學習一門語言時,總有一些內容是需要在開始時強制記住的,否則後面的內容無法進行。這節我們就先來說一些在學習Python前需要了解的內容。
古人雲“工欲善其事,必先利其器”,選擇一個合適的開發工具,可以幫助我們提高工作效率。通常有以下幾種工具可以選擇:
有些人認為剛開始學習一門編程語言時,應該使用記事本或notepad++這樣簡單的工具,減少對高級GUI開發工具的依賴,這樣可以更清楚的明白被開發工具屏蔽掉的語言底層的運行過程和原理。但是這個還是看個人吧,比如我覺得一個新手剛開始就使用沒有任何提示的開發工具會降低練習的效率,甚至會進一步打擊自信心和學習動力。如果一開始就對它新生畏懼,那將來是很難把它學好的。
當然如何選擇還是由看官自己決定,這裡推薦的開發python的GUI工具是Pycharm,理由如下:
在任意一個目錄下創建一個hello.py文件,我們來輸出一個經典語句"Hello World!"
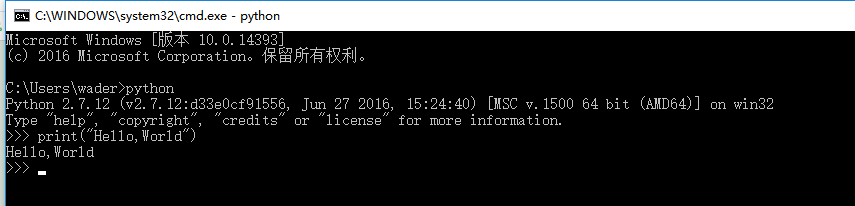
print("Hello, World")執行hello.py這個python腳本的方式是:
python hello.py
輸出為:
Hello, World
當然也可以直接進入python解釋器交互式終端去執行print("Hello, World"),如下圖所示:
思考:為什麼打印一句“Hello World”已經成為很多人學習一門新語言的第一句代碼?
有人說,這是學習一門語言入門的象征,因為寫完了這個我就可以對別人說“我會寫xx語言的程序了”。本人認為要理解為什麼Hello World如此簡單,卻又如此廣為人知並被傳頌,只需要想清楚一個問題:這個程序帶給我們什麼?
它告訴我們在這個編程語言中基本的輸出語句是怎樣的,這很重要;
它告訴我們要怎樣去執行這個編程語言編寫的程序,這同樣很重要。
如果不知道上述兩個問題,我們將寸步難行。
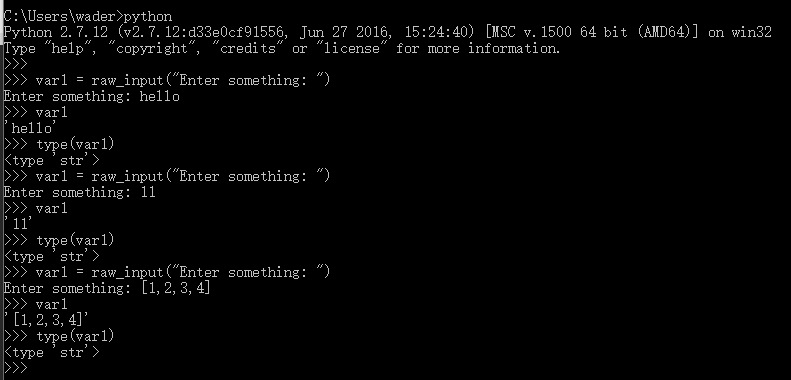
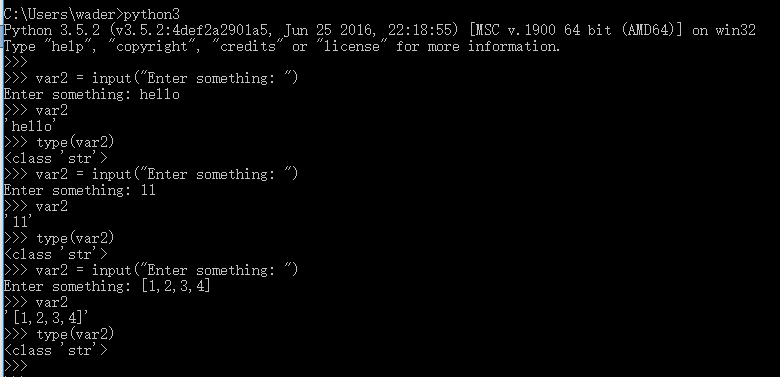
我們分別使用Python2.7 和 Python3.5的解釋器提供的交互式終端來分別執行以下兩條指令:
print("Hello, World")
print "Hello, World"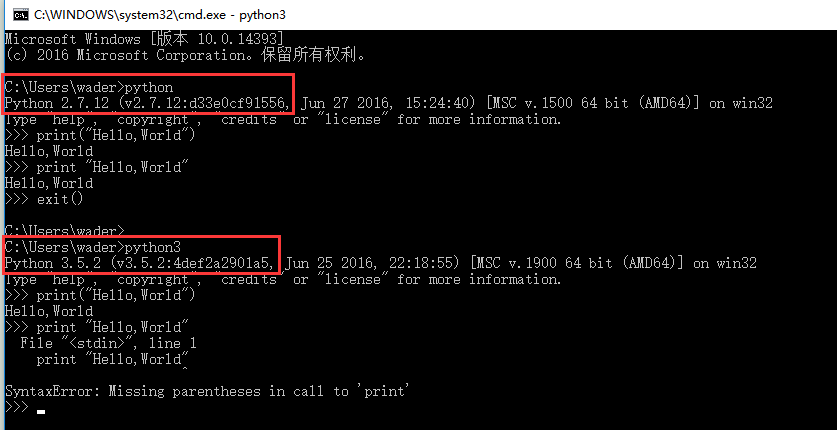
