在大數據的處理過程中,目前最流行的開源框架無非就是hadoop體系,那說到Hadoop 最核心的兩個部分無非就是HDFS、MapReduce,前者主要是用來存儲數據,後者則是用來計算處理數據的,在此基礎上如果要處理海量的數據就必須要基於此進行創建mapper、reduce、partition、job驅動等操作,這樣一套流程下來,開發人員是不是很頭大,為什麼呢 工作繁瑣開發效率太低,那有沒有更好的簡單的解決方案呢? 還真有,推薦使用Facebook開源的Hive
Hive是什麼呢? 其實就是針對MapReduce進行了二次封裝,方便開發人員通過大家熟悉的SQL腳本來便捷的操作Hadoop集群上的數據,基本的工作流程是開發人員首先編寫要操作數據的SQL,其次連接上Hive,然後Hive會將你書寫的SQL轉為MapReduce任務,最後這些任務會在Hadoop集群上運行,具體流程如下: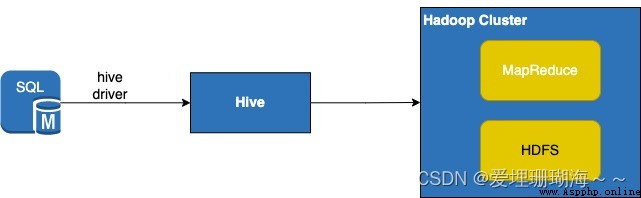
本文介紹主要是使用python開發語言實現,其他語言可以參考對應的官方API文檔
基於此,我們首先需要安裝Hive的環境,其次客戶端代碼需要引入hive驅動包
安裝Hive環境不在本篇文章介紹,本文側重點於客戶端代碼怎麼實現操作hive的流程
引入hive包
$pip3 install pyhive
from pyhive import hive
class HiveUtils:
def query_count_data(self,query_count_sql,sql_config):
''' 統計表總條數 '''
logger.info('query_sql:%s',query_count_sql)
hive_conn = self.__get_connection(sql_config)
hive_cursor = hive_conn.cursor()
hive_cursor.execute(query_count_sql)
list_res = hive_cursor.fetchall()
total_count = list_res[0][0]
logger.info('get total_count:%s',total_count)
hive_cursor.close()
hive_conn.close()
return total_count
@retry(stop=stop_after_attempt(5), wait=wait_fixed(10))
def __get_connection(self,sql_config):
''' 連接不上時重試5次,每次重試延時10秒 '''
logger.info('start to connect to hive ...')
hive_connection = hive.Connection(host=sql_config.host
, port=sql_config.port
, username=sql_config.user_name
, database=sql_config.db_name)
logger.info('connect to hive successful!')
return hive_connection
 If you learn Python this way during the summer vacation, you can earn tens of thousands of yuan a month (with free self-study tutorials)
If you learn Python this way during the summer vacation, you can earn tens of thousands of yuan a month (with free self-study tutorials)
Everybody knows , Now programm