在本文中,我們將主要討論以下幾點:
時間序列數據的定義及其重要性.
時間序列數據的預處理步驟.
構建時間序列數據,查找缺失值,對特征進行去噪,並查找數據集中存在的異常值.
首先,讓我們先了解時間序列的定義:
時間序列是在特定時間間隔內記錄的一系列均勻分布的觀測值.
時間序列的一個例子是黃金價格.在這種情況下,我們的觀察是在固定時間間隔後一段時間內收集的黃金價格.時間單位可以是分鐘、小時、天、年等.但是任何兩個連續樣本之間的時間差是相同的.
在本文中,我們將看到在深入研究數據建模部分之前應執行的常見時間序列預處理步驟和與時間序列數據相關的常見問題.
時間序列數據預處理

時間序列數據包含大量信息,但通常是不可見的.與時間序列相關的常見問題是無序時間戳、缺失值(或時間戳)、異常值和數據中的噪聲.在所有提到的問題中,處理缺失值是最困難的一個,因為傳統的插補(一種通過替換缺失值來保留大部分信息來處理缺失數據的技術)方法在處理時間序列數據時不適用.為了分析這個預處理的實時分析,我們將使用 Kaggle 的 Air Passenger 數據集.
時間序列數據通常以非結構化格式存在,即時間戳可能混合在一起並且沒有正確排序.另外在大多數情況下,日期時間列具有默認的字符串數據類型,在對其應用任何操作之前,必須先將數據時間列轉換為日期時間數據類型.讓我們將其實現到我們的數據集中:
import pandas as pd
passenger = pd.read_csv('AirPassengers.csv')
passenger['Date'] = pd.to_datetime(passenger['Date'])
passenger.sort_values(by=['Date'], inplace=True, ascending=True)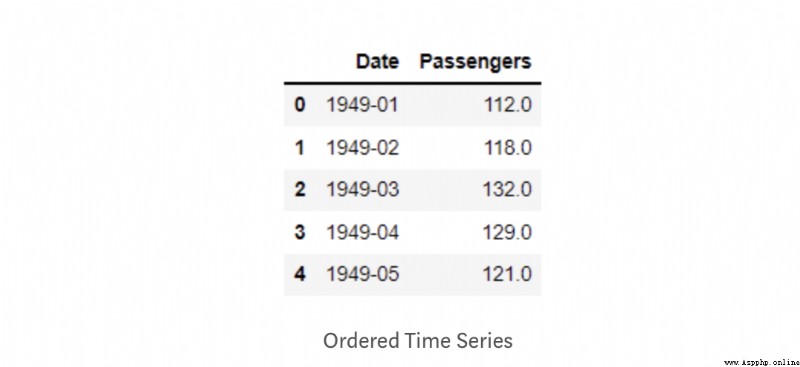
時間序列中的缺失值

處理時間序列數據中的缺失值是一項具有挑戰性的任務.傳統的插補技術不適用於時間序列數據,因為接收值的順序很重要.為了解決這個問題,我們有以下插值方法:
插值是一種常用的時間序列缺失值插補技術.它有助於使用周圍的兩個已知數據點估計丟失的數據點.這種方法簡單且最直觀.處理時序數據時可以使用以下的方法:
基於時間的插值
樣條插值
線性插值
讓我們看看我們的數據在插補之前的樣子:
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
figure(figsize=(12, 5), dpi=80, linewidth=10)
plt.plot(passenger['Date'], passenger['Passengers'])
plt.title('Air Passengers Raw Data with Missing Values')
plt.xlabel('Years', fontsize=14)
plt.ylabel('Number of Passengers', fontsize=14)
plt.show()
讓我們看看以上三個方法的結果:
passenger[‘Linear’] = passenger[‘Passengers’].interpolate(method=’linear’)
passenger[‘Spline order 3’] = passenger[‘Passengers’].interpolate(method=’spline’, order=3)
passenger[‘Time’] = passenger[‘Passengers’].interpolate(method=’time’)
methods = ['Linear', 'Spline order 3', 'Time']
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
for method in methods:
figure(figsize=(12, 4), dpi=80, linewidth=10)
plt.plot(passenger["Date"], passenger[method])
plt.title('Air Passengers Imputation using: ' + types)
plt.xlabel("Years", fontsize=14)
plt.ylabel("Number of Passengers", fontsize=14)
plt.show()
所有的方法都給出了還不錯的結果.當缺失值窗口(缺失數據的寬度)很小時,這些方法更有意義.但是如果丟失了幾個連續的值,這些方法就更難估計它們.
時間序列去噪