通過上圖的執行結果會發現,print "Hello, World" 這條語句在Python2.7中可以正常執行,而在Python 3.5中會報錯,也就是說Python 3.x與Python 2.x是不兼容的。這貌似是Python開發者犯的一個錯誤,而事實是Guido Van Rossum(Python語言的最初創建者)故意為之。Guido的本意就是想不考慮太多向後兼容性的問題,去適當地清理一下Python 2.x中不合理的內容,而不是把Python 3.x簡單的當做對Python 2.x的更新版本。
實際上,Python 3.0在2008年12月就已經發布了,Python官方在2010年年中發布2.7時宣布,2.7將是Python 2.x的最後一個主發布版本。其實Python 2.7 是向Python 3.x的一個過渡版本,裡面支持了一些Python 3.x的特性。
2014年11月,Python官方宣布Python 2.7將會被支持到2020年,並再次確認了不會有Python 2.8發布,希望用戶盡快遷移到Python 3.4+ 。3.x正在處於積極開發狀態,並且在過去5年裡已經發布了多個穩定版本,包括2012年的3.3,2014年的3.4,2015年的3.5。這意味著最近所有的標准庫更新將默認只能在Python 3.x中可用。
在Python 3.x中,輸出語句需要使用print()函數,該函數接收一個關鍵字參數,以此來代替Python 2.x中的大部分特殊語法。下面是幾個對比項:
Python 2.x中使用的默認字符編碼為ASCII碼,要使用中文字符的話需要指定使用的字符編碼,如UTF-8;Python 3.x中使用的默認字符編碼為Unicode,就不存在這個問題了。
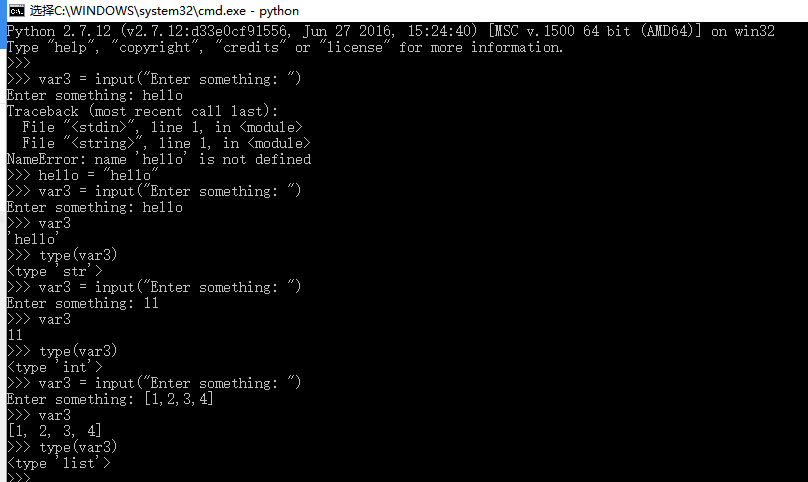
python 2.x中如果要給多個變量同時賦值,要求=號右邊的表達式返回結果的個數要與=號左邊接收值的變量個數相等,不能多,也不能少。如:
a,b,c = (1,2,3) # 正常,a=1, b=2, c=3
a,b,c = range(5) # 報錯,ValueError: too many values to unpack
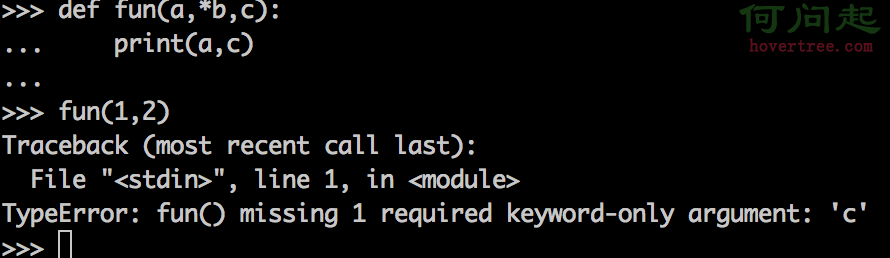
a,b,c,d,e = [1,2,3] # 報錯,ValueError: need more than 3 values to unpack python 3.x中允許=號昨邊的變量數小於=號右邊表達式返回的結果的個數,但是需要有1個且只能有1個字典類型的變量來接收多余的返回值。與python 2.x相同的是 python 3.x中=號左邊的變量數也是不能多與=號右邊表達式的返回值個數,但是錯誤提示語更清晰了。
