In the process of big data processing,The most popular open source frameworks today are nothing more thanhadoop體系,那說到Hadoop The two core parts are nothing more thanHDFS、MapReduce,The former is mainly used to store data,The latter is used to calculate and process data,On this basis, if you want to process massive data, you must create it based on thismapper、reduce、partition、jobdrive, etc.,這樣一套流程下來,Are developers too big?,為什麼呢 The work is tedious and the development efficiency is too low,So is there a better simple solution?? 還真有,推薦使用Facebook開源的Hive
Hive是什麼呢? 其實就是針對MapReduce進行了二次封裝,It is convenient for developers to use familiarSQLScripts and convenient operationHadoop集群上的數據,The basic workflow is developers write to manipulate the data in the first placeSQL,Next connectHive,然後Hivewill write youSQL轉為MapReduce任務,Finally these tasks will beHadoop集群上運行,具體流程如下: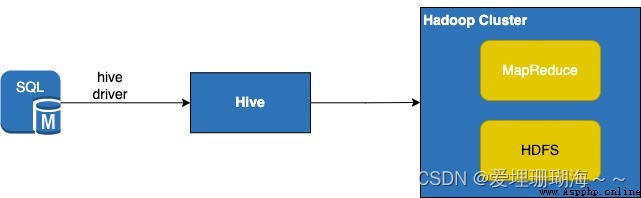
This article mainly introduces the use ofpython開發語言實現,Other languages can refer to the corresponding officialAPI文檔
基於此,我們首先需要安裝Hive的環境,Secondly, the client code needs to be importedhive驅動包
安裝HiveThe environment is not covered in this article,This article focuses on how the client code implements the operationhive的流程
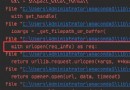
引入hive包
$pip3 install pyhive
from pyhive import hive
class HiveUtils:
def query_count_data(self,query_count_sql,sql_config):
''' The total number of statistics in the table '''
logger.info('query_sql:%s',query_count_sql)
hive_conn = self.__get_connection(sql_config)
hive_cursor = hive_conn.cursor()
hive_cursor.execute(query_count_sql)
list_res = hive_cursor.fetchall()
total_count = list_res[0][0]
logger.info('get total_count:%s',total_count)
hive_cursor.close()
hive_conn.close()
return total_count
@retry(stop=stop_after_attempt(5), wait=wait_fixed(10))
def __get_connection(self,sql_config):
''' Retry if unable to connect5次,delay per retry10秒 '''
logger.info('start to connect to hive ...')
hive_connection = hive.Connection(host=sql_config.host
, port=sql_config.port
, username=sql_config.user_name
, database=sql_config.db_name)
logger.info('connect to hive successful!')
return hive_connection