大家可以關注知乎或微信公眾號的share16,我們也會同步更新此文章。
什麼是長表?什麼是寬表?這個概念是對於某一個特征而言的。例如:一個表中把性別存儲在某一個列中,那麼它就是關於性別的長表;如果把性別作為列名,列中的元素是某一其他的相關特征數值,那麼這個表是關於性別的寬表。
下面的兩張表就分別是關於性別的長表和寬表:

顯然這兩張表從信息上是完全等價的,它們包含相同的身高統計數值,只是這些數值的呈現方式不同,而其呈現方式主要又與性別一列選擇的布局模式有關,即到底是以 long 的狀態存儲還是以 wide 的狀態存儲。因此,pandas 針對此類長寬表的變形操作設計了一些有關的變形函數。
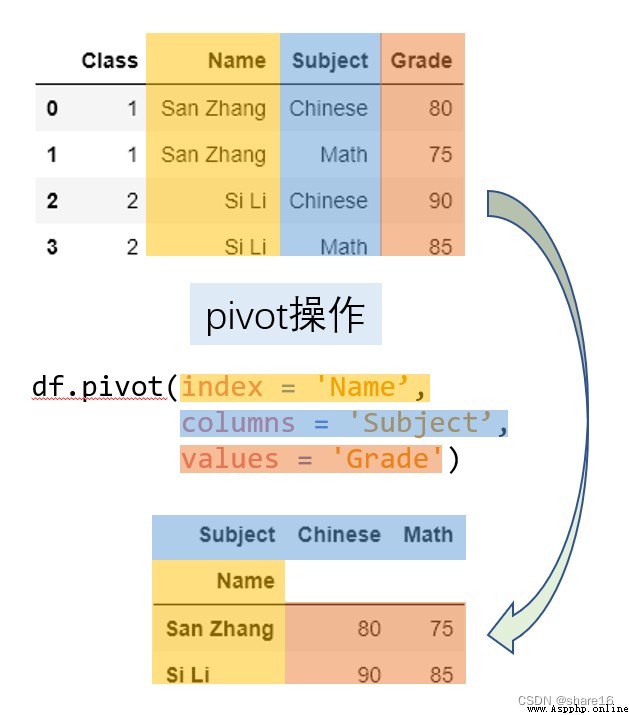
數據透視表(pivot / pivot_table):
df.pivot(index,columns,values) 等價於 pd.pivot(df,index,columns,values)
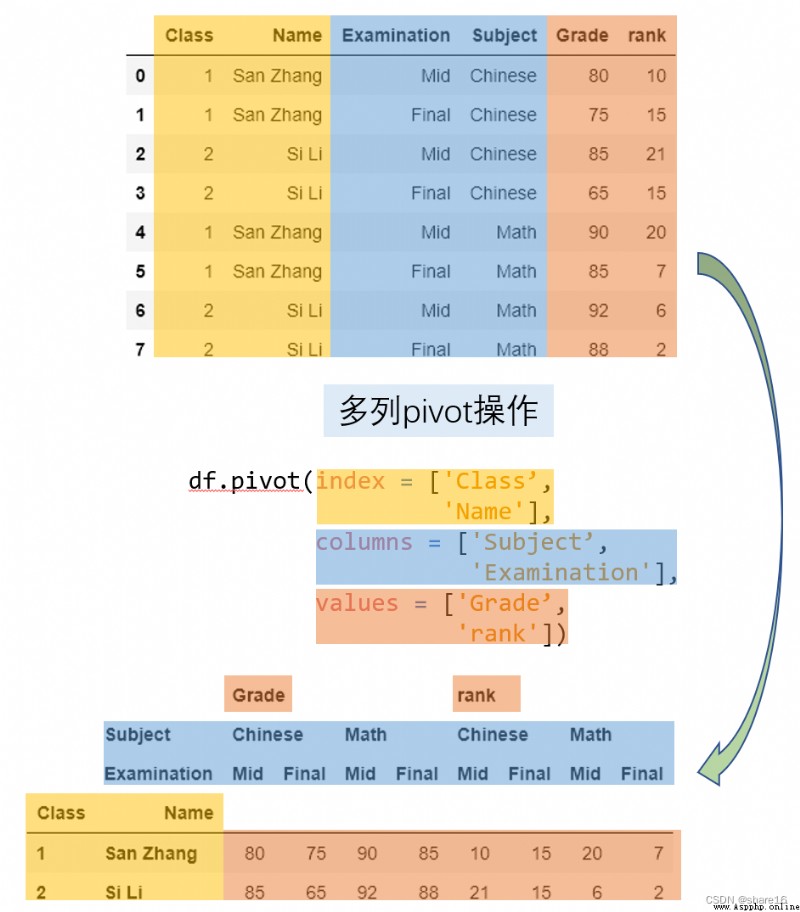
df.pivot_table(values,index,columns,aggfunc,fill_value,margins,dropna,margins_name,observed,sort) 等價於 pd.pivot_table(df,values,index,columns,aggfunc,fill_value,margins,dropna,margins_name,observed,sort)

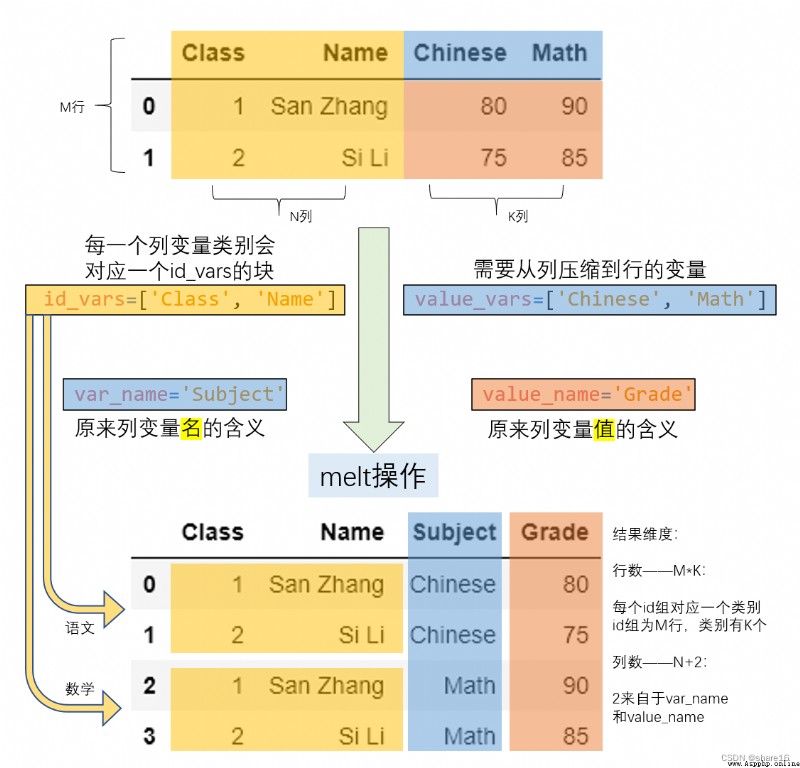
df.melt(id_vars,value_vars,var_name,value_name,col_level,ignore_index) 等價於 pd.melt(df,id_vars,value_vars,var_name,value_name,col_level,ignore_index)
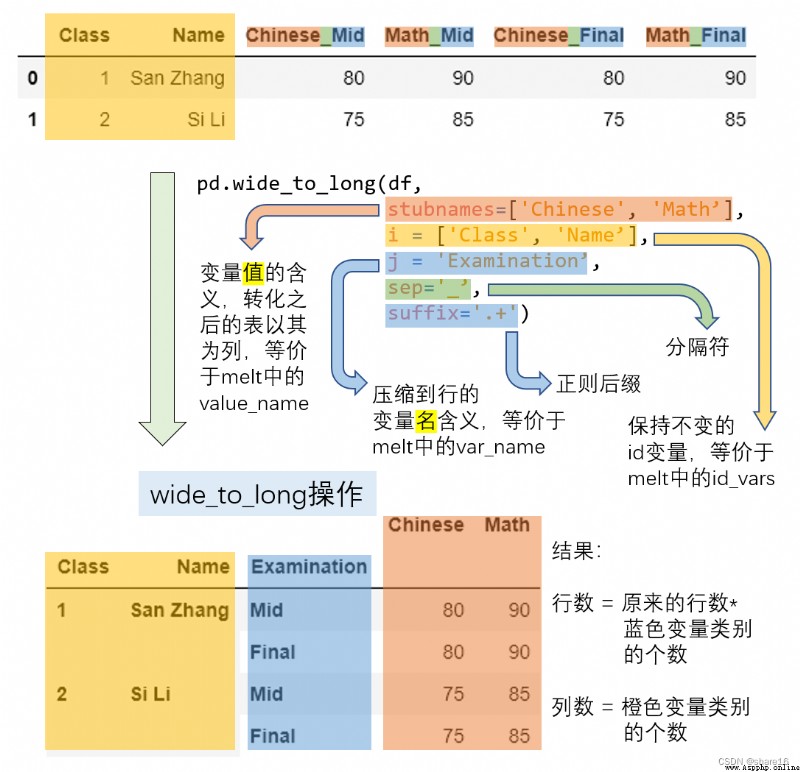
pd.wide_to_long(df,stubnames,i,j,sep,suffix)
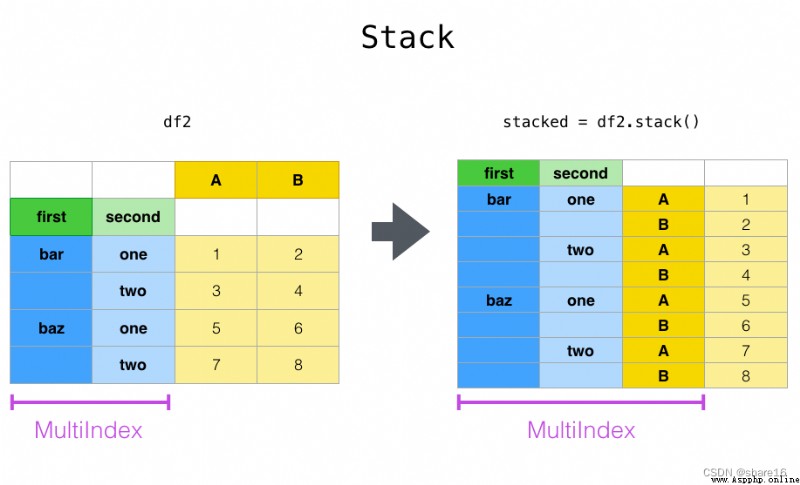
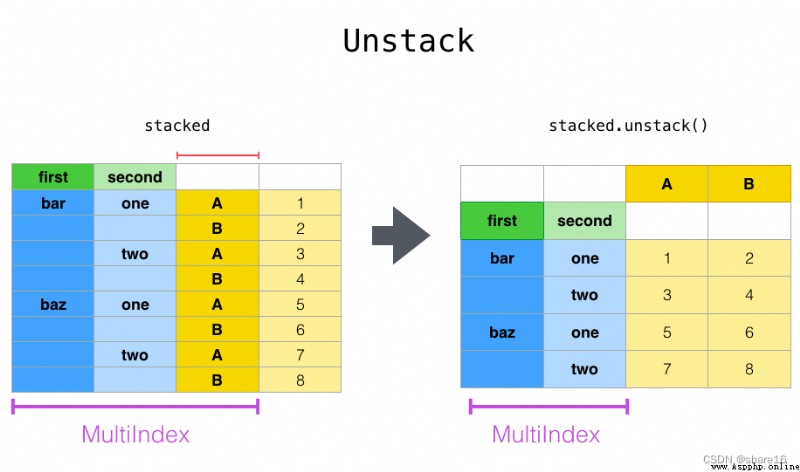
上篇文章中,我們學習到了索引內部的層交換,即 swaplevel 或 reorder_levels ;那麼,行列索引之間的交換,可用 stack 或 unstack。
df.stack(level, dropna)
df.unstack(level,fill_value)