a,b,c = (1,2,3) # 正常,a=1, b=2, c=3
a,*b,c = range(5) # 正常,a=0, b=[1,2,3], c=4
a,b,c,d,e = [1,2,3] # 報錯,ValueError: not enough values to unpack (expected 5, got 3)如果是要開發一個新項目,不用考慮與老項目的兼容問題,最好是使用Python 3,因為就像Python官方說的那樣,Python 3才是Python語言的將來。現在很多第三方類庫已經完成了或者正在積極完成對Python 3的支持,只是有些項目由於過於龐大,很難在短時間內完成。我們需要考慮的最大問題在於,新項目中是否存在必須的第三方類庫,且該類庫當前還不支持Python 3。如果不存在這個問題,那堅定的選擇Python 3吧。
這是只是簡單說下Python中變量的定義和使用,方便繼續下面的內容。事實上,Python中變量的使用確實很簡單:
name = "wader"
age =28
print("Name: ", name,) # Name: wader
print("Age : ", age) # Age : 28python定義變量無需指定變量類型,python解釋器會在運行時自動推斷變量的數據類型。我們可以通過type()方法來查看變量類型:
type(name) # str
type(age) # int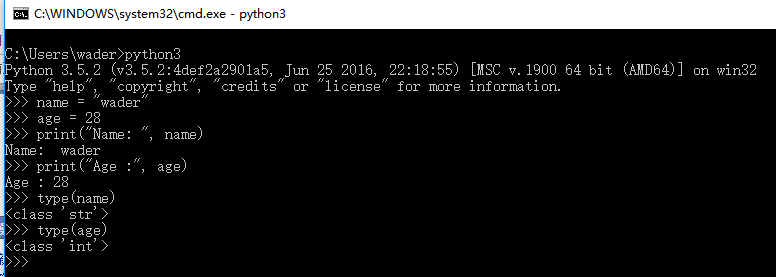
事實上,Python中沒有語法約束下的常量,僅僅是用完全大寫字母的變量來表示這個變量不應該被改變。
COUNT = 10很多時候都需要與用戶進行交互,通過用戶輸入的內容來做下一步操作。這裡需要說明的是,Python 2 與Python 3中接收用戶輸入的方法是不一樣的。
Python 2中接收用戶輸入時,主要使用的是raw_input()函數:
name = raw_input("Enter your name: ")
print "Your name is ", name
Python 3中接收用戶輸入時,主要使用的是input()函數:
name = input("Enter your name: ")
print("Your name is ", name)
計算機只認識0和1組成的二進制序列,因此任何文件中的內容要想被計算機識別或者想存儲在計算機上都需要轉換為二進制序列。那麼字符與二進制序列怎麼進行想換轉換呢?於是人們嘗試建立一個表格來存儲一個字符與一個二進制序列的對應關系。
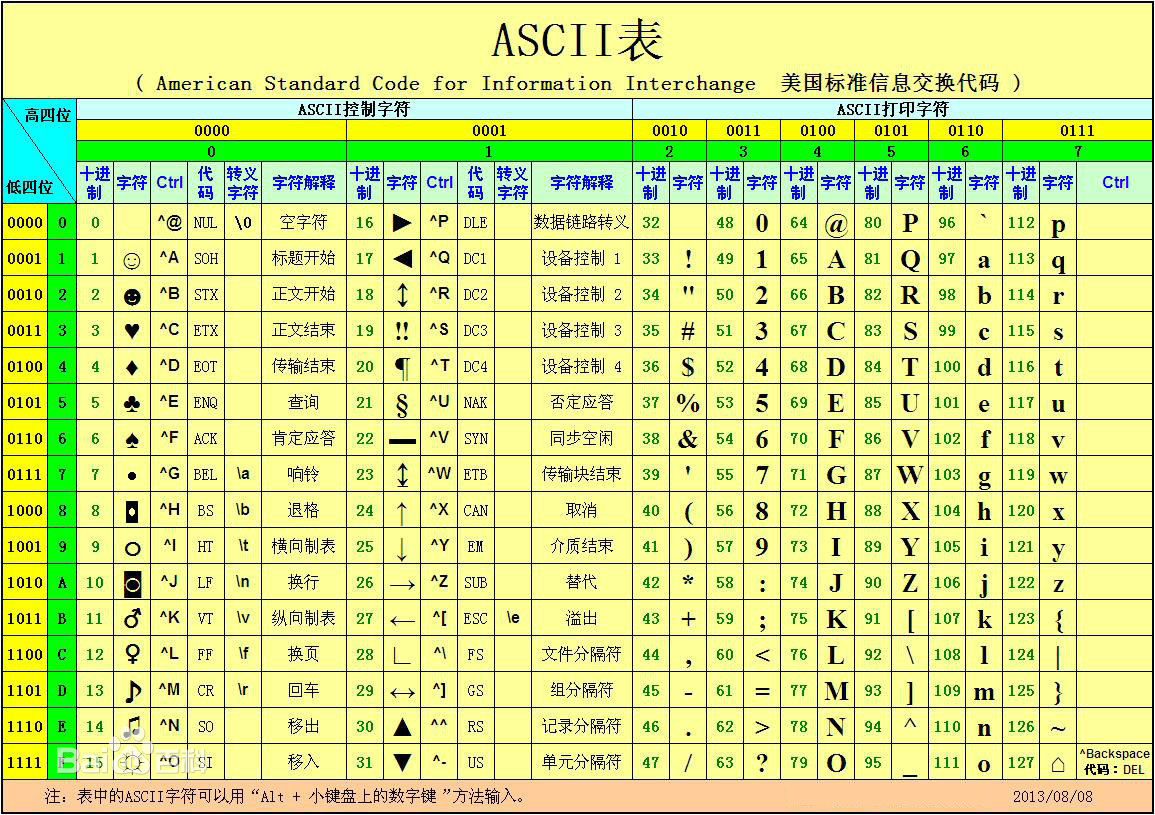
最早建立這個字符與十進制數字對應的關系的是美國,這張表被稱為ASCII碼(American Standard Code for Information Interface, 美國標准信息交換代碼)。ASCII碼是基於拉丁字母的一套電腦編程系統,主要用於顯示現代英語和其他西歐語言。它被設計為用1個字節來表示一個字符,所以ASCII碼表最多只能表示2**8=256個字符。實際上ASCII碼表中只有128個字符,剩余的128個字符是預留擴展用的。
隨著計算機的普及和發展,很過國家都開始使用計算機。大家發現ASCII碼預留的128個位置根本無法存儲自己國家的文字和字符,因此各個國家開始制定各自的字符編碼表,其中中國的的字符編碼表有GB2312和GBK。
後來隨著世界互聯網的形成和發展,各國的人們開始有了互相交流的需要。但是這個時候就存在一個問題,每個國家所使用的字符編碼表都是不同的。比如我們發送一句“你好,我好喜歡你演的愛情動作電影!”給島國的倉老師,蒼老師電腦上用的是日本的字符編碼表,因此她的電腦無法正確顯示我們發送的內容。這個時候,人們希望有一個世界統一的字符編碼表來存放所有國家所使用的文字和符號,這就是Unicode。Unicode又被稱為 統一碼、萬國碼、單一碼,它是為了解決傳統的字符編碼方案的局限性而產生的,它為每種語言中的每個字符設定了統一並且為之一的二進制編碼。Unicode規定所有的字符和符號最少由2個字節(16位)來表示,所以Unicode碼可以表示的最少字符個數為2**16=65536。
為什麼已經有了Unicode還要UTF-8呢?這是由於當時存儲設備是非常昂貴的,而Unicode中規定所有字符最少要由2個字節表示。人們認為像原來ASCII碼中的字符用1個字節就可以了,因此人們決定創建一個新的字符編碼來節省存儲空間。UTF-8是對Unicode編碼的壓縮和優化,它不在要求最少使用2個字節,而是將所有字符和符號進行分類:
UTF-8是目前最常用,也是被推薦使用的字符編碼。
我們上面提到過,一般在兩個地方會用到字符編碼:
磁盤寫入或讀取數據時使用的字符編碼是由編輯器指定的工程或文件的字符編碼決定的,這與Python解釋器是無關的;但是Python程序執行時,將Python腳本文件加載到內存時所使用的字符編碼是主要問題所在。在Python 2中,Python解釋器默認使用的是ASCII碼,此時如果要運行的程序中如果有中文Python解釋器就會報錯。
