初學Python,遇到過這樣的問題,在遍歷list的時候,刪除符合條件的數據,可是總是報異常,代碼如下:
num_list = [1, 2, 3, 4, 5]
print(num_list)
for i in range(len(num_list)):
if num_list[i] == 2:
num_list.pop(i)
else:
print(num_list[i])
print(num_list)
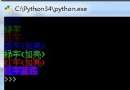
會報異常:IndexError: list index out of range
原因是在刪除list中的元素後,list的實際長度變小了,但是循環次數沒有減少,依然按照原來list的長度進行遍歷,所以會造成索引溢出。
於是我修改了代碼如下:
num_list = [1, 2, 3, 4, 5]
print(num_list)
for i in range(len(num_list)):
if i >= len(num_list):
break
if num_list[i] == 2:
num_list.pop(i)
else:
print(num_list[i])
print(num_list)
這回不會報異常了,但是打印結果如下:
[1, 2, 3, 4, 5] 1 4 5
[1, 3, 4, 5]
[Finished in 0.128s]
雖然最後,list中的元素[2]確實被刪除掉了,但是,在循環中的打印結果不對,少打印了[3]。
思考了下,知道了原因,當符合條件,刪除元素[2]之後,後面的元素全部往前移,於是[3, 4, 5]向前移動,那麼元素[3]的索引,就變成了之前[2]的索引(現在[3]的下標索引變為1了),後面的元素以此類推。可是,下一次for循環的時候,是從下標索引2開始的,於是,取出了元素[4],就把[3]漏掉了。
把代碼修改成如下,結果一樣,絲毫沒有改觀:
num_list = [1, 2, 3, 4, 5]
print(num_list)
for item in num_list:
if item == 2:
num_list.remove(item)
else:
print(item)
print(num_list)
既然知道了問題的根本原因所在,想要找到正確的方法,也並不難,於是我寫了如下的代碼:
num_list = [1, 2, 3, 4, 5]
print(num_list)
i = 0
while i < len(num_list):
if num_list[i] == 2:
num_list.pop(i)
i -= 1
else:
print(num_list[i])
i += 1
print(num_list)
執行結果,完全正確:
[1, 2, 3, 4, 5] 1 3 4 5 [1, 3, 4, 5]
[Finished in 0.122s]
我的做法是,既然用for循環不行,那就換個思路,用while循環來搞定。每次while循環的時候,都會去檢查list的長度(i < len(num_list)),這樣,就避免了索引溢出,然後,在符合條件,刪除元素[2]之後,手動把當前下標索引-1,以使下一次循環的時候,通過-1後的下標索引取出來的元素是[3],而不是略過[3]。
當然,這還不是最優解,所以,我搜索到了通用的解決方案:1、倒序循環遍歷;2、遍歷拷貝的list,操作原始的list。
1、倒序循環:
num_list = [1, 2, 3, 4, 5]
print(num_list)
for i in range(len(num_list)-1, -1, -1):
if num_list[i] == 2:
num_list.pop(i)
else:
print(num_list[i])
print(num_list)
執行結果完全正確。
2、遍歷拷貝的list,操作原始的list
num_list = [1, 2, 3, 4, 5]
print(num_list)
for item in num_list[:]:
if item == 2:
num_list.remove(item)else:
print(item)
print(num_list)
原始的list是num_list,那麼其實,num_list[:]是對原始的num_list的一個拷貝,是一個新的list,所以,我們遍歷新的list,而刪除原始的list中的元素,則既不會引起索引溢出,最後又能夠得到想要的最終結果。此方法的缺點可能是,對於過大的list,拷貝後可能很占內存。那麼對於這種情況,可以用倒序遍歷的方法來實現。
IndexError: list index out of range