pandas為DataFrame格式數據添加新列的方法非常簡單,只需要新建一個列索引,再為其賦值即可。
以下總結了5種常見添加新列的方法。
首先,創建一個DataFrame結構數據,作為數據舉例。
import pandas as pd
# 創建一個DataFrame結構數據
data = {
'a': ['a0', 'a1', 'a2'],
'b': ['b0', 'b1', 'b2']}
df = pd.DataFrame(data)
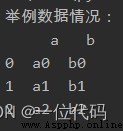
print('舉例數據情況:\n', df)
添加新列的方法,如下:
一、insert()函數
語法:
DataFrame.insert(loc, column, value,allow_duplicates = False)
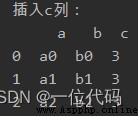
實例:插入c列
df.insert(loc=2, column='c', value=3) # 在最後一列後,插入值全為3的c列
print('插入c列:\n', df)
二、直接賦值法
語法:df[‘新列名’]=新列的值
實例:插入d列
df['d'] = [1, 2, 3] # 插入值為[1,2,3]的d列
print('插入d列:\n', df)
注:該方法不可以選擇插入新列的位置,默認為最後一列。如果新增的一列值相同,直接為其賦值一個常量即可;如果插入值不同,為列表格式,需與已有列的行數長度一致,如舉例中原來列為3行,新增列也必須有3個值。
三、reindex()函數
語法:df.reindex(columns=[原來所有的列名,新增列名],fill_value=值)
reindex()函數用法較多,此處只是針對添加新列的用法
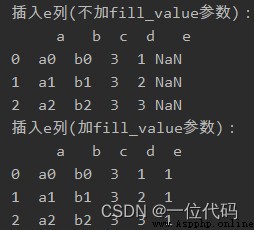
實例:插入e列
df1 = df.reindex(columns=['a', 'b', 'c', 'd', 'e']) # 不加fill_value參數,默認值為Nan
df2 = df.reindex(columns=['a', 'b', 'c', 'd', 'e'], fill_value=1) # 加入fill_value參數,填充值為1
print('插入e列(不加fill_value參數):\n', df1)
print('插入e列(加fill_value參數):\n', df2)
注:該方法需要把原有的列名和新列名都加上,如果列名過多,就比較麻煩。
四、concat()函數
原理:利用拼接的方式,添加新的一列。好處是可以同時新增多個列名。
concat()函數用法較多,此處只是針對添加新列的用法
實例:插入f列
df1 = pd.concat([df1, pd.DataFrame(columns=['f'])])
print('插入f列:\n', df1)

五、loc()函數
原理:利用loc的行列索引標簽來實現。
語法:df.loc[:,新列名]=值
實例:插入g列
df1.loc[:, 'g'] = 0
print('插入g列:\n', df1)
以上就是pandas添加新列的5種常見用法。
【微信搜索【一位代碼】即可關注我】
-end-