大家可以關注知乎或微信公眾號的share16,我們也會同步更新此文章。
缺失數據可以使用isna或isnull(兩個函數沒有區別)來查看每個單元格是否缺失;
import numpy as np
import pandas as pd
ls = [['A',1,11],['B',np.nan,12],['C',3,np.nan]]
df = pd.DataFrame(ls,columns=['name','x','y'])
print('查看單元格是否缺失:')
print(df.isna(), df.isnull(), sep='\n\n')
print('\n計算每列缺失值的占比:')
print(df.isna().mean(), df.isnull().mean(), sep='\n\n')
print('\n某列 缺失或非缺失的行:')
print(df[df.x.isna()], df[df.x.notna()], sep='\n\n')
print('\n某幾個列 缺失或非缺失的行:')
print(df[df[['x','y']].notna().all(1)], df[df[['x','y']].isna().any(1)], sep='\n\n')



數據處理中經常需要根據缺失值的大小、比例或其他特征來進行 行樣本或列特征 的刪除,pandas中提供了dropna函數來進行操作。
df.dropna(axis,how,thresh,subset,inplace)
df.fillna(value,method,axis,inplace,limit,downcast)
在關於interpolate函數的文檔描述中,列舉了許多插值法,包括了大量Scipy中的方法。比較常用且簡單的三類情況,即線性插值、最近鄰插值和索引插值。
df.interpolate(method,axis,limit,inplace,limit_direction,limit_area,downcast)
在python中,利用None表示缺失值,該元素除了等於自己本身之外,與其他任何元素不相等;
在numpy中,利用np.nan表示缺失值,該元素除了不和其他任何元素相等之外,和自身的比較結果也返回False;
在時間序列的對象中,pandas利用pd.NaT表示缺失值,它的作用和np.nan是一致的;
''' 值得注意的是: '''
import numpy as np
import pandas as pd
s1 = pd.Series([1,2,np.nan])
s2 = pd.Series([1,2,np.nan])
ls = ['s1==s2', 's1.equals(s2)']
for i in ls:
print('{}的結果是:\n{}\n'.format(i, eval(i)))
''' 運行結果: s1==s2的結果是: 0 True 1 True 2 False dtype: bool s1.equals(s2)的結果是: True '''
re.findall(r'xxxx',string),以列表形式返回;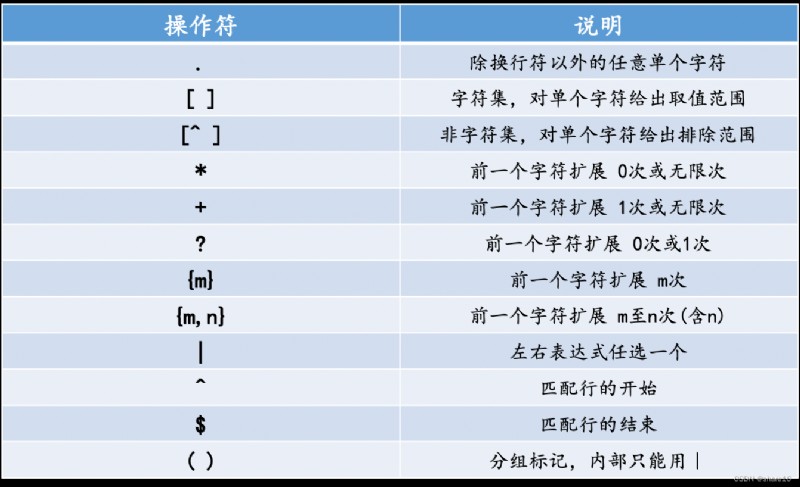
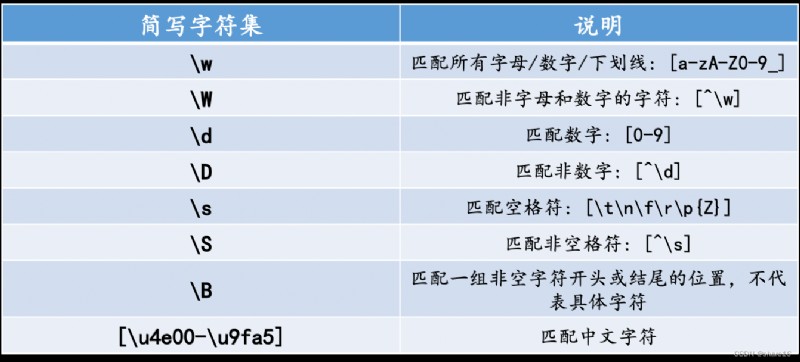
以 s = pd.Series() 為例,首先將其類型進行轉換,即s.str;其次,常見的五類操作:
s.str.split();s.str.join('-')用某個連接符把Series中的字符串列表連接起來,如果列表中出現了非字符串元素則返回NaN;s.str.cat()用於合並兩個序列,主要參數為連接符sep、連接形式join以及缺失值替代符號na_rep,其中連接形式默認為以索引為鍵的左連接;s.str.contains(pat,···)返回每個字符串是否包含正則模式(pat)的布爾序列;s.str.startswith()和s.str.endswith()返回每個字符串以給定模式為開始和結束的布爾序列,它們都不支持正則表達式;還有match/find/rfind等函數;s.str.replace();s.str.extract()、s.str.extractall()或s.str.findall();import pandas as pd
s1 = pd.Series(['上海市黃浦區方浜中路249號', '上海市寶山區密山路5號'])
s2 = s1.str
type(s1) # >> pandas.core.series.Series
type(s2) # >> pandas.core.strings.accessor.StringMethods
# 拆分
lst = ["s1[0].split('區')", "s1[0].split('[市區路]')", "s2.split('[市區路]')",\
"s2.split('[市區路]',n=1,expand=True)","s2.split('[市區路]',n=6,expand=True)"]
for i in lst:
print('{}的運行結果:\n{}\n'.format(i,eval(i)))
現有一份權力的游戲劇本數據集點此下載
問題:
1. 計算每一個Episode的台詞條數;
import pandas as pd
df = pd.read_csv('/xxx/07 劇本.csv')
df.columns = df.columns.str.strip()
df.groupby(['Season','Episode'])['Episode Title'].count()
2. 以空格為單詞的分割符,請求出單句台詞平均單詞量最多的前五個人;
df['num'] = df.Sentence.str.split().str.len()
df.groupby('Name').num.mean().sort_values(ascending=False).head()
3. 若某人的台詞中含有問號,那麼下一個說台詞的人即為回答者。若上一人台詞中含有n個問號,則認為回答者回答了n個問題,請求出回答最多問題的前五個人;
s = pd.Series(df.Sentence.values, index=df.Name.shift(-1))
s.str.count('\?').groupby('Name').sum().sort_values(ascending=False).head()
謝謝大家