OCR, the full name of Optical Character Recognition, the Chinese interpretation is Optical Character Recognition, which refers to the recognition of a picture file containing text information. At present, the more popular OCRs are tesseractOCR and cnOCR. In this article, we use the recognition effect to compareGood tesseractOCR.
First we have to install tesseract and download it from this URL:
Home · UB-Mannheim/tesseract Wiki (github.com)
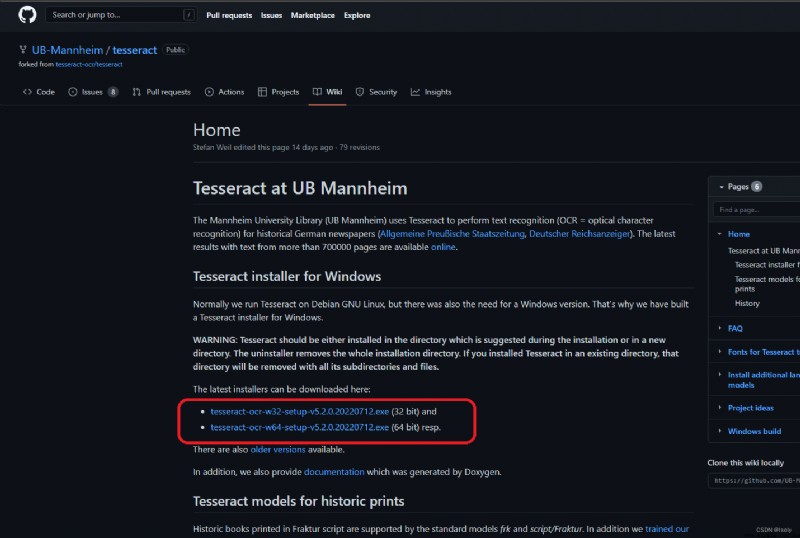
Select the installation package according to the number of digits of the computer and download it.
After downloading, open the installation package.
Choose the language. There is no Chinese, so I have to choose English.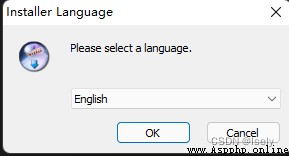
Then keep on next, but be careful!When installing the language, do not select all of the Additional lauguage data, otherwise the download process will be very slow. If necessary, only install the Chinese component inside.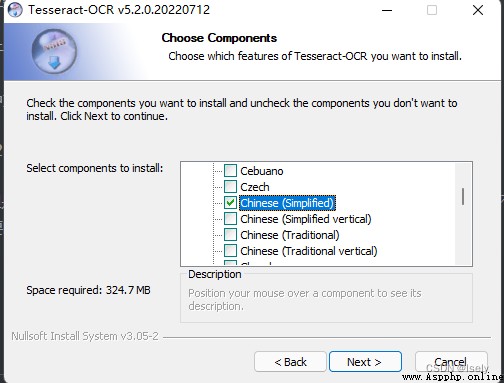
The next step is simpler.
After the installation is complete, we have to add environment variables, open the folder where you installed tesseract, copy the path, right-click the computer, select Properties, open the advanced system settings, open the environment variables, open the Path of the user variable, create a new variable,Paste the copied path into it, and click OK. You can enter tesseract -v through cmd and press Enter. If the version information of tesseract appears, the configuration is successful.
Then in order to use tesseract in python, we need to install pytesseract, just install it directly with pip in cmd:
pip install pytesseract
(Ignore the yellow font inside, it is a problem with my computer, it has no effect on the installation)
Open the python editor and copy this code into it:
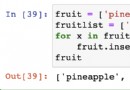
import pytesseractfrom PIL import Imagepytesseract.pytesseract.tesseract_cmd = 'D://Tesseract-OCR//tesseract.exe' # Replace with your own tesseract installation pathtext = pytesseract.image_to_string(Image.open('D://input.png')) # is replaced byImage path to identifyprint(text)This is the image I want to identify:
After running, the output is Hello world, and the recognition rate is very high.
How about it, fun?Not only that, tesseract can also recognize Chinese!Just install the corresponding library, here is the download link:
https://github.com/tesseract-ocr/tessdata/blob/main/chi_sim.traineddata
After downloading the Chinese training package, put the package into tessdata to recognize Chinese.