pd.crosstab(index,columns,values,rownames,colnames,aggfunc,margins,margins_name,dropna,normalize)
df.explode(column,ignore_index)
df_ex = pd.DataFrame({
'A': [[1, 2], 'my_str', {
1, 2}, pd.Series([3, 4])], 'B': 1})
df_ex
df_ex.explode('A')
df_ex.explode('A', ignore_index=True)
pd.get_dummies(data,prefix,prefix_sep,dummy_na,columns,sparse,drop_first,dtype)
現有一份關於美國非法藥物的數據集點此下載,其中substancename、drugreports,分別代表:藥物名稱、報告數量;
問題:
1. 將數據轉為下圖的形式: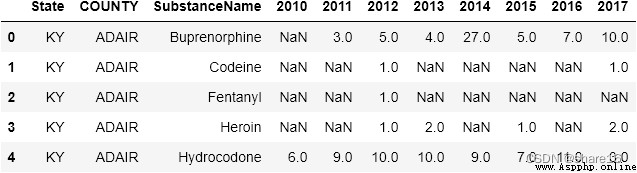
import pandas as pd
df = pd.read_csv('/Users/liuye/Desktop/Pandas數據集/05 美國非法藥物.csv').sort_values(['year','state','county','substancename'],ignore_index=True)
a = df.pivot_table(values='drugreports', index=['state', 'county', 'substancename'], columns='year').reset_index().rename_axis(columns={
'year':''})
df.pivot(index=['state', 'county', 'substancename'], columns='year', values='drugreports').reset_index().rename_axis(columns={
'year':''})
# 解析:
# df.pivot_table(···)/df.pivot(···)的結果:行索引是state、county、substancename,列索引是year中的唯一值;
# reset_index():把索引變成普通列; rename_axis():索引重命名
2. 將第1問中的結果恢復為原表;
b = a.melt(id_vars=['state', 'county', 'substancename'], var_name='year',value_name='drugreports').dropna(subset='drugreports')
