大家可以關注知乎或微信公眾號的share16,我們也會同步更新此文章。
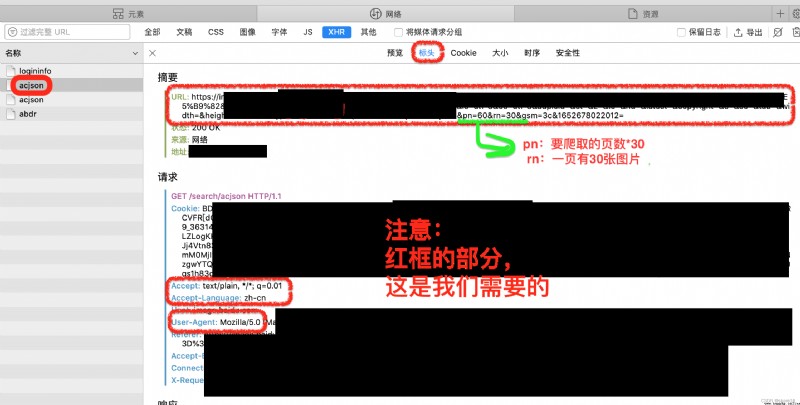
看到要爬取圖片時,第一思路就是如同爬取大學排名和小說時的方法大概一致,直接獲取網站url,就能爬到圖片。但實際上,當我們要爬取數據時,提示我們要進行網站驗證,如下;
那麼,我們該怎麼辦呢?
免費聽了一節公開課後,我學到一些知識,現在分享給大家:
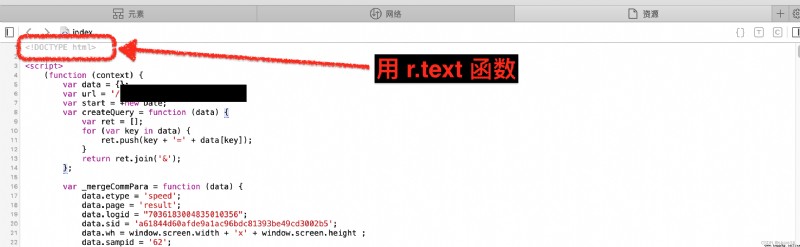
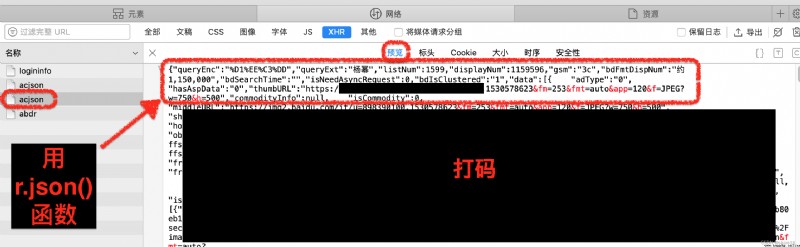
r.json():返回的是字典類型,可以通過鍵值獲取相應的值;r.text:返回的類型為字符串,無法通過鍵值獲取相應的值;# 圖片以二進制格式儲存
with open('文件名', 'wb') as f:
r.write('要插入的文件名')
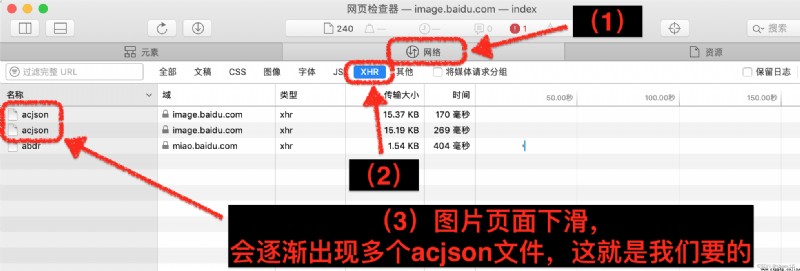
⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛
⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛
⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛
⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛*⸛⸛⸛⸛⸛⸛⸛⸛⸛⸛
源代碼:點此下載
要注意的地方:

謝謝大家