本博文是在學習吳茂貴等人的書籍《Python深度學習基於Pytorch》(英文名為《Deep Learning with Python and Pytorch》)的時候,記錄下來的一些筆記,還有版本更新時候可能會出現的問題。
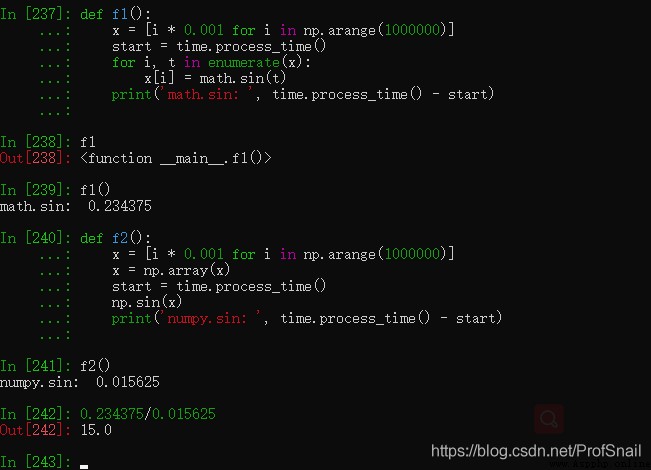
書中第18頁,1.6節通用函數,1.math與numpy函數的性能比較。這裡計時用到的函數是time.clock()記錄開始和結束時間,並以此作為估計。不過會出現這樣的提示DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead,意思是說在3.8版本之後time.clock將會消失,所以使用time.process_time()加以替換即可。 在按照書中25頁資料(第2.2.2節),使用conda安裝pytorch的時候,安裝過程中會遇到無法找到名為conda的module,當錯誤發生之後,原本的conda環境也無法使用。這個問題似乎是因為如果默認在base環境下面安裝pytorch的時候,會覆蓋本機的python包,導致版本號不符。解決方案是使用rm -rf ./anaconda3,先把anaconda環境完全卸載掉(因為已經不知道anaconda內部到底哪裡出現了問題,只能完全暴力卸載了)。conda create pytorchenv python=3.7專門創建一個安裝pytorch環境的conda環境。並切換環境conda activate pytorchenv,在這個環境中安裝torch即可conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c nvidia。 書中27頁(第2.3節),配置本機訪問服務器Jupyter Notebook的時候,遇到了本機和電腦服務器無法連接的問題。原因可能是服務器的防火牆開啟,需要在本機和服務器之間建立一個ssh安全連接。ssh安全連接指令為ssh 服務器的用戶名@服務器IP -L 127.0.0.1:1234:127.0.0.1:8888 -p 端口號 書中46頁(第2.8節),嘗試使用Tensorflow進行復現的時候,發現tensorflow裡面沒有placeholder這個模塊。原因是使用conda install tensorflow默認安裝的是tensorflow 2.4版本的內容,而placeholder占位符是tensorflow 版本1的內容了。解決方案是: import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