c = b[df.columns].sort_values(['year','state','county','substancename'], ignore_index=True).astype({
'year':'int64', 'drugreports':'int64'})
df.equals(c)
# 解析:
# b語句:將寬表轉化成長表,刪除drugreports列的缺失值
# c語句:將b表按df的列排序
3. 按state分別統計每年的報告數量總和,其中state和year分別為列索引和行索引,要求分別使用 pivot_table 函數與 groupby+unstack 兩種不同的策略實現,並體會它們之間的聯系;
df.pivot_table(values='drugreports', index='year', columns='state', aggfunc='sum')
df.groupby(['year','state']).drugreports.sum().unstack(1)
把兩張相關的表按照某一個或某一組鍵連接起來是一種常見操作,如:學生期末考試各個科目的成績表按照姓名和班級連接成總的成績表、對企業員工的各類信息表按照 員工ID號 進行連接匯總。由此可以看出,在關系型連接中,鍵是十分重要的,往往用on參數表示。另一個重要的要素是連接的形式。
在 pandas 中的關系型連接函數 merge(值連接) 和 join(索引連接) 中提供了 how 參數來代表連接形式,分為左連接left、右連接right、內連接inner、外連接outer。
df1.merge(df2,how,on,left_on,right_on,left_index,right_index,sort,suffixes,copy, indicator,validate) 等價於 pd.merge(df1,df2,how,on,left_on,right_on,left_index,right_index,sort,suffixes,copy, indicator,validate)
df1.join(other,on,how,lsuffix,rsuffix,sort)
pd.concat(objs,axis,join,ignore_index,keys,levels,names,verify_integrity,sort,copy)
df.append(other,ignore_index,verify_integrity,sort)
df.assign(new_name,other,···)
df1.compare(df2,align_axis,keep_shape,keep_equal)
df1.combine(df2,func,fill_value,overwrite)
