使用pandas時,Often on a certain line、某列、Statistical calculations are performed on data that meet the conditions.
以下總結了pandasCommon methods of data selection,包括loc、iloc等方法的使用.
首先讀取數據:
df = pd.read_excel('zpxx.xlsx')
1、元素、索引、列名獲取
可以利用DataFrame的基礎屬性values、index、columns,Get the elements individually、索引、列名
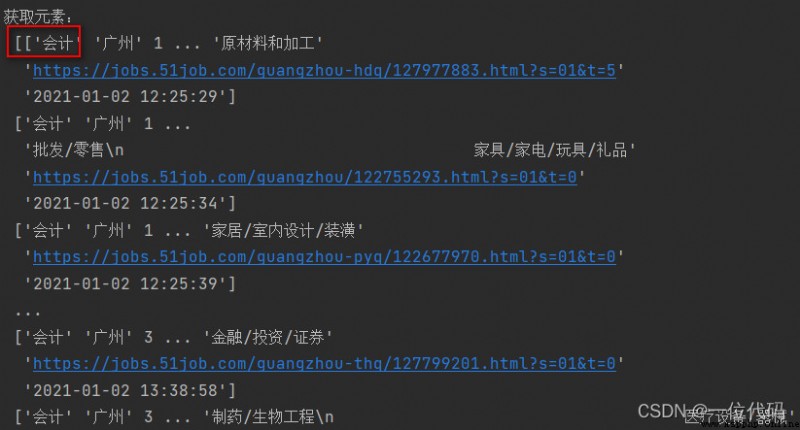
print('獲取元素:\n', df.values) # 返回二維列表
print('獲取索引:\n', df.index) # Returns the index of the row,可使用list轉換為列表格式

print('獲取列名:\n', df.columns) # 返回字段名,可使用list轉換為列表格式

2、行的選取
(1)head()和tail()方法
DataFrame提供的head()和tail()方法,Multiple rows of data can be obtained,Get continuous data from the beginning or end,Default is front or rear5行數據;The number of access lines can be entered in the method,To achieve the viewing of the target number of rows.
默認情況下:
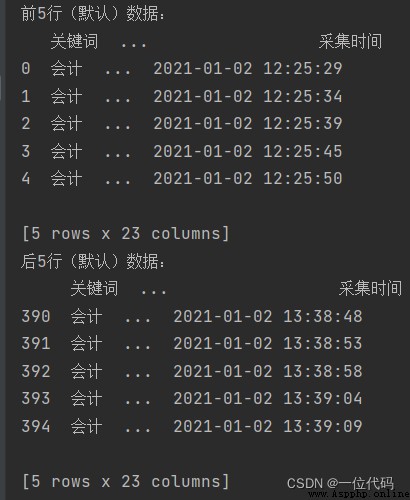
print('前5行(默認)數據:\n', df.head())
print('後5行(默認)數據:\n', df.tail())
指定查看行數:
print('指定查看前3行數據:\n', df.head(3))
Specifies the target number of rows to view for a field:
print('指定查看【關鍵詞】字段的前3行數據:\n', df['關鍵詞'].head(3))

