大家可以關注知乎或微信公眾號的share16,我們也會同步更新此文章.
寫在前面的話
The content of this article is participating’和鯨社區-Breakthrough data analysis‘活動後,A summary of some incorrectly answered questions and related knowledge points,以供大家參考.若有侵權,請及時聯系!
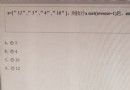
The content involved has a binomial distribution、Hypergeometric distribution, etc.





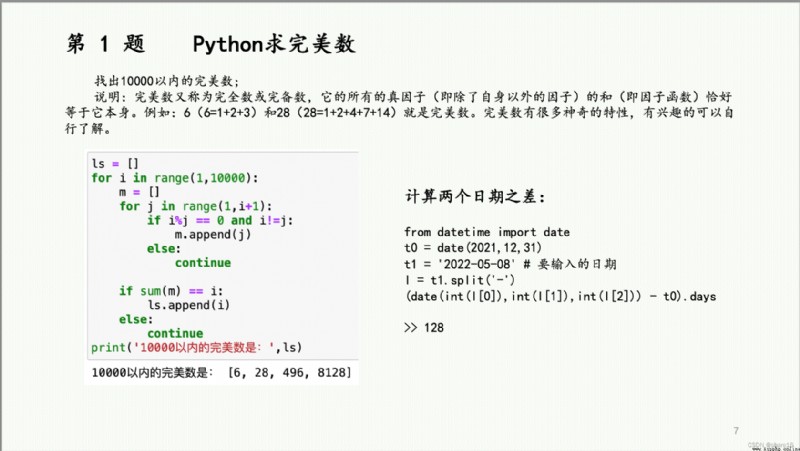
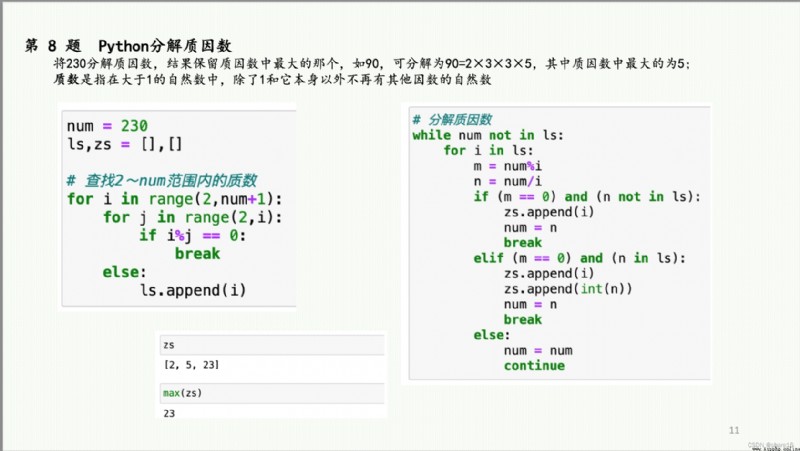
There are perfect numbers of content involved、水仙花數、回文素數、斐波那契數列、Queuing report、分解質因數(Contains the greatest common divisor/最小公倍數)、Series.str.函數、Series.dt.函數、分箱(cut/qcut)等.




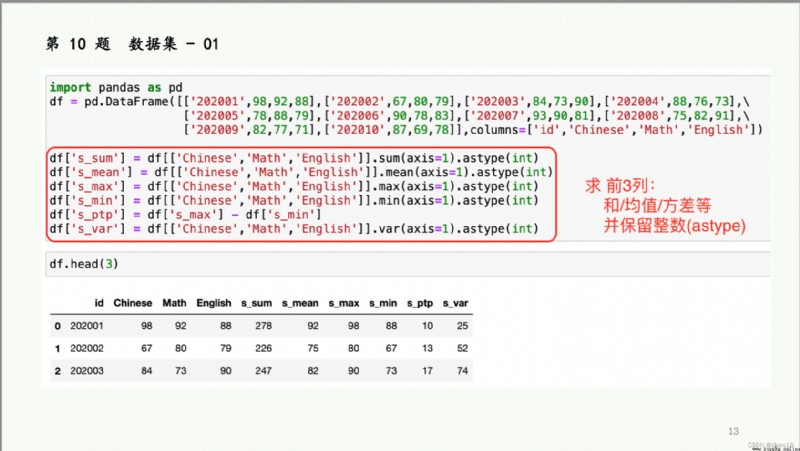




Titanic數據集:點此下載

import pandas as pd
train = pd.read_csv('/xxxxxx/train.csv')
test = pd.read_csv('/xxxxxx/test.csv')
df = pd.concat([train,test])
df.head()
''' 此外,還有merge、join兩種方法'''
''' Embarked : 用眾數填充; Fare : 用均值填充; Cabin : 座位號,用'no-ticket'填充; '''
df.Embarked = df.Embarked.fillna(df.Embarked.mode()[0])
df.Fare = df.Fare.fillna(df.Fare.mean())
df.Cabin = df.Cabin.fillna('no-ticket')
#df.loc[df.Cabin.isna(),'Cabin'] = 'no-ticket'
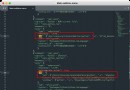
①Fare grading(分箱-分類編碼)
X = df[['PassengerId','Survived','Pclass','Embarked','Name','Cabin','Ticket','Sex','Fare','Age']]
dict_name = {
"Capt":"Officer", "Col":"Officer", "Major":"Officer", "Jonkheer":"Royalty",\
"Don":"Royalty", "Sir" :"Royalty", "Dr":"Officer", "Rev":"Officer", "the Countess":"Royalty",\
"Dona":"Royalty", "Mme":"Mrs", "Mlle":"Miss", "Ms":"Mrs", "Mr" :"Mr", "Mrs" :"Mrs",\
"Miss" :"Miss", "Master" :"Master", "Lady" :"Royalty"}
X['fare_'] = pd.factorize(pd.qcut(X.Fare,5))[0]
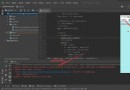
②Name handling-Extract the salutation of the first name
X['name_'] = X.Name.str.split(',').str[1].str.split('.').str[0].str.strip().map(dict_name)
#X['name_'] = X.Name.apply(lambda x:x.split(',')[1].split('.')[0].strip()) # apply也可換成map
X['name_length'] = X.Name.agg(len)
③Cabin處理
# Cabin:no-ticket用0表示,其他用1表示
X['cabin_'] = X.Cabin.apply(lambda x:0 if x == 'no-ticket' else 1)
④Ticket處理(Only keep the letters in it,And convert the letters to numbers)
X['ticket_'] = X.Ticket.str.split().str[0]
X['ticket_'] = pd.factorize(X.ticket_.apply(lambda x:'U0' if x.isnumeric() else x))[0]
⑤對Embarked、Sex及Pclass等等,用dummy處理
X.drop(columns=['PassengerId','Name','Cabin','Ticket','Fare'],axis=1,inplace=True)
x = pd.get_dummies(X,columns=['Pclass','Embarked','Sex','fare_','cabin_','name_'])
''' 預測的是Age,So here is regression '''
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor(n_estimators=1000,n_jobs=-1)
x_train = x[x.Age.notnull()]
x_test = x[x.Age.isnull()]
forest.fit(x_train.iloc[:,2:],x_train.iloc[:,1])
x_test.iloc[:,1] = forest.predict(x_test.iloc[:,2:]).round(1)
x_new = pd.concat([x_train,x_test])
x_new.corr().Survived.abs().sort_values(ascending=False)
謝謝大家