現有美國4月12日至11月16日的疫情報表點此下載,請將NewYork 的Confirmed、Deaths、Recovered、Active合並為一張表,索引為按如下方法生成的日期字符串序列;pd.date_range(start,end,periods,freq,tz,normalize,name,closed,inclusive,···):返回一個固定頻率的DatetimeIndex
''' 方法一 '''
import numpy as np
import pandas as pd
# 生成的日期字符串序列
a = [i.strftime('%m-%d-%Y') for i in pd.date_range('20200412', '20201116')]
url0 = '/xxx/06 美國疫情/'
# 創建一個全是NaN的數據集
df_new = pd.DataFrame(np.full((1,4), np.nan), columns=['Confirmed','Deaths','Recovered','Active'])
# for循環讀取csv文件
for i in a:
url = url0 + i + '.csv'
df = pd.read_csv(url)
df_cut = df.query(" Province_State == 'New York' ")[['Confirmed','Deaths','Recovered','Active']]
df_new = pd.concat([df_new,df_cut],ignore_index=True)
# 對最終文件進行修改
df_new = df_new.dropna()
df_new.index = a
df_new
''' 方法二 '''
date = pd.date_range('20200412', '20201116').to_series()
date = date.dt.month.astype('string').str.zfill(2) +'-'+ date.dt.day.astype('string').str.zfill(2) +'-'+ '2020'
date = date.tolist()
L = []
for d in date:
df = pd.read_csv('/Users/liuye/Desktop/data/06 美國疫情/' + d + '.csv', index_col='Province_State')
data = df.loc['New York', ['Confirmed','Deaths','Recovered','Active']]
L.append(data.to_frame().T)
res = pd.concat(L)
res.index = date
res
謝謝大家