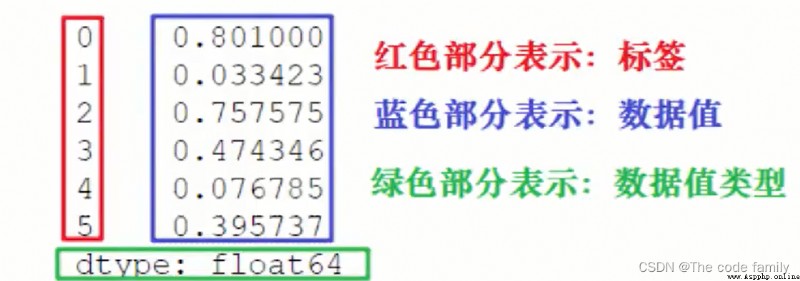
(2)標簽不是唯一的,但必須是可哈希類型。該對象既支持基於整數的索引,也支持基於標簽的索引,並提供了許多方法來執行涉及索引的操作。ndarray的統計方法已被覆蓋,以自動排除缺失的數據(目前表示為NaN)
(3)Series可以保存任何數據類型,比如整數、字符串、浮點數、Python對象等,它的標簽默認為整數,從0開始依次遞增。Series的結構圖如下所示:
pd.Series(data=None,index=None,dtype=None,name=None,copy=False)


通過index和values屬性取得對應的標簽和值


通過索引取得對應的值,或者修改對應的值

和列表索引的區別

通過index和values屬性取得對應的標簽和值

通過索引取得對應的值,或者修改對應的值
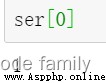 (通過下標獲取)
(通過下標獲取)

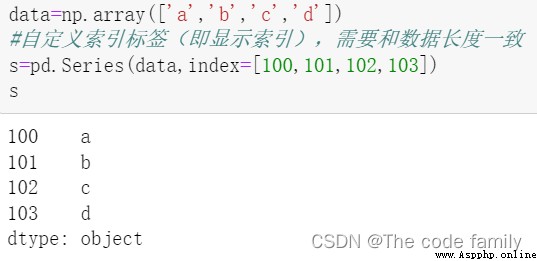
使用“顯式索引”的方法定義索引標簽
從指定索引的字典構造序列

當傳遞的索引值未匹配對應的字典鍵時,使用NaN(非數字)填充

注:索引是首先使用字典中的健構建的,在此之後,用給定的索引值對序列重新編制索引,因此我們得到所有NaN
通過匹配的索引值,改變創建Series數據的順序


如果用於形成數據幀,序列的名稱將成為其索引或列名,每當使用解釋器顯示序列時,也會使用它
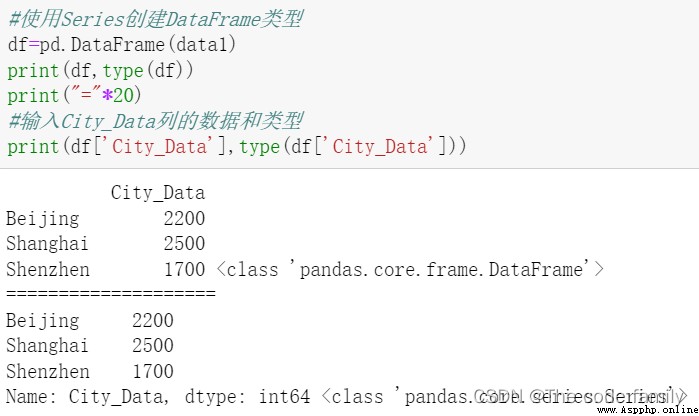
4.Series的索引:
(1)下標索引:類似於列表索引
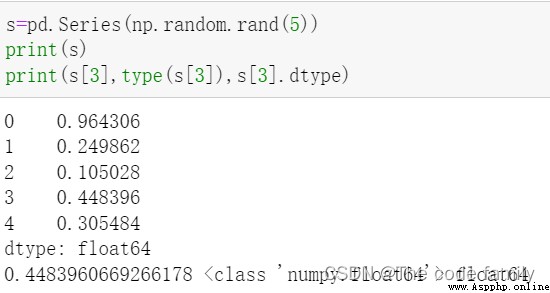
注:①上面的位置索引和標簽索引剛好一致,會使用標簽索引
②當使用負值時,實際並不存在負數的標簽索引
(2)標簽索引:當索引為object類型時,既可以使用標簽索引也可以使用位置索引。Series類似於固定大小的dict,把index中的索引標簽當作key,而把Series序列中的元素值當做value,然後通過index索引標簽來訪問或者修改元素值
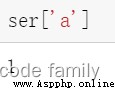
使用索標簽訪問單個元素值:

使用索引標簽訪問多個元素值:
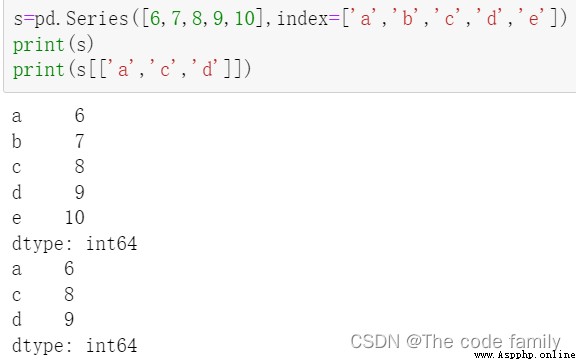
多標簽會創建一個新的數組: