##################################################
目錄
活動簡介
詳解 字典/列表/元組
The three most common types of data
元組
列表
字典
Depending on the type of data judgment bracket
Why must add escape characters escape
Simple contact Python 正則表達式
匹配單個字符
符號 ./點 的用法
符號 []/或 的用法
符號 %d/匹配數字 的用法
匹配多個字符
符號 */Before a character appears at least zero 用法
符號 +/At least once before a character appears 用法
符號 ?/A character must appear before a or not 用法
符號 m/On a character appeared m 次 用法
匹配開頭結尾
符號 ^/匹配字符串開頭 用法
符號 $/匹配字符串結尾 用法
分組匹配
符號 |/兩項都匹配 用法
符號 ()/In parentheses is a group 用法
##################################################
活動地址:CSDN21天學習挑戰賽
學習的最大理由是想擺脫平庸,早一天就多一份人生的精彩;遲一天就多一天平庸的困擾;一個人摸索學習很難堅持,想組團高效學習;想寫博客但無從下手,急需寫作干貨注入能量;熱愛寫作,願意讓自己成為更好的人…
…
歡迎參與CSDN學習挑戰賽,成為更好的自己,請參考活動中各位優質專欄博主的免費高質量專欄資源(這部分優質資源是活動限時免費開放喔~),按照自身的學習領域和學習進度學習並記錄自己的學習過程,或者按照自己的理解發布專欄學習作品!
##################################################
——————————
Python 主要有三種數據類型 字典、列表、元組
Its respectively represented by the following
Curly braces dictionary
Brackets list
Parentheses tuples
示例:
dic = { 'a':12, 'b':34 } /* 字典 */
list = [ 1, 2, 3, 4 ] /* 列表 */
tup = ( 1, 2, 3, 4 ) /* 元組 */%%%%%
小括號 () 代表 tuple/元組 數據類型
元組是一種不可變序列
Its creation method is very simple 大多時候都是用小括號括起來的 示例:
Microsoft Windows [版本 6.3.9600]
(c) 2013 Microsoft Corporation.保留所有權利.
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> tup = ( 1, 2, 3 ) /* 創建一個元組 */
>>> tup
(1, 2, 3)
>>> type ( tup )
<class 'tuple'>
>>> () /* 空元組 */
()
>>> 55, /* 一個值的元組 */
(55,)
>>> %%%%%
中括號 [] 代表 list/列表 數據類型
列表是一種可變的序列
其創建方法即簡單又特別:
>>> list ( "Python" )
['P', 'y', 't', 'h', 'o', 'n']
>>> %%%%%
大括號 {} 花括號 代表 dict 字典數據類型
字典是由鍵對值組組成
冒號分開 鍵 和 值
逗號隔開 組
示例:
>>> dic = { "崽崽":"女", "仔仔":"男" }
>>> dic
{'仔仔': '男', '崽崽': '女'}
>>> %%%%%
Python 語言最常見的括號有三種 分別是
小括號 ()
中括號 []
Braces are also called curly braces {}
其作用也各不相同 分別用來代表不同的 Python 基本內置數據類型
——————————
看下面這個例子:
re.findall() Function can traverse the match to obtain all the matching strings in the returned string is a list
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.findall ( r"\.", "\." )
['.']
>>> 可以看出加上
\This escape symbol
\.To say a point:
.##################################################
——————————
%%%%%
Some said one character at a time 具體演示請看:
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re /* 導入正則表達式模塊 */
>>>
>>> r = re.match ( "", "崽" ) /* match Method from the beginning of the scan 第一個參數是規則 第二個參數是目標文本 */
>>> r.group() /* group Extract the said packet intercepted character On a code without matching rules so nothing to extract */
''
>>> r = re.match ( ".", "Like zai zai" ) /* 匹配規則為 提取第一個字符 */
>>> r.group() /* View on one line of code that intercepted the character */
'喜'
>>> r = re.match ( "喜.崽", "Like zai zai" ) /* 提取 '喜' 和 '崽' Between the characters */
>>> r.group() /* 查看提取結果 */
'Usually like to'
>>> 為什麼一定要用 group 方法
group() The output is actually match
演示:
>>> r = re.match ( ".", "Zai zai pups" )
>>> r.group()
'崽'
>>> r /* 可以看到如下信息 span 表示范圍 match Said to extract characters */
<re.Match object; span=(0, 1), match='崽'>
>>> r = re.match ( "喜.崽", "Like zai zai" )
>>> r
<re.Match object; span=(0, 3), match='Usually like to'>
>>> %%%%%
如下:
>>> r = re.match ( "A", "abc" ) /* Matching conditions is capital The target text is lower case */
>>> r.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> r = re.match ( "A", "Abc" ) /* If the condition is a capital letter The target must be capital letters */
>>> r.group()
'A'
>>> r = re.match ( "a", "abc" ) /* If the condition is lower case Goals must be lower case */
