今天我們一起來學習一個 Python 爬蟲實戰案例,我們的目標網站就是東方財富網,廢話不多說,開搞
東方財富網地址如下
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
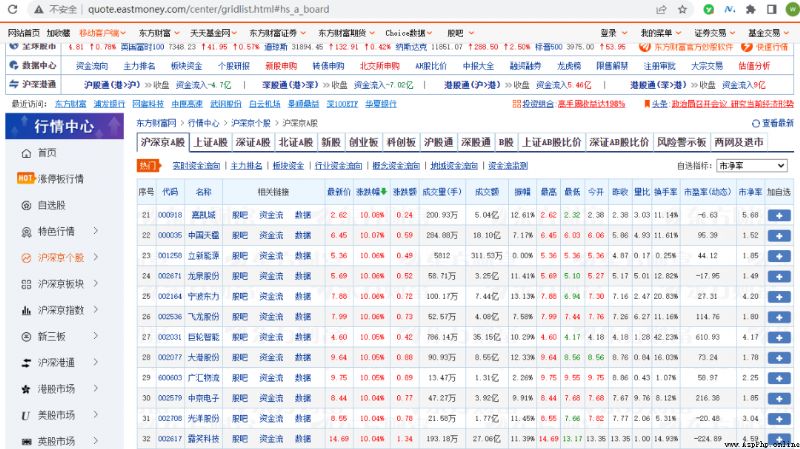
我們通過點擊該網站的下一頁發現,網頁內容有變化,但是網站的 URL 卻不變,也就是說這裡使用了 Ajax 技術,動態從服務器拉取數據,這種方式的好處是可以在不重新加載整幅網頁的情況下更新部分數據,減輕網絡負荷,加快頁面加載速度。
我們通過 F12 來查看網絡請求情況,可以很容易的發現,網頁上的數據都是通過如下地址請求的
http://38.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409036039385296142_1658838397275&pn=3&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838404848
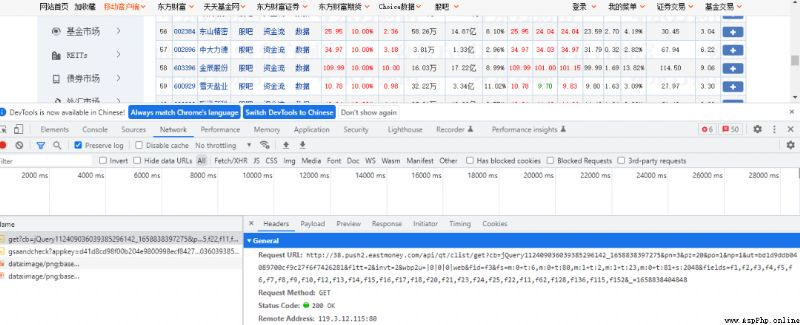
接下來我們多請求幾次,來觀察該地址的變化情況,發現其中的pn參數代表這頁數,於是,我們可以通過修改&pn=後面的數字來訪問不同頁面對應的數據
import requests
json_url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402508937289440778_1658838703304&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838703305"
res = requests.get(json_url)
接下來我們觀察返回的數據,可以看出數據並不是標准的 json 數據

於是我們先進行 json 化
result = res.text.split("jQuery112402508937289440778_1658838703304")[1].split("(")[1].split(");")[0]
result_json = json.loads(result)
result_json
Output:
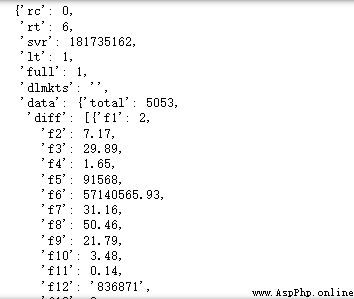
這樣數據就整齊多了,所有的股票數據都在data.diff下面,我們只需要編寫解析函數即可
返回各參數對應含義:
f2:最新價
f3:漲跌幅
f4:漲跌額
f5:成交量(手)
f6:成交額
f7:振幅
f8:換手率
f9:市盈率
f10:量比
f12:股票代碼
f14:股票名稱
f15:最高
f16:最低
f17:今開
f18:昨收
f22:市淨率
先准備一個存儲函數
def save_data(data, date):
if not os.path.exists(r'stock_data_%s.csv' % date):
with open("stock_data_%s.csv" % date, "a+", encoding='utf-8') as f:
f.write("股票代碼,股票名稱,最新價,漲跌幅,漲跌額,成交量(手),成交額,振幅,換手率,市盈率,量比,最高,最低,今開,昨收,市淨率\n")
for i in data:
Code = i["f12"]
Name = i["f14"]
Close = i['f2']
ChangePercent = i["f3"]
Change = i['f4']
Volume = i['f5']
Amount = i['f6']
Amplitude = i['f7']
TurnoverRate = i['f8']
PERation = i['f9']
VolumeRate = i['f10']
Hign = i['f15']
Low = i['f16']
Open = i['f17']
PreviousClose = i['f18']
PB = i['f22']
row = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format(
Code,Name,Close,ChangePercent,Change,Volume,Amount,Amplitude,
TurnoverRate,PERation,VolumeRate,Hign,Low,Open,PreviousClose,PB)
f.write(row)
f.write('\n')
else:
...
然後再把前面處理好的 json 數據傳入
stock_data = result_json['data']['diff']
save_data(stock_data, '2022-07-28')
這樣我們就得到了第一頁的股票數據
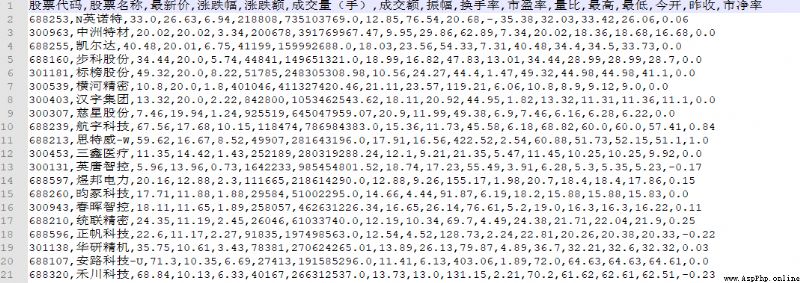
最後我們只需要循環抓取所有網頁即可
for i in range(1, 5):
print("抓取網頁%s" % str(i))
url = "http://48.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402508937289440778_1658838703304&pn=%s&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1658838703305" % str(i)
res = requests.get(json_url)
result = res.text.split("jQuery112402508937289440778_1658838703304")[1].split("(")[1].split(");")[0]
result_json = json.loads(result)
stock_data = result_json['data']['diff']
save_data(stock_data, '2022-07-28')
這樣我們就完成了整個股票數據的抓取,喜歡就點個贊吧~
後面我們還會基於以上代碼,完成一個股票數據抓取 GUI 程序,再之後再一起完成一個股票數據 Web 展示程序,最終完成一個股票量化平台,敬請期待哦!
【python學習】
學Python的伙伴,歡迎加入新的交流【君羊】:1020465983
一起探討編程知識,成為大神,群裡還有軟件安裝包,實戰案例、學習資料