OCR,全稱Optical Character Recognition ,中文釋義為光學字符識別,是指對一個包含文本信息的圖片文件的識別,目前比較流行的OCR有tesseractOCR和cnOCR,在這篇文章中我們使用識別效果較好的tesseractOCR。
首先我們要安裝tesseract,到這個網址下載:
Home · UB-Mannheim/tesseract Wiki (github.com)
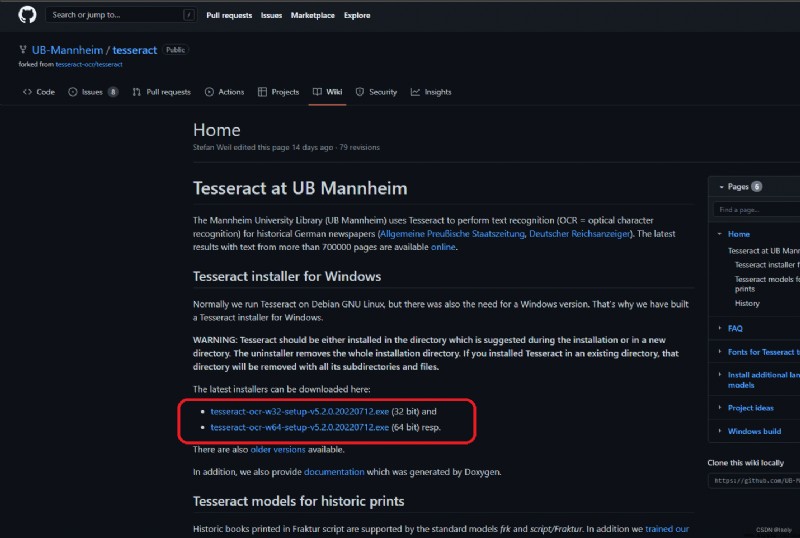
自己按照電腦的位數選擇安裝包,下載下來。
下載下來後,打開安裝包。
選擇語言,沒有中文,只好選英文。
然後一直next,但是注意!在安裝語言時這個Additional lauguage data千萬不要全選,要不然下載過程特別慢,如果需要的話,只安裝裡面的 Chinese組件就行了。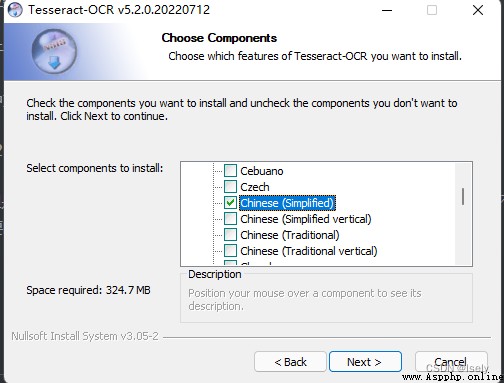
接下來就比較簡單了。
安裝完成後我們還得添加環境變量,打開自己安裝tesseract的文件夾,復制路徑,在右鍵此電腦,選擇屬性,打開高級系統設置,打開環境變量,打開用戶變量的Path,新建變量,把復制的路徑粘貼進去,點確定就行了,可以通過cmd輸入 tesseract -v 再回車,如果出現了tesseract的版本信息就說明配置成功了。
然後為了在python中使用tesseract,我們需要安裝pytesseract,直接在cmd中用pip安裝就好了:
pip install pytesseract
(無視裡面的黃色字體,是我電腦的問題,對安裝什麼的沒有影響)
打開python編輯器,把這段代碼復制進去:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'D://Tesseract-OCR//tesseract.exe' # 替換成你自己的tesseract安裝路徑
text = pytesseract.image_to_string(Image.open('D://input.png')) # 替換成要識別的圖片路徑
print(text)
這是我要識別的圖片:
運行後輸出為 Hello world ,識別率很高。
怎麼樣,好玩吧?不僅這樣,tesseract還可以識別中文!只不過得安裝相應的庫,這是下載鏈接:
https://github.com/tesseract-ocr/tessdata/blob/main/chi_sim.traineddata
下載下來中文訓練包後,把包放到tessdata中就可以識別中文了。