繪圖的時候,如果不希望添加橫坐標和縱坐標的數值的話,可以使用plt.xticks([])來禁用。 繪圖的時候,可以在繪制某幅圖像的時候,plt.scatter(x, y, label='something')直接添加label。而不必在這之後另外繪制。 當使用datasets.ImageFolder(路徑名)的時候,系統會將該文件夾下面的所有圖片,按照文件夾進行分類和貼標簽,只需要將一類文件/圖片放到同一個文件夾下面,就可以使用datasets.ImageFolder批量構建文件數據集合了。 下面簡單介紹一下如何使用本地浏覽器,查看服務器端的tensorboard可視化樣例。 如果想要刪除tensorboard中的某些圖像,需要點開剛剛的logs文件夾,刪除對應的標簽文件。只有重啟tensorboard服務之後,才能發現這幅圖像已經被刪除了。 有一個疑問,是關於歸一化問題的。在訓練過程中會減去平均值和除以標准差,減去的應該是訓練數據集的平均值和標准差。在測試階段以及評估階段,應該也需要減去平均值和除以標准差,這個時候應該用誰的均值和標准差呢?訓練集的平均值和標准差,還是測試集的平均值和標准差呢? #對訓練數據進行標准化
mean=X_train.mean(axis=0)
std=X_train.std(axis=0)
X_train-=mean
X_train/=std
X_test-=mean
X_test/=std
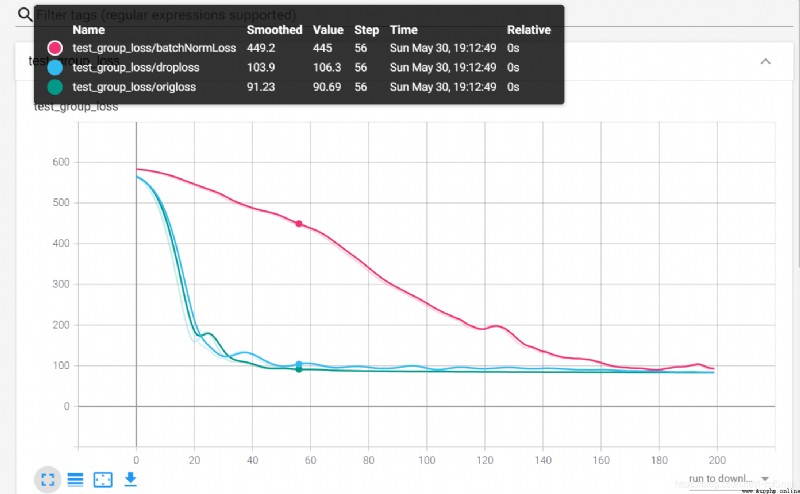
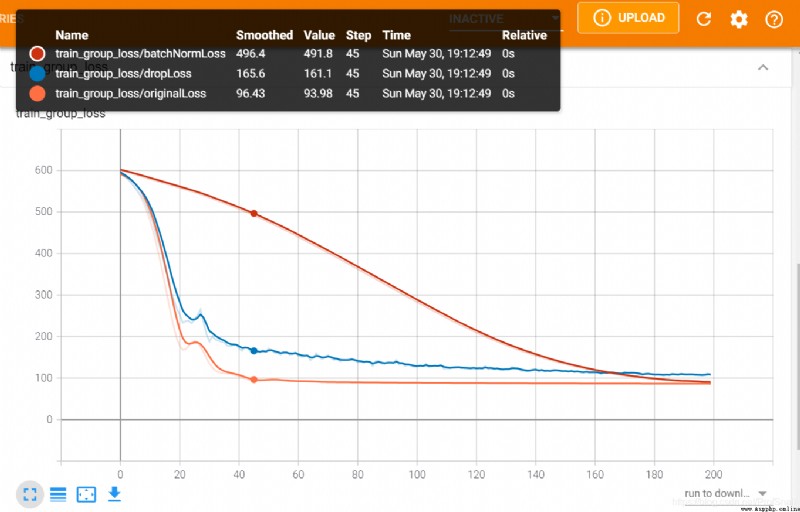
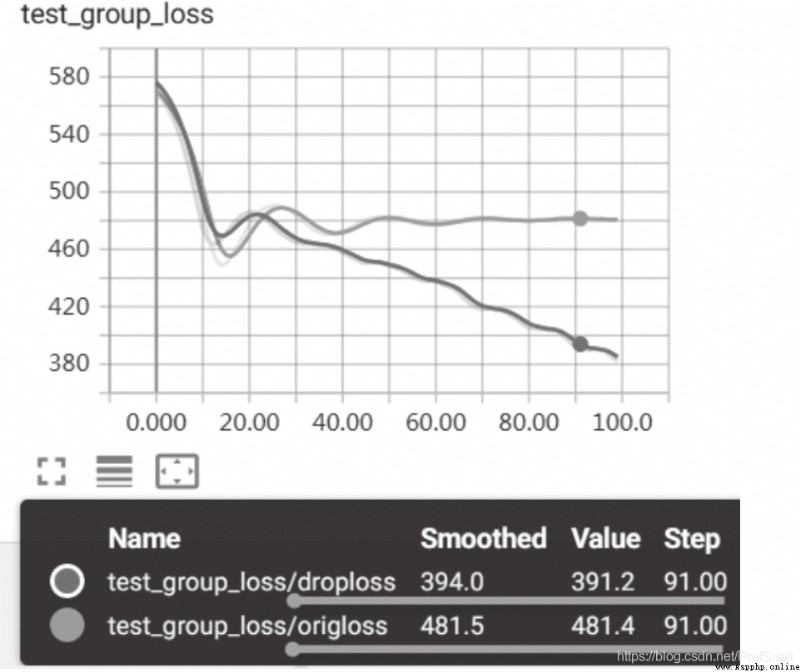
在書中86頁的地方,做了一個批量正則化、批量隨機置零的操作,用來表明使用這些方法會對泛化的特性有所提高。但是經過我的實際驗證,發現使用了這些方法之後,損失函數下降的速度變慢了。不知道這是否與書中所介紹的內容所一致。