MNN的文檔有中文
https://www.yuque.com/mnn/cn/about
除了部分細節, 按照文檔基本沒啥問題,本文部分內容基本也是拆解文檔
目前windows支持的Python版本:3.5、3.6、3.7,用的時候再去這裡確認下吧
https://www.yuque.com/mnn/cn/usage_in_python
安裝很簡單,直接pip就好
pip install -U pip -i https://mirror.baidu.com/pypi/simple
pip install -U MNN -i https://mirror.baidu.com/pypi/simple
安裝完畢之後,在命令行輸入
> mnn
mnn toolsets has following command line tools
$mnn
list out mnn commands
$mnnconvert
convert other model to mnn model
$mnnquant
quantize mnn model
這就安裝成功了mnnconvert 是用來做模型轉化,mnnquant 量化工具
按理說,安裝完畢之後,命令行會有:
> mnnconvert
Usage:
MNNConvert [OPTION...]
-h, --help Convert Other Model Format To MNN Model
-v, --version show current version
-f, --framework arg model type, ex: [TF,CAFFE,ONNX,TFLITE,MNN]
--modelFile arg tensorflow Pb or caffeModel, ex:
*.pb,*caffemodel
--batch arg if model input's batch is not set, set as the batch size you set --keepInputFormat keep input dimension format or not, default: false --optimizeLevel arg graph optimize option, 0: don't run
optimize(only support for MNN source), 1: use graph
optimize only for every input case is right, 2:
normally right but some case may be wrong,
default 1
--optimizePrefer arg graph optimize option, 0 for normal, 1 for
smalleset, 2 for fastest
--prototxt arg only used for caffe, ex: *.prototxt
--MNNModel arg MNN model, ex: *.mnn
--fp16 save Conv's weight/bias in half_float data type --benchmarkModel Do NOT save big size data, such as Conv's
weight,BN's gamma,beta,mean and variance etc.
Only used to test the cost of the model
--bizCode arg MNN Model Flag, ex: MNN
--debug Enable debugging mode.
--forTraining whether or not to save training ops BN and
Dropout, default: false
--weightQuantBits arg save conv/matmul/LSTM float weights to int8
type, only optimize for model size, 2-8 bits,
default: 0, which means no weight quant
--weightQuantAsymmetric the default weight-quant uses SYMMETRIC quant
method, which is compatible with old MNN
versions. you can try set --weightQuantAsymmetric
to use asymmetric quant method to improve
accuracy of the weight-quant model in some cases,
but asymmetric quant model cannot run on old
MNN versions. You will need to upgrade MNN to
new version to solve this problem. default:
false
--compressionParamsFile arg
The path of the compression parameters that
stores activation, weight scales and zero
points for quantization or information for
sparsity.
--OP print framework supported op
--saveStaticModel save static model with fix shape, default:
false
--targetVersion arg compability for old mnn engine, default: 1.2f
--customOpLibs arg custom op libs ex: libmy_add.so;libmy_sub.so
--authCode arg code for model authentication.
--inputConfigFile arg set input config file for static model, ex:
~/config.txt
--alignDenormalizedValue arg
if 1, converter would align denormalized
float(|x| < 1.18e-38) as zero, because of in
ubuntu/protobuf or android/flatbuf, system
behaviors are different. default: 1, range: {
0, 1}
[10:15:46] @ 192: framework Invalid, use -f CAFFE/MNN/ONNX/TFLITE/TORCH !
如果命令行不能用,可以參考這個:
https://www.yuque.com/mnn/cn/usage_in_python
python(3) -m MNN.tools.mnn
python(3) -m MNN.tools.mnnconvert
python(3) -m MNN.tools.mnnquant
這裡轉化一下,將onnx轉換為mnn模型
MNNConvert -f ONNX --modelFile output.onnx --MNNModel output.mnn --bizCode biz
加上 --fp 可以轉換為半精度的模型,模型的大小比例近乎縮小一半:
MNNConvert -f ONNX --modelFile output.onnx --MNNModel output16.mnn --bizCode biz --fp
半精度轉換文檔在這裡:
https://www.yuque.com/mnn/cn/qxtz32
這個之前沒怎麼用過,直接copy一下官方文檔:
將模型中卷積的float權值量化為int8存儲,推理時反量化還原為float權值進行計算。因此,其推理速度和float模型一致,但是模型大小可以減小到原來的1/4,可以通過模型轉換工具一鍵完成,比較方便。推薦float模型性能夠用,僅需要減少模型大小的場景使用。
使用MNNConvert.exe(c++)或者mnnconvert(python包中自帶)進行轉換,轉換命令行中加上下述選項即可:
--weightQuantBits 8 [--weightQuantAsymmetric](可選)
--weightQuantAsymmetric 選項是指使用非對稱量化方法,精度要比默認的對稱量化精度好一些。
以上是直接用Python 命令行工具轉換的,接下來是,編譯轉換工具的過程:
注意:實驗證明,Python命令行工具mnnconvert 與 編譯的轉換工具MNNConvert.exe 效果相同,當然,可能在後續大版本有些不同
編譯前需要 ninja, cmake 和 VS2017/2019
cmake安裝:
https://blog.csdn.net/HaoZiHuang/article/details/126015717
ninja 安裝:
https://blog.csdn.net/HaoZiHuang/article/details/126083356
(ninja 是構建工具,比nmake更快)
安裝VS之後,在編譯過程中,命令行用x64 Native Tools Command Prompt 就好
編譯具體過程參考文檔:
https://www.yuque.com/mnn/cn/cvrt_windows
把 MNN git 下來,然後
cd MNN
mkdir build
cd build
cmake -G "Ninja" -DMNN_BUILD_SHARED_LIBS=OFF -DMNN_BUILD_CONVERTER=ON -DCMAKE_BUILD_TYPE=Release -DMNN_WIN_RUNTIME_MT=ON ..
