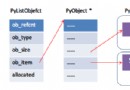
本來說完字符串、數字、布爾值之後,應該要繼續講元祖、列表之類的。但是元祖和列表都屬於序列,所以有必要先講講python的序列是什麼。
首先,序列是是Python中最基本的數據結構。序列中的每個元素都分配一個數字 - 它的位置,或索引,第一個索引是0,第二個索引是1,依此類推。每個索引對應一個元素。
Python包含 6 中內建的序列,包括列表、元組、字符串、Unicode字符串、buffer對象和xrange對象。
對於序列,都可以使用以下操作:
1.索引
2.切片
3.加
4.乘
5.成員檢查
6.計算序列的長度
7.取序列中的最大、最小值
1.索引
所謂的索引就是對每個元素進行編號,注意,編號是從0開始的。
我們可用通過索引來取得其對應的元素:
對於字符串:
a = 'scolia' b = a[3] print b print type(b)

注意:對字符串而言,取出的元素依然是字符串類型。
對於元祖:
a = ('scolia', 123, True,(),[])
b = a[0]
c = a[1]
print b
print type(b)
print c
print type(c)

取出來的元素原來是什麼類型就是什麼類型,為什麼會這樣呢,看下面這個例子:


竟然是同一個對象,也就是說變量 l 和變量b 指向了同一個內存空間。
def text():
print 'scolia'
a = ('scolia', 123, True, (), text)
b = a[4]
b()

裡面放函數也可以,那麼這樣呢?
l = []
a = ('scolia', 123, True, (), l)
b = a[4]
b.append(1) #append()是列表的一個方法,將一個元素添加到列表的最後,對原列表進行操作,但返回值為None
print l
print b

我們對取出來的元素進行了操作,竟然影響了原列表。
這說明了:
元祖其實是一個容器,裡面可以放任何的對象,而當我們通過索引去取的時候,取到的原對象。那麼我看是不是可以將索引看作是一個特別的變量,它指向的也是內存空間,當然這個說法套到字符串中略顯變扭,我們只能假設字符串是將每個字符都存在一個內存空間中,每個字符都是字符串類型,變量取得的是整個字符串,而索引則是每個字符的變量。當然這只是假設,具體python內部如何處理我也不知道,也許有一天我該去讀一下python的源碼的。
2.切片
所謂切片就是一次拿出多個對象,而索引一次只能拿出一個對象。
a = ('scolia', 123, True)
b = a[0:2]
print b

返回的依然是一個元祖,這裡要注意一個問題,那就是 a[2] 明明是 True 才對,但結果我們並沒有取到,說明切片是不包括後界限的索引的。
另外,我可以只寫其中的一個:
a = ('scolia', 123, True)
b = a[1:]
print b

表示從某索引開始(包括),取到結束。
a = ('scolia', 123, True)
b = a[:2]
print b

表示從最開始,取到結束的索引(不包括)。
另外,還可以使用負數:
a = ('scolia', 123, True)
b = a[-2:]
print b

正數表示索引是從左向右計算的,而負數則表示倒數,如-1就表示倒數第一個。
但是,取對象的方向還是從左到右的,這裡要注意下。

但如果我這樣寫呢:
a = ('scolia', 123, True)
b = a[-1:-3]
print b
開頭的索引在結束的索引的右邊,是不是就可以倒過來取了呢?
答案是:

不可以,得到空的。看來一定要從左向右取對象。
還有,當我給的索引超出了呢?
a = ('scolia', 123, True)
b = a[0:100]
print b

python能自動處理索引超出的問題,這也是python優雅的所在。
但是要注意:
a = ('scolia', 123, True)
b = a[10:100]
print b

這樣就取不到了。
最後,還有一個小技巧,雖然切片得到的是一個元祖,但能找到我們切片得到了幾個元素,如果此時我用多個變量去承接呢?
a = ('scolia', 123, True)
b,c,d = a[:] #這裡能得到原序列,此外還涉及到深淺拷貝的問題,以後再來解釋
print b
print c
print d

這樣我能得到獨立的對象了。
3.加
對序列進行加法運算,將返回一個新的對象。
a = ('scolia', 123, True)
b = ('good', 456)
c = a + b
print a
print b
print c

並沒有影響到原序列。
那麼不同類型的序列相加呢?
a = ('scolia', 123, True)
b = ['good', 456]
c = a + b
print a
print b
print c

不行。
列表的相加也是一樣的,這裡不重復舉例。
另外,和字符串的+號拼接也是一樣的。
4.乘
乘法和加法類似,只是幾個一樣的序列相加而已,這點和數學的乘法一樣。
a = ('scolia', 123, True)
b = a*2
print a
print b

同樣不影響原序列
5.成員檢查
這裡主要是 in 和 not in 運算符的使用。
b = 3000
print id(b)
a = ('scolia', 3000, True)
print b in a
print id(a[1]), id(b)

這裡的結果很奇怪,如果還記得python中的緩存池(上篇有說過)的話,不是說數字只在 -5~257 才會有緩存行為嗎?看來python內部針對這種情況特別做了優化,達到了節省內存的效果。
就算賦值行為在下面也一樣。
a = ('scolia', 3000, True)
b = 3000
print b in a
print id(a[1]), id(b)

看來在變量賦值時還有隱藏行為,python會檢查元祖和列表中是否已經有一樣的對象了,若有則賦值時不重新創建,而是重復引用。
6.元素長度計算
其實是 len() 內置函數的調用,該函數會返回容器中元素的數量。
a = ('scolia', 3000, True)
print len(a)

計算是從1開始的,和索引不同,要注意區分。
還有,雖然這裡是寫在序列之中,但是這個方法對字典也適用,而字典算是特殊的一種'序列'。
a = {'a':1,'b':2}
print len(a)

7.取序列中的最大、最小值
這裡其實是內置函數 max() 和 max() 的使用,其會返回序列中的最大、最小值。
關於不同數據的比較請參照:戳這裡
或者參考我之前關於python的數字的博文。
a = ('scolia', 3000, True)
print max(a)

關於序列的內容暫時寫這麼多,以後有需要的話會繼續補充。