xpath的使用:
注意:提前安裝xpath插件
pip install lxml ‐i https://pypi.douban.com/simple
from lxml import etree
html_tree = etree.parse('XX.html')
html_tree = etree.HTML(response.read().decode('utf‐8')
路徑查詢
//:查找所有子孫節點,不考慮層級關系
/ :找直接子節點
謂詞查詢
//div[@id]
//div[@id="maincontent"]
屬性查詢
//@class
模糊查詢
//div[contains(@id, "he")]
//div[starts‐with(@id, "he")]
內容查詢
//div/h1/text()
邏輯運算
//div[@id="head" and @class="s_down"]
//title | //pric
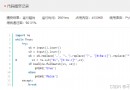
from lxml import etree
#xpath解析
# 1.本地文件
# 2.服務器響應的數據 response.read().decode('utf-8') etree.HTML
tree=etree.parse('1.xpath的基本使用.html')
#tree.xpath('xpath路徑')
#查找url下面的li
#li_list=tree.xpath('//body//li')
#查找所有id的屬性的Li標簽
#li_list=tree.xpath('//ul/li[@id]/text()')
#找到id為l1的li標簽 注意引號問題
#li_list=tree.xpath('//ul/li[@id="l1"]/text()')
#查找到id為l1標簽的class的屬性值
#li=tree.xpath('//ul/li[@id="l1"]/@class')
#查詢id中包含l的li標簽
#li_list=tree.xpath('//ul/li[contains(@id,"l")]/text()')
#查詢id的值以l開頭的li標簽
#li_list=tree.xpath('//ul/li[starts-with(@class,"c")]/text()')
#查詢id為l1和class為c1
li_list=tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
#判斷列表的長度
print(li_list)
print(len(li_list))