時間序列中的噪聲元素可能會導致嚴重問題,所以一般情況下在構建任何模型之前都會有去除噪聲的操作.最小化噪聲的過程稱為去噪.以下是一些通常用於從時間序列中去除噪聲的方法:
滾動平均值是先前觀察窗口的平均值,其中窗口是來自時間序列數據的一系列值.為每個有序窗口計算平均值.這可以極大地幫助最小化時間序列數據中的噪聲.
讓我們在谷歌股票價格上應用滾動平均值:
rolling_google = google_stock_price['Open'].rolling(20).mean()
plt.plot(google_stock_price['Date'], google_stock_price['Open'])
plt.plot(google_stock_price['Date'], rolling_google)
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.legend(['Open','Rolling Mean'])
plt.show()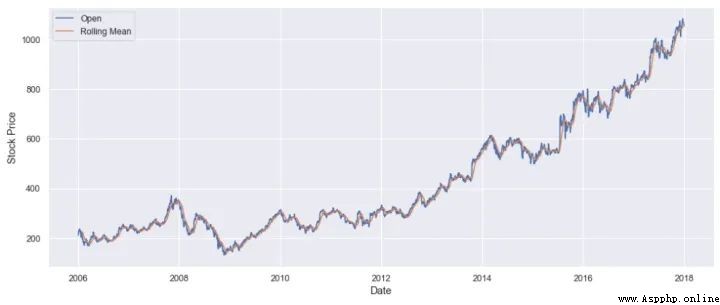
傅裡葉變換可以通過將時間序列數據轉換到頻域來幫助去除噪聲,我們可以過濾掉噪聲頻率.然後應用傅裡葉反變換得到濾波後的時間序列.我們用傅裡葉變換來計算谷歌股票價格.
denoised_google_stock_price = fft_denoiser(value, 0.001, True)
plt.plot(time, google_stock['Open'][0:300])
plt.plot(time, denoised_google_stock_price)
plt.xlabel('Date', fontsize = 13)
plt.ylabel('Stock Price', fontsize = 13)
plt.legend([‘Open’,’Denoised: 0.001'])
plt.show()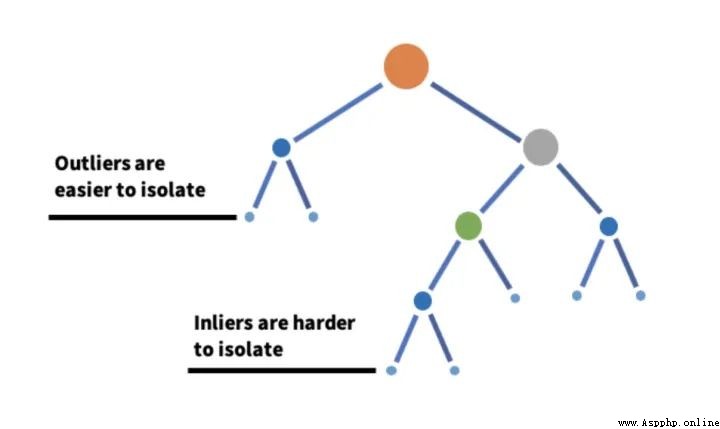
時間序列中的離群值檢測

時間序列中的離群值是指趨勢線的突然高峰或下降.導致離群值可能有多種因素.讓我們看一下檢測離群值的可用方法:
這種方法最直觀,適用於幾乎所有類型的時間序列.在這種方法中,上限和下限是根據特定的統計量度創建的,例如均值和標准差、Z 和 T 分數以及分布的百分位數.例如,我們可以將上限和下限定義為:

取整個序列的均值和標准差是不可取的,因為在這種情況下,邊界將是靜態的.邊界應該在滾動窗口的基礎上創建,就像考慮一組連續的觀察來創建邊界,然後轉移到另一個窗口.該方法是一種高效、簡單的離群點檢測方法.
顧名思義,孤立森林是一種基於決策樹的異常檢測機器學習算法.它通過使用決策樹的分區隔離給定特征集上的數據點來工作.換句話說,它從數據集中取出一個樣本,並在該樣本上構建樹,直到每個點都被隔離.為了隔離數據點,通過選擇該特征的最大值和最小值之間的分割來隨機進行分區,直到每個點都被隔離.特征的隨機分區將為異常數據點在樹中創建更短的路徑,從而將它們與其余數據區分開來.
K-means 聚類是一種無監督機器學習算法,經常用於檢測時間序列數據中的異常值.該算法查看數據集中的數據點,並將相似的數據點分組為 K 個聚類.通過測量數據點到其最近質心的距離來區分異常.如果距離大於某個阈值,則將該數據點標記為異常.K-Means 算法使用歐幾裡得距離進行比較.
可能的面試問題

如果一個人在簡歷中寫了一個關於時間序列的項目,那麼面試官可以從這個主題中提出這些可能的問題:
預處理時間序列數據的方法有哪些,與標准插補方法有何不同?
時間序列窗口是什麼意思?
你聽說過孤立森林嗎?如果是,那麼你能解釋一下它是如何工作的嗎?
什麼是傅立葉變換,我們為什麼需要它?
填充時間序列數據中缺失值的不同方法是什麼?
總結

在本文中,我們研究了一些常見的時間序列數據預處理技術.我們從排序時間序列觀察開始;然後研究了各種缺失值插補技術.因為我們處理的是一組有序的觀察結果,所以時間序列插補與傳統插補技術不同.此外,還將一些噪聲去除技術應用於谷歌股票價格數據集,最後討論了一些時間序列的異常值檢測方法.使用所有這些提到的預處理步驟可確保高質量數據,為構建復雜模型做好准備.
作者:Shashank Gupta
來源:deephub

NO.1
往期推薦
Historical articles
用Python自動化操作Excel制作報表,It's really convenient!!!
用 SQL Ten common functions for data analysis,Answers to the original interview questions!!
【Python自動化辦公】分享幾個好用到爆的模塊,建議收藏!
【干貨原創】發現了一個好用到爆的數據分析利器
長按關注- 關於數據分析與可視化 -設為星標,干貨速遞
分享、收藏、點贊、在看安排一下?