ninja
之後會在目錄下生成:MNNConvert.exe 該工具就是轉換工具
官方文檔在:
https://www.yuque.com/mnn/cn/build_windows
由於編譯後的引擎在當前版本無法被Python調用,所以如果不用C++,該部分直接跳過不用看
下載GPU Caps Viewer,你可以通過這個工具來查看本機設備的詳細信息(opencl、opengl、vulkan等)
在Github上有個issue:
編譯的引擎如何用Python API調用:https://github.com/alibaba/MNN/issues/2010
官方回復是需要編譯 pymnn, 目前文檔還沒出來,等官方更新吧
同時編譯的時候需要 powershell
同時依舊需要VS的命令行x64 Native Tools Command Prompt
cd /path/to/MNN
powershell # 運行該命令從 cmd 環境進入 powershell 環境,後者功能更強大
./schema/generate.ps1
如果只需要 CPU 後端
# CPU, 64位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU/lib/x64
# CPU, 32位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU/lib/x86
如果需要 opencl 和 vulkan 後端
# CPU+OpenCL+Vulkan, 64位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU-OPENCL/lib/x64 -backends "opencl,vulkan"
# CPU+OpenCL+Vulkan, 32位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU-OPENCL/lib/x86 -backends "opencl,vulkan"
如果僅需要 opencl 後端
# CPU+OpenCL, 64位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU-OPENCL/lib/x64 -backends opencl
# CPU+OpenCL, 32位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU-OPENCL/lib/x86 -backends opencl
如果僅需要 vulkan 後端
# CPU+Vulkan, 64位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU-OPENCL/lib/x64 -backends vulkan
# CPU+Vulkan, 32位編譯
.\package_scripts\win\build_lib.ps1 -path MNN-CPU-OPENCL/lib/x86 -backends vulkan
具體都可以參考這些:
https://www.yuque.com/mnn/cn/build_windows
測試圖片shiyuan.jpg:
結果圖片: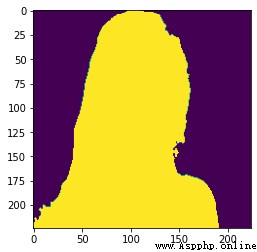
測試的mnn模型在這裡下載:
https://download.csdn.net/download/HaoZiHuang/86337543
import numpy as np
import MNN
import cv2
import matplotlib.pyplot as plt
def normalize(im,
mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5)):
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
return im
if __name__ == "__main__":
""" inference PPliteSeg using a specific picture """
img = "shiyuan.jpg"
interpreter = MNN.Interpreter("originalpool/output.mnn") # custompool originalpool
session = interpreter.createSession()
input_tensor = interpreter.getSessionInput(session)
image = cv2.imread(img)
image = cv2.resize(image, (224, 224))
image = normalize(image)
image = image.transpose((2, 0, 1))
image = image.astype(np.float32)
tmp_input = MNN.Tensor((1, 3, 224, 224),
MNN.Halide_Type_Float,
image,
MNN.Tensor_DimensionType_Caffe)
input_tensor.copyFrom(tmp_input)
interpreter.runSession(session)
output_tensor = interpreter.getSessionOutput(session)
tmp_output = MNN.Tensor((1, 2, 224, 224),
MNN.Halide_Type_Float,
np.ones([1, 2, 224, 224]).astype(np.float32),
MNN.Tensor_DimensionType_Caffe)
output_tensor.copyToHostTensor(tmp_output)
res = tmp_output.getNumpyData()[0]
res = res.argmax(axis=0)
plt.imshow(res)
plt.show()
如果你自己的結果出現全1或者結果不對,可能就是我遇到的問題:
我的mnn模型是onnx模型導出來的,之前出現全1的結果,多次嘗試發現,我的onnx模型輸入是動態的,不是靜態,所以出現這個問題
如果也是這個 onnx -> mnn 的情況,用下邊兒這個腳本看看,是否是動態輸入:
https://blog.csdn.net/HaoZiHuang/article/details/126168132
如果是動態輸入,嘗試將onnx模型修改為靜態輸入試試,如果四 Paddle模型轉onnx模型,在Paddle2onnx工具後加添加 --input_shape_dict "{'x':[1,3,224,224]}"
Paddle2onnx工具命令使用指南在這裡:
https://github.com/PaddlePaddle/Paddle2ONNX#命令行轉換
本來的結果圖: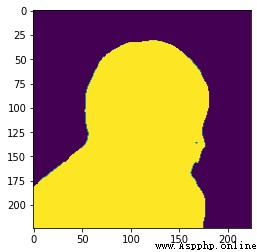
結果是醬紫: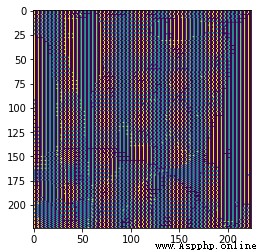
可以參考該文章:
https://blog.csdn.net/HaoZiHuang/article/details/126136436