(2)切片方式
格式:df[m:n],m、nRepresents the specified number of rows,左閉右開
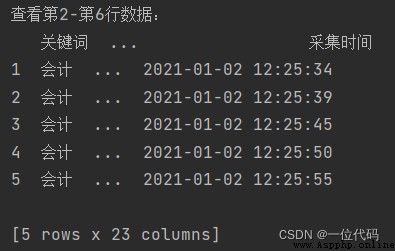
print('查看第2-第6行數據:\n', df[1:6])
3、列的選取
(1)Access a certain one as a dictionarykey的值的方式
選取某一列:df[‘列名’]
選取多列:df[[‘列名1’,’列名2’,’列名3’]]
選取某一列:
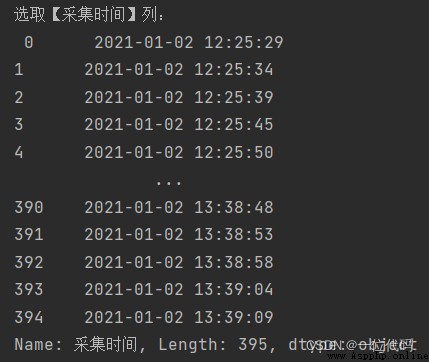
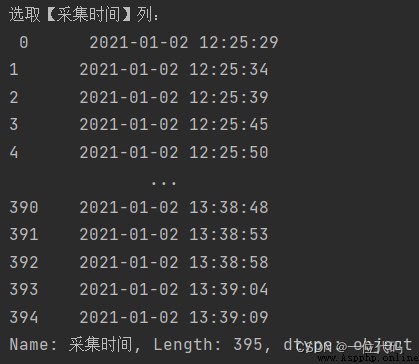
print('選取【采集時間】列:\n', df['采集時間'])
選取多列:
print('選取多列:\n', df[['關鍵詞', '采集時間']])
(2)Access property by way of access
用法:df.列名
最好不用,Confusion can easily arise between field names and internal fixed method names.
print('選取【采集時間】列:\n', df.采集時間)
4、loc和iloc行列選擇
(1)loc用法
語法:df.loc[行索引名稱或條件,列索引名稱]
loc是針對DataFrameSlicing of index names,What must be passed in is the index name,否則不能執行;And the row index cannot be empty,否則將失去意義.
第一種用法,Both row and column indexes are present:
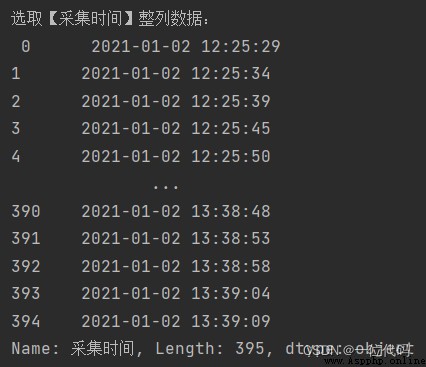
print('選取【采集時間】整列數據:\n', df.loc[:, '采集時間']) # loc用法
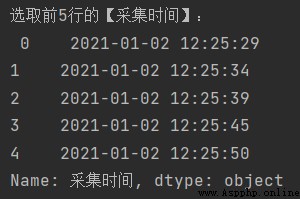
print('選取前5行的【采集時間】:\n', df.loc[:4, '采集時間']) # loc用法
注:If the row index is an interval,The front and back are closed intervals.上面“:4”Represents the row index[0:4],都為閉區間.
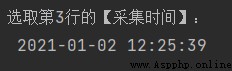
print('選取第3行的【采集時間】:\n', df.loc[2, '采集時間']) # loc用法
第二種,only row labels:
注:If the row index is an interval,The front and back are closed intervals.
print('選取第一行', df.loc[0])
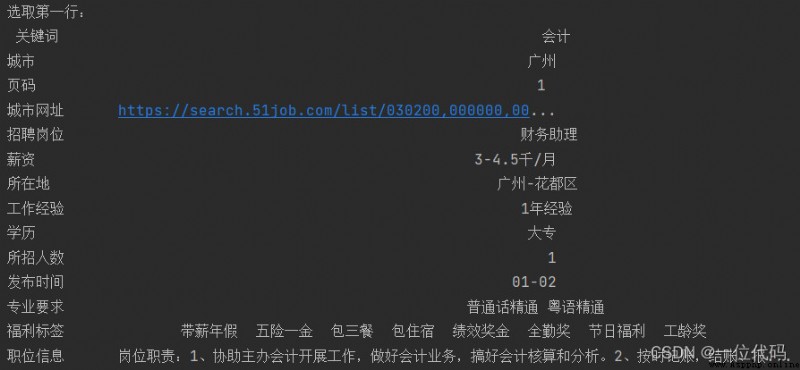
print('選取第2行,第4行:\n', df.loc[[0, 3]])
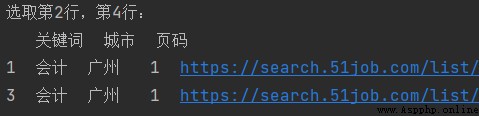
print('選取前3行:\n', df.loc[0:2])

第三種,傳入條件:
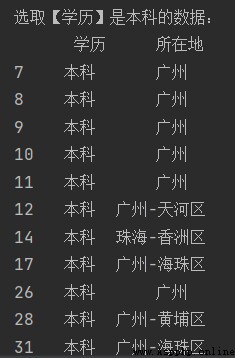
print('選取【學歷】are undergraduate data:\n', df.loc[df['學歷'] == '本科', ['學歷', '所在地']])
(2)iloc用法
語法:df.iloc[行索引位置,列索引位置]
iloc與loc不同的是,ilocData is selected based on location.Only integer data is accepted,如df.iloc[1]、df.iloc[1,2]、df[:4,3]、df[1,[1,2,5]]
print('選取【關鍵詞】字段的前4行數據:\n', df.iloc[:4, 0]) # iloc用法
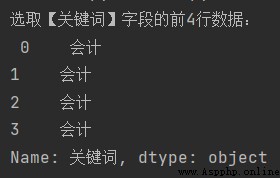
注:這裡的“:4”Indicates the position of the row[0,4),從0開始,左閉右開;“0”則表示【關鍵詞】Fields are in the first position.
總體來看,loc使用更為靈活,代碼可讀性更高.
5、ix數據選擇
ixThe method can receive both the index name when used,An index position can also be received.
語法:df.ix[行索引的名稱或位置或條件,列索引名稱或位置]
注意:When there is a partial overlap of index names and locations,ixThe default priority is to identify the name.
ix方法在pandas 1.0.0之後,已經移除,用loc和iloc方法進行替換.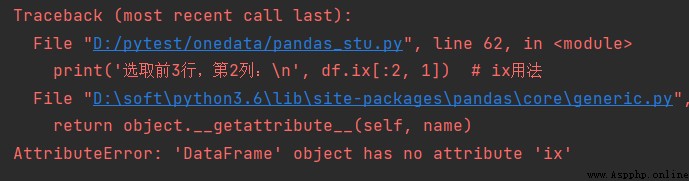
以上就是pandasCommon uses for data selection.
【微信搜索【一位代碼】即可關注我】
-end-