>>> r.group()
'a'
>>> The first character is uppercase or lowercase can be:
>>> r = re.match ( "[aA]", "aAbc" )
>>> r.group()
'a'
>>> r = re.match ( "[aA]", "Abc" )
>>> r.group()
'A'
>>> Is whether the first character is [] 中的:
>>> r = re.match ( "[我你]", "我愛你" )
>>> r.group()
'我'
>>> r = re.match ( "[我你]", "你愛我" )
>>> r.group()
'你'
>>> r = re.match ( "[我你]", "她愛他" )
>>> r.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> Of course you can also specify the range In digital sample here You also can test the letters 一樣的 Only the points case:
>>> r = re.match ( "一共有[0123456789]A hole teammates", "一共有4A hole teammates" )
>>> r.group()
'一共有4A hole teammates'
>>> r = re.match ( "一共有[0-9]A hole teammates", "一共有4A hole teammates" )
>>> r.group()
'一共有4A hole teammates'
>>> r = re.match ( "一共有[035-9]A hole teammates", "一共有4A hole teammates" ) /* But can't match Numbers 4 此時 r 為 None */
>>> r.group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> %%%%%
Is the match Numbers:
>>> r = re.match ( "有\dA zai zai", "有1A zai zai!" )
>>> r.group()
'有1A zai zai'
>>> r = re.match ( "有\dA zai zai", "有2A zai zai!" )
>>> r.group()
'有2A zai zai'
>>> ——————————
%%%%%
匹配規則為:
[A-Z] Said the string for the first letters capitalized
[a-z] Said the letter must be behind the lower case
* Said in a letter could be zero or many times
>>> r = re.match ( "[A-Z][a-z]*", "G" )
>>> r.group()
'G'
>>> r = re.match ( "[A-Z][a-z]*", "GgFuck" )
>>> r.group()
'Gg'
>>> r = re.match ( "[A-Z][a-z]*", "Ggfuck" )
>>> r.group()
'Ggfuck'
>>> %%%%%
According to whether the string in
[a-zA-Z_]+[\w]規則:
Before a letter must be
或小寫的
Or capital
或者是下劃線
And must appear at least once
test.py code:
This script will not comment If you can read about logic Is very suitable for you to write program!!!
import re
strS = [ "str1", "_str", "2_str", "__str__" ]
for str in strS:
r = re.match ( "[a-zA-Z_]+[\w]", str )
if r:
print ( "字符串 %s 符合要求!" % r.group () )
else:
print ( "字符串 %s 是非法的.." % str )VSCode demo:
Windows PowerShell
版權所有 (C) 2014 Microsoft Corporation.保留所有權利.
PS C:\Users\byme> python -u "e:\PY\test.py"
字符串 str1 符合要求!
字符串 _str 符合要求!
字符串 2_str 是非法的..
字符串 __str__ 符合要求!
PS C:\Users\byme> 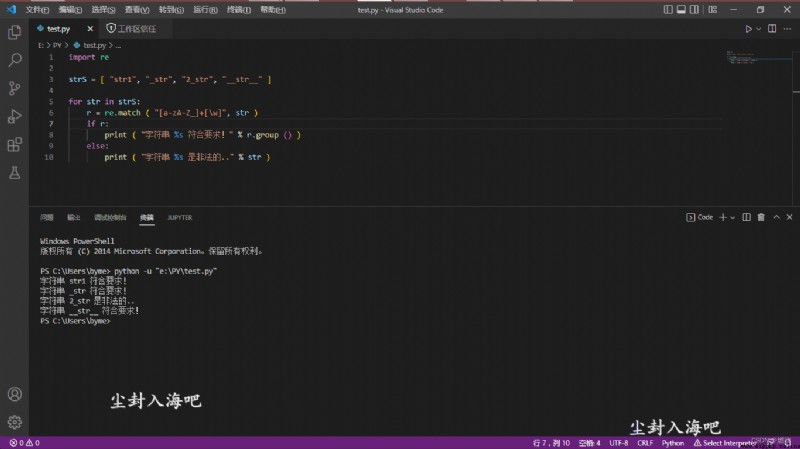
%%%%%
示例 匹配出 0 到 99 之間的數字:
>>> r = re.match ( "[1-9]?[0-9]", "5" )
>>> r.group ()
'5'
>>> r = re.match ( "[1-9]?\d", "52" )
>>> r.group ()
'52'
>>> %%%%%
Match the former 8 密碼 Can be a case of English letters and Numbers:
>>> r = re.match ( "[a-zA-Z0-9]{8}", "82s4h12452" )
>>> r.group ()
'82s4h124'
>>> Match the former 6 到 15 位的密碼 可以是大小寫英文字母、數字、下劃線 示例:
>>> r = re.match ( "[a-zA-Z0-9_]{6,15}", "3sa43t65C23656Xp09" )
>>> r.group ()
'3sa43t65C23656X'
>>> ——————————
%%%%%
匹配以 139 開頭的電話號碼 示例:
>>> r = re.match ( "^139[0-9]{8}", "13968576141" ) /* 開頭必須是 139 One is behind the Numbers 而 {8} Said the number can reappear (8-1) 次 */
>>> r.group ()
'13968576141'
>>> r = re.match ( "^139[0-9]{8}", "15968576141" ) /* Wrong beginning will not capture */
>>> r.group ()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
>>> %%%%%
匹配輸出 163 的郵箱地址 而且 @ 符號之前有 6 到 15 位
例如
[email protected]test.py code:
import re
email_S = { "[email protected]", "[email protected]", "[email protected]" }
for email in email_S:
r = re.match ( "[\w]{6,15}@163\.com$", email )
if r:
print ( "[%s] Is a legitimate email address,匹配後的結果為 >>> [%s]" % ( email, r.group() ) )
else:
print ( "[%s] 非法!" % email )VSCode demo:
Windows PowerShell
版權所有 (C) 2014 Microsoft Corporation.保留所有權利.