print("你好,世界")SyntaxError: Non-ASCII character '\xe4' in file C:/Users/wader/PycharmProjects/LearnPython/day01/code.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
這是因為Python解釋器執行該程序時試圖從ASCII編碼表中查找中文字符對應的二進制序列,但是發現找不到。此時要想該程序正常運行,就需要在python腳本文件的開始位置聲明該文件的所使用的字符編碼:
# -*- coding:utf-8 -*-
print("你好,世界")需要說明的是:
Python 3的解釋器默認使用Unicode編碼,它本身是可以對中文字符進行編碼和解碼的,所以即便不指定字符編碼也能正常運行,但是還是建議保留字符編碼的聲明。
通常python腳本都是跑在Linux上的,為了讓python腳本文件可以像shell腳本那樣可以直接調用執行,我們通常需要在python文件最開始的位置指定python解釋器:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
print("你好,世界")不建議寫python解釋器的絕對路徑,如:
#!/usr/bin/python
# -*- coding:utf-8 -*-
print("你好,世界")因為這樣寫的話,將來要想更換python解釋器是非常麻煩的。
單行注釋:# 注釋
如果注釋與代碼不在同一行,通常注釋位於代碼的上面一行,且#號與注釋內容之間至少要有一個空格。
#!/usr/bin/python
# -*- coding:utf-8 -*-
# 這是單行注釋
print("你好,世界")如果注釋與代碼在同一行,注釋要寫在代碼的後面,且代碼與#號之間至少要有2個空格,同時#號與注釋內容之間至少要有1個空格。
#!/usr/bin/python
# -*- coding:utf-8 -*-
print("你好,世界") # 這是單行注釋多行注釋的內容要用3個引號包起來,可以用單引號,也可以用雙引號。
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
這是多行注釋
這是多行注釋
這是多行注釋
"""
print("你好,世界")當Python內置的核心模塊提供的功能無法滿足我們的需求時就需要導入外部模塊,而導入模塊的功能有兩種方式:
例如,要想查看或更改python查找模塊的路徑列表就需要使用sys模塊下的path變量;若需要執行系統命令可以使用os模塊下的system()方法。
import sys
from os import system
