更不用擔心由此帶來的不穩定問題。
同樣的,mov指令也可以把數據保存到內存中:
mov [0],ax
在存儲器與寄存器之間交換數據應該足夠清楚了。
有些時候我們會需要操作符來描述內存數據的寬度:
操作符 意義 byte ptr 一個字節(8-bit, 1 byte) word ptr 一個字(16-bit) dword ptr 一個雙字(32-bit)例如,在DS:100h處保存1234h,以字存放:
mov word ptr [100h],01234h
於是我們將mov指令擴展為:
mov reg(8,16,32), mem(8,16,32)
mov mem(8,16,32), reg(8,16,32)
mov mem(8,16,32), imm(8,16,32)
需要說明的是,加減同樣也可以在[]中使用,例如:
mov ax,[bx+10]
mov ax,[bx+si]
mov ax,es:[di+bp]
等等。我們看到,對於內存的操作,即使使用MOV指令,也有許多種可能的方式。下一節中,我們將介紹如何操作串。