PS C:\Users\byme> python -u "e:\PY\test.py"
[[email protected]] 非法!
[[email protected]] Is a legitimate email address,匹配後的結果為 >>> [[email protected]]
[[email protected]] 非法!
PS C:\Users\byme> 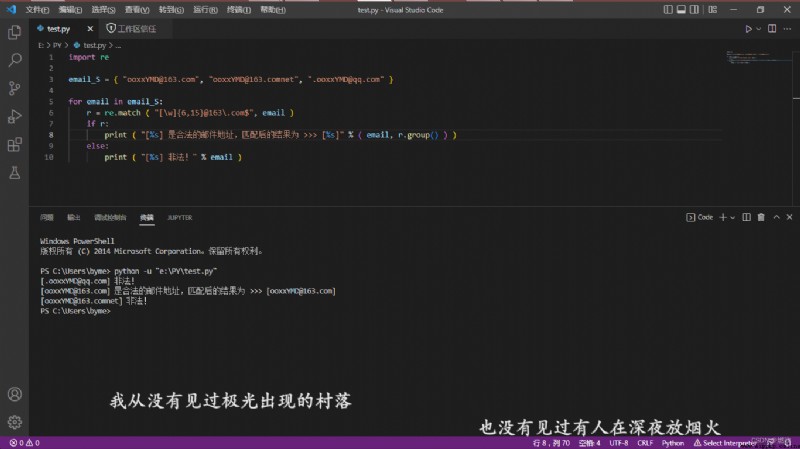
——————————
%%%%%
匹配出 0~100 之間的數字!
>>> r = re.match ( "[1-9]?\d", "0" )
>>> r.group()
'0'
>>> r = re.match ( "[1-9]?\d", "52" )
>>> r.group()
'52'
>>> r = re.match ( "[1-9]?\d", "02" ) /* 這樣不對啊 */
>>> r.group()
'0'
>>>
You can also write a script in the interactive mode:
>>> import re
>>> r = re.match ( "[1-9]?\d$", "02" )
>>> if r: /* 冒號!!! */
... print ( r.group () ) /* 可用 TAB 縮進 */
... else:
... print ( "不在 0~100 之間.." )
...
不在 0~100 之間..
>>> 使用 | 符號:
>>> r = re.match ( "[1-9]?\d$|100", "52" )
>>> r.group()
'52'
>>> r = re.match ( "[1-9]?\d$|100", "100" )
>>> r.group()
'100'
>>> %%%%%
示例匹配 163、126、qq 郵箱:
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>>
>>> r = re.match ( "\w{6,15}@163\.com", "[email protected]" )
>>> r.group ()
'[email protected]'
>>>
>>> r = re.match ( "\w{6,15}@(163|126|qq)\.com", "[email protected]" )
>>> r.group ()
'[email protected]'
>>>
>>> r = re.match ( "\w{6,15}@(163|126|qq)\.com", "[email protected]" )
>>> r.group ()
'[email protected]'
>>>
>>> r = re.match ( "\w{6,15}@163\.com", "[email protected]" )
>>> if r:
... print ( r.group () )
... else:
... print ( "Not below email >>> [163|126|qq] ..!" )
...
Not below email >>> [163|126|qq] ..!
>>> 不是以 4、7 結尾的 11 位手機號碼:
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
tels = ["73834629344", "19488342830", "18611", "99999999987"]
for tel in tels:
ret = re.match ( "1\d{9}[0-35-68-9]", tel )
if ret:
print ( ret.group () )
else:
print ( ">>> [%s] 不是想要的手機號" % tel )VSCode demo:
Windows PowerShell
版權所有 (C) 2014 Microsoft Corporation.保留所有權利.
PS C:\Users\byme> python -u "e:\PY\test.py"
>>> [73834629344] 不是想要的手機號
19488342830
>>> [18611] 不是想要的手機號
>>> [99999999987] 不是想要的手機號
PS C:\Users\byme> 提取區號和電話號碼 示例:
C:\Users\byme>python
Python 3.10.5 (tags/v3.10.5:f377153, Jun 6 2022, 16:14:13) [MSC v.1929 64 bit (
AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>>
>>> r = re.match ( "([^-]*)-(\d+)", "131-12345678" )
>>> r.group ()
'131-12345678'
>>> r.group ( 1 )
'131'
>>> r.group(2)
'12345678'
>>>