print(sys.path)
print(system("ping hovertree.com"))
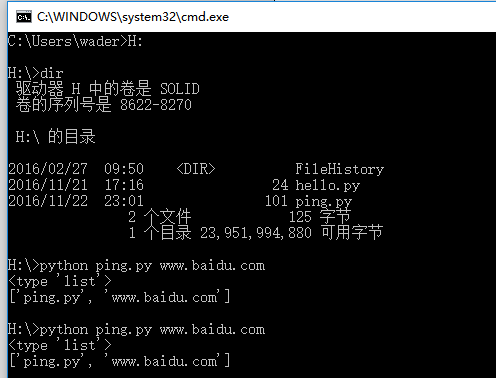
我們在寫shell腳本時,經常會通過接受執行腳本時傳入的變量來做相應的操作,來保證腳本的靈活性。比如我們要寫一個腳本來調用ping命令對指定的域名進行ping測試,這時候顯然將域名當做參數傳遞給腳本要比把域名寫死在腳本中靈活的多。shell中可以只用$1,$2這樣的特殊變量來獲取傳入的參數,而python中需要用sys模塊下的argv變量來獲取。
sys.argv是一個列表,與shell相同,其第一個元素是當前腳本的名稱,之後才是傳入的參數。
編寫一個ping.py,內容如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import sys
import os
print(type(sys.argv))
print(sys.argv)執行該腳本,結果如下圖所示:
在Java和C語言中用花括號{}包起來的部分就是一個代碼塊,shell腳本中的代碼塊是由專門的開始和結束標識的,而python中的代碼塊是靠“縮進對齊”來表示的。下面我們分別一個if-else的條件判斷來對這幾個語言的代碼塊表示方式做一個對比:
...
int a = 3;
int b = 5;
int big_num;
if(a > b){
big_num = a;
}else{
big_num = b;
}
System.out.println(big_num)
...declare -i a=3
declare -i b=5
declare -i big_num
if [ $a -gt $b ];then
big_num=$a
else
big_num=$b
fi
echo $big_numa = 3
b = 5
if a > b:
big_num = a
else:
big_num = b
print(big_num)在之前的文章我們已經解釋過:Python是一個動態的、強類型的、解釋型的編程語言。而實際上,解釋型語言與編譯型語言的界限正在變得模糊。包括Python在內的很多高級編程語言,會將源代碼先編譯成特定類型的中間代碼,然後再由解釋器去執行,這樣可以提高執行效率。Python的解釋器同時也是生成Python中間代碼的編譯器,.pyc文件就是存放Python中間代碼的文件。執行Python代碼時,如果該源碼文件導入了其他的.py文件,那麼執行過程中會自動生成一個與導入的.py文件同名的.pyc文件。