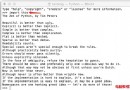
當我們使用load()函數從文件裡取出已保存的對象時。pickle知道怎樣恢復這些對象到它們本來的格式。
dumps()函數運行和dump() 函數同樣的序列化。代替接受流對象並將序列化後的數據保存到磁盤文件,這個函數簡單的返回序列化的數據。
loads()函數運行和load() 函數一樣的反序列化。代替接受一個流對象並去文件讀取序列化後的數據,它接受包括序列化後的數據的str對象, 直接返回的對象。
cPickle是pickle得一個更快得C語言編譯版本號。
pickle和cPickle相當於java的序列化和反序列化操作
#! /usr/local/env python
# -*- coding=utf-8 -*-
if __name__ == "__main__":
import cPickle
#序列化到文件
obj = 123,"abcdedf",["ac",123],{"key":"value","key1":"value1"}
print obj
#輸出:(123, abcdedf, [ac, 123], {key1: value1, key: value})
#r 讀寫權限 r b 讀寫到二進制文件
f = open(r"d:a.txt","r ")
cPickle.dump(obj,f)
f.close()
f = open(r"d:a.txt")
print cPickle.load(f)
#輸出:(123, abcdedf, [ac, 123], {key1: value1, key: value})
#序列化到內存(字符串格式保存),然後對象能夠以不論什麼方式處理如通過網絡傳輸
obj1 = cPickle.dumps(obj)
print type(obj1)
#輸出:<type str>
print obj1
#輸出:python專用的存儲格式
obj2 = cPickle.loads(obj1)
print type(obj2)
#輸出:<type tuple>
print obj2
#輸出:(123, abcdedf, [ac, 123], {key